AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
もっともらしい文脈で、まったくの嘘をつく。このAI特有の挙動は、クリエイティブな用途では「創造性」として重宝されますが、正確性が命である企業のナレッジ検索や業務支援においては、看過できないリスクとなります。社内システム管理を担う情シス部門や、全社改革を背負うDX担当者にとって、この「AIの嘘」をいかに制御し、実運用に耐えうるレベルまで落とし込むかは喫緊の課題です。
本記事では、社内データを活用する「RAG(Retrieval-Augmented Generation)」システムにおいて、なぜハルシネーションが起きるのかという根本原因から、それを技術的にどう抑止するか、そして技術で防ぎきれない部分をどう運用でカバーするかまでを解説します。
![]() Shinnosuke Yamamoto -読み終わるまで7分
Shinnosuke Yamamoto -読み終わるまで7分

DX担当者を悩ませる「もっともらしい嘘」
AIへの期待と現実
DX推進の加速とともに、経営層からは「ChatGPTのようなAIを導入すれば、業務効率が劇的に上がるはずだ」という強いプレッシャーがかかることが増えています。初期のデモ画面では、AIは流暢な日本語で回答を生成し、一見すると完璧なソリューションに見えます。
しかし、いざ自社のマニュアルや規定集を読み込ませてみると、現場からは次のようなフィードバックが寄せられることになります。
「就業規則について聞いたら、存在しない手当の申請方法を教えられた」
「製品Aの仕様について聞いているのに、類似製品Bのスペックが混ざっている」
これこそがハルシネーションです。AIは悪意を持って嘘をついているわけではありません。確率的に「次に来る可能性が高い単語」をつなげているに過ぎないため、文脈として自然であれば、事実と異なる内容でも平然と出力してしまうのです。
ハルシネーションのリスク
この問題が深刻なのは、AIの回答が「明らかに間違っている」のではなく、「一見すると非常に論理的で正しいように見える」点にあります。多忙な社員がAIの回答を鵜呑みにし、裏取りをせずにメール返信や資料作成を行えば、誤情報は瞬く間に組織全体へ、最悪の場合は顧客へと拡散します。
DX担当者にとって、ハルシネーション対策は単なる「精度向上」のタスクではありません。「誤情報がビジネスプロセスに紛れ込み、意思決定を歪めるリスク」を管理する、リスクマネジメントそのものなのです。
多くの企業が直面する「RAGの沼」
RAG(検索拡張生成)は、社内データベースから関連情報を検索し、それをLLMに「参考資料」として渡すことで、事実に基づいた回答を生成させる仕組みです。理論上は、参照データに答えが書いてあれば、AIは正しく答えられるはずです。
しかし、現実はそう単純ではありません。多くの企業がPoC(概念実証)を実施していますが、回答精度が60〜70%程度で頭打ちになり、「これでは業務に使えない」とプロジェクトが凍結されるケースが散見されます。いわゆる「RAGの沼」です。
精度の壁にぶつかる原因の多くは、「AIモデルの性能」ではなく、「読み込ませるデータの質」と「不十分な要件定義」にあります。 「SharePointに入っているファイルを全部入れればいい」 「PDFをそのままアップロードすればAIが読んでくれる」 といった安易なデータ連携は、大抵のケースにおいて失敗します。情シス担当者が普段扱っている構造化データ(データベースやCSV)とは異なり、RAGが扱うのは非構造化データ(自然言語)です。ここには表記ゆれ、レイアウトの崩れ、古いバージョンの文書など、AIを混乱させるノイズが大量に含まれています。
この「データの壁」を認識せず、最新のLLMモデルさえ導入すれば解決すると考えてしまうことが、RAG導入失敗の典型的なパターンです。
-
▼RAGについてもっと詳しく知りたい
⇒ 検索拡張生成(RAG:Retrieval Augmented Generation)|用語集
なぜRAGでもハルシネーションは起きるのか?
RAG環境下でのハルシネーションは、ブラックボックスの中で起きる魔法の失敗ではありません。論理的に分解すれば、主に「検索(Retrieval)」と「生成(Generation)」のどちらか、あるいは両方のプロセスでエラーが発生しています。
検索の失敗:そもそも正しい社内ドキュメントを見つけられていない
RAGにおける最大のボトルネックは、実は生成AIではなく検索部分にあります。「Garbage In, Garbage Out:ゴミ(=質の悪いデータ)を入れれば、ゴミ(=ハルシネーション)が出てくる」とも呼ばれる現象です。
- ノイズの混入:古い規定書(2019年版)と新しい規定書(2025年版)が同じフォルダに混在している場合、検索エンジンが誤って古い方を拾ってしまうことがあります。AIは渡された情報が「古い」とは知らず、それを正解として回答します。
- ファイル名や構造の問題:「重要資料.pdf」のような意味のないファイル名や、中身がスキャン画像のみでテキスト情報を持たないPDFなどは、検索の網にかかりません。
- チャンク分割の失敗:文章の区切り方が不適切なために、質問の回答となる核心部分が途切れてしまい、AIに不完全な情報が渡るケースも多発します。
これらは「AIが嘘をついた」のではなく、「AIに嘘のカンペ(参考資料)が渡された」状態です。これを防ぐには、システム側の改修よりも、社内の文書管理ルールの見直しが必要になります。
生成の失敗:情報はあるが、LLMが文脈を読み違えたり、余計な知識を混ぜたりする
正しいドキュメントが検索できたとしても、LLMがそれを正しく扱えるとは限りません。
- 文脈の読み違え(Lost in the Middle):参照すべきドキュメントが長すぎたり、複数の相反する情報が渡されたりした場合、LLMが重要情報を見落とす現象です。特にプロンプトの中間にある情報は無視されやすい傾向があると言われています。
- 学習データへの回帰:社内用語(例:プロジェクトX)が、世間一般の用語(例:X社)と同じ名前である場合、AIは社内ドキュメントの内容よりも、自身が事前学習で得た「世間一般の知識」を優先して回答してしまうことがあります。これが「余計な知識を混ぜる」現象です。
「AIが悪い」ではなく「データと検索の質」に原因がある
ハルシネーション対策を議論する際、「どのLLM(GPT、Claude、Gemini等)を使うか」に終始しがちですが、実務においてはモデルの差よりも「データパイプラインの質」が重要です。前述した 「ゴミ(質の悪いデータ)を入れれば、ゴミ(ハルシネーション)が出てくる」というデータ処理の大原則は、AI時代においても変わりません。原因をAIの不可解な挙動に求めるのではなく、データフローのどこに詰まりがあるかをエンジニアリング視点で特定することが、解決への第一歩です。
技術的アプローチ:精度向上のための「3つの防壁」
ハルシネーションを技術的に封じ込めるには、「データ前処理」「検索」「生成」の3つのフェーズすべてに防壁を設ける多層防御のアプローチが有効です。
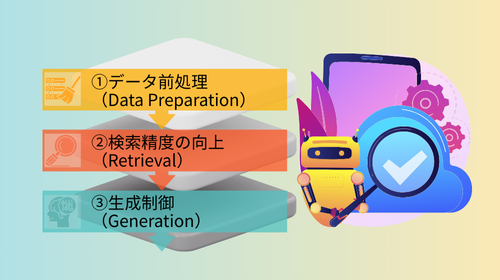
①データ前処理(Data Preparation)
RAGの勝負は、データを投入する前の「下ごしらえ」で8割決まると言っても過言ではありません。
- ドキュメントの適切な分割(チャンキング):LLMには一度に処理できるトークン数(文字数)の制限(コンテキストウィンドウ)があります。また、長文を読ませるほど精度は落ちます。そのため、文書を適切なサイズに分割(チャンキング)する必要があります。 単に「500文字ずつ切る」だけでなく、意味のまとまり(段落)ごとに切る「セマンティックチャンキング」や、文脈が途切れないように前後の文章を重複させる「オーバーラップ」の設定が重要です。
- メタデータ付与:本文検索だけに頼ると精度が上がりません。ファイルに対して「作成年度」「部署」「文書種別(規定、マニュアル、議事録)」などのタグ(メタデータ)を付与します。 これにより、検索時に「2025年度の経理部のマニュアルの中から検索する」というフィルタリングが可能になり、同名の古いファイルや他部署の無関係なファイルを物理的に排除できます。
- OCR精度の重要性:多くの日本企業で課題となるのが、紙をスキャンしたPDFや、Excelで作られた複雑な表組みです。 一般的なOCRでは表の構造が崩れ、テキストが意味不明な羅列になることがよくあります。これをAIに読ませると大混乱の原因になります。表組み認識に強いAI-OCRを採用する、あるいはマルチモーダルLLMを使用してマークダウン形式に変換して構造を維持するなど、データの品質を高めAIが理解しやすくする工夫が必要です。
-
▼セゾンテクノロジーでは生成AIの回答精度向上のために前処理アプリケーションもご用意しています。
⇒ AIプロジェクトリーダー向け 課題解決ソリューション
②検索精度の向上(Retrieval)
次に、整備されたデータから「正解」を見つけ出す検索エンジンのチューニングです。
- ハイブリッド検索(キーワード検索×ベクトル検索):初期のRAGは、文章の意味を数値化して検索する「ベクトル検索」が主流でしたが、これには弱点があります。「型番(例:A-123とA-124)」のような完全一致が必要な検索や、社内固有の略語に弱いのです。 一方で従来の「キーワード検索」は、単語が一致しないとヒットしません(例:「PC」で検索しても「パソコン」はヒットしない)。 この両者の弱点を補うため、キーワード検索とベクトル検索を並行して行い、結果をブレンドする「ハイブリッド検索」が現在のデファクトスタンダードとなっています。
- リランク(Re-ranking)の導入:検索で見つかった上位20件程度の文書に対し、AIを使って改めて「本当に質問と関連しているか?」を厳密に採点し直し、並べ替える処理を「リランク」と呼びます。 検索エンジンは「速度」を重視するため精度が粗い場合がありますが、リランク処理を挟むことで、計算コストは若干増えるものの、最終的にLLMに渡す情報の純度を劇的に高めることができます。これがハルシネーション抑止に非常に大きな効果を発揮します。
③生成制御(Generation)
最後に、LLMが回答を生成する際の振る舞いをコントロールします。
- プロンプトエンジニアリング(「分からなければ分からないと答えよ」):システムプロンプト(AIへの命令書)に、「提供された情報(コンテキスト)のみに基づいて回答してください」「情報が不足している場合は、無理に回答せず『情報がありません』と答えてください」と厳格に指示します。 また、「Chain of Thought(思考の連鎖)」と呼ばれる手法を用い、いきなり回答させるのではなく、「まず参照ドキュメントの内容を整理し、その後に回答を導き出せ」と指示することで、論理飛躍による嘘を防ぐことができます。
- 引用元の明示:回答文の末尾に、参照したドキュメントのファイル名やページ数を必ず出力させる技術実装です。 「○○という規定があります(出典:就業規則2025.pdf p.12)」のように表示されれば、ユーザーはすぐに原典を確認できます。これはAIの嘘を抑制する効果とともに、ユーザーが「AIの回答を検証できる」という安心感にもつながります。
運用的アプローチ:100%を目指さない設計思想
技術的な対策を尽くしても、現在のAI技術ではハルシネーションをゼロ(0.0%)にすることは不可能です。だからこそ、情シス担当者には「100%を目指さない」、すなわち「失敗を許容し、リカバリーできる設計」が求められます。
「回答に根拠(ソース)を必ず提示させる」UI/UXの工夫
システム画面の設計(UI)も重要です。チャット画面において、AIの回答の横に、根拠となったPDFへのリンクを必ず表示させます。 そして、画面の目立つ場所に「AIは誤った回答をする可能性があります。重要な意思決定の前には必ず原文を確認してください」という免責事項(ディスクレーマー)を常時表示します。 ユーザーに「このシステムは、答えを教えてくれる先生ではなく、資料を探してくれる優秀なアシスタントである」というメンタルモデルを持たせることが、トラブル防止の鍵です。
Human-in-the-loop(最終確認は人間が行う業務フローの構築)
業務プロセスの中に、AI任せにしないフローを組み込みます。 例えば、顧客への回答メールをAIに下書きさせる場合でも、送信ボタンを押すのは必ず人間が行うようにします。これを「Human-in-the-loop(人間がループの中に入る)」と言います。 特に、契約関連や法務関連など、リスクの高い領域でRAGを利用する場合は、AIはあくまで「ドラフト作成者」に留め、最終責任者としての人間が介在するルールを業務フローとして定着させる必要があります。
さいごに
RAGの精度向上に、魔法のような「銀の弾丸」は存在しません。特効薬的な最新モデルを探すよりも、社内のファイルサーバーにあるゴミファイルを削除する、ファイル名の命名規則を統一する、古いデータをアーカイブ領域に移すといった、地道な「データ整備」こそが、最も確実なハルシネーション対策です。 情シス担当者にとって、これはAI導入プロジェクトであると同時に、長年放置されてきた社内データ資産の棚卸しと整理を行う絶好の機会でもあります。
いきなり「全社全部署への展開」や「顧客対応の完全自動化」を目指すのはリスクが高すぎます。 まずは社内ヘルプデスクや、ベテラン社員のアシスタント業務など、「使い手が情報の真偽を判断できる領域」や「間違っても修正が効く領域」からスモールスタートを切ることを推奨します。
そこで実際のハルシネーションの傾向をつかみ、検索辞書のチューニングやプロンプトの改善といった運用ナレッジ(MLOps・LLMOps)を蓄積していく。そうして徐々に適用範囲を広げていくアプローチこそが、遠回りのようでいて、信頼できる社内AI構築への最短ルートとなるはずです。

執筆者プロフィール

山本 進之介
- ・所 属:データインテグレーションコンサルティング部 Data & AI エバンジェリスト
- 入社後、データエンジニアとして大手製造業のお客様を中心にデータ基盤の設計・開発に従事。その後、データ連携の標準化や生成AI環境の導入に関する事業企画に携わる。2023年4月からはプリセールスとして、データ基盤に関わる提案およびサービス企画を行いながら、セミナーでの講演など、「データ×生成AI」領域のエバンジェリストとして活動。趣味は離島旅行と露天風呂巡り。
- (所属は掲載時のものです)
おすすめコンテンツ



データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!