「HULFT Technology Days 2023」
今年も開催しました!(Technical Day:その1)
【第18回】

2023年の11月に、3日間にわたって開催しました「HULFT Technology Days 2023」から、三日目の内容を引き続いてレポートいたします。
注目の日本発iPaaS(クラウド型データ連携プラットフォーム)が内製化とデータ活用にフィットする理由
北田 賢作
株式会社セゾンテクノロジー 開発本部 開発統括部 サービス開発部 HULFT Square開発三課 課長
弊社の北田から、DXの実現においてなぜデータ連携が重要なのかについて、およびHULFT Squareの新機能についての紹介をさせていただきました。
昨今、DX(デジタルトランスフォーメーション)に取り組もうとされている企業は多いと思います。DXとは何をするものかについていろいろ意見はありますが、データ活用がなされていて、Data Drivenな意思決定が行われているとか、データ活用により新しい取り組みが生まれるような状況は望まれているものだと思います。これらはつまり、御社ではデータ活用ができていますか?ということになります。


しかしながらデータ活用、うまく行っていないことも多いと思います。どうしてでしょうか、それはデータが社内の様々なシステムに様々な形式で散在していて、うまく活用できないからではないでしょうか。しかもクラウドサービスが出てきたのでクラウドも使われるようになった、IoTに取り組んだのでIoTのシステムのデータも活用の対象になるなど、ITが進歩するから多様な利活用が進んでカオスになっているのなら、ITが進歩する限りカオスは無くならないのでは、とのこと。
そうなると様々なシステムに散在するデータを連携してデータ活用がうまくできるようにする「データ連携基盤」を作ることが、データ活用にとって大事であり、つまりDXの実現にとっても必要だということになります。
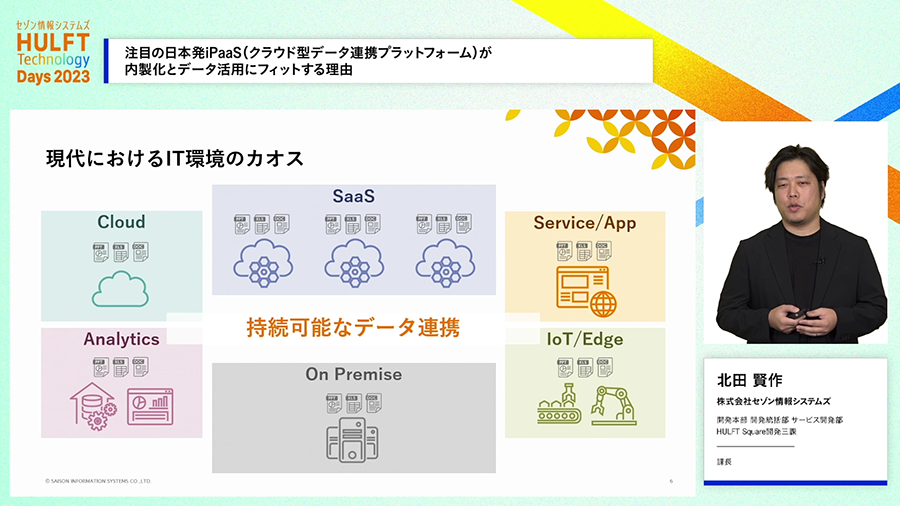
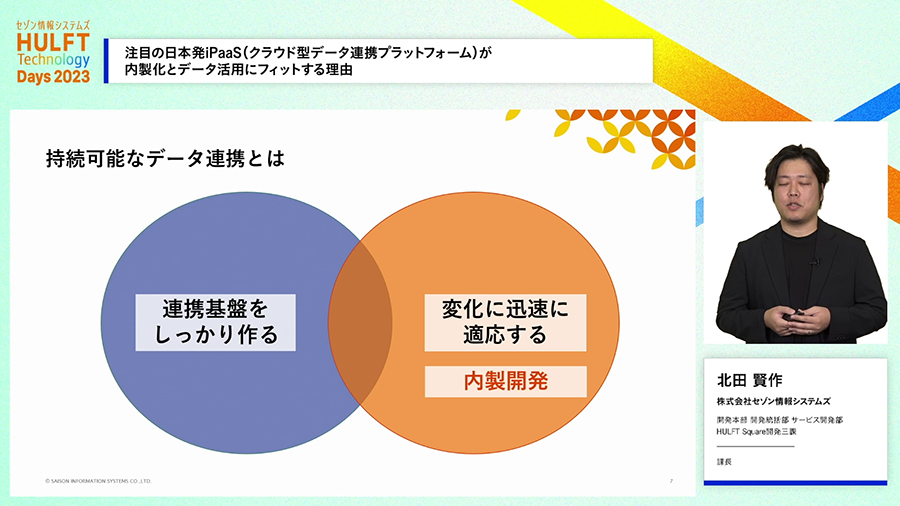
しかしITは日々進化し、ビジネス側からの要求も日々新しいものがやってきます。そうであるならば、データ連携のニーズも日々変化することになります。ただ連携基盤を作っただけでは、開発後の変化に対応できずにすぐに活躍できなくなってしまう可能性があります。
つまり変化の時代において、持続的に活躍できるデータ連携基盤であるためには、変化に迅速に適応できる必要があります。内製開発は変化への迅速な対応を実現する手段として有用であり、「内製開発で維持更新できるデータ連携基盤」を実現できれば、DXの実現を支える持続可能なデータ連携基盤が実現できる可能性があります。そしてHULFT Squareでは、データ連携基盤の内製開発を支援する機能が多くあります。
まず、クラウドサービスとして提供され、なおかつマネージドサービスなので、顧客の側でのシステム導入の手間やシステム運用の手間や人員も必要ありません。必要になったら、プランを選択して利用開始すれば導入でき、導入後もハードウェアやOSなどの基盤部分の運用の手間は必要なく、データ連携を利用することができます。


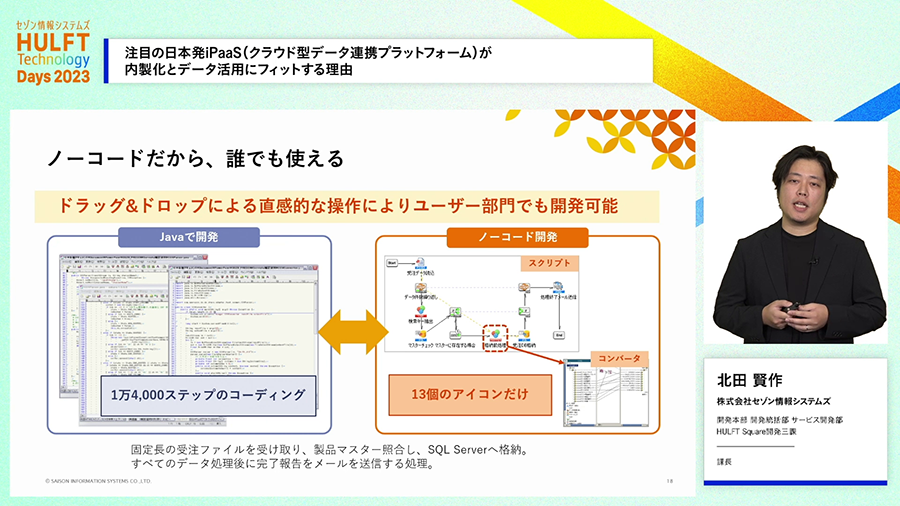
また、ノーコードで開発できるので利用のハードルが低くなっています。GUIでアイコンを配置して設定をすることでデータ連携を開発することができます。GUIでの開発ですが、内部的にはJavaのプログラムコードに変換されて実行されており、本格的開発と遜色ない処理性能でしっかりと動作します。
さらには、日本発のサービスですから日本語での手厚いサポート体制が整っています。海外製の製品を導入したために解らないことが出てきても解決できないようなこと、国内では当たり前に使われる国産製品での利用方法の情報が何もないようなことも避けられます。
さらには、HULFT Squareで開発できるように人員をトレーニングするサービス、内製化ができる体制をつくることを支援するサービス、さらには開発者が集って交流をすることや互いにわからないことを聞くことができるユーザコミュニティもあります。もちろんすべて日本語で大丈夫です。
同時に、日本以外でのサービスリリースも行われておりグローバルな利用も可能となっています。英語環境での利用にも対応、データ利用に関する規制のGDPRやCCPAに準拠し、75のタイムゾーンにも対応、弊社の海外拠点でのサポートも行っています。


また、クラウド化されずに残っている旧来のシステム、オンプレミスのシステムとの連携にしっかり対応しているところも特徴です。今風のクラウドサービスだが、今風のIT以外には対応できないみたいなことはありません。
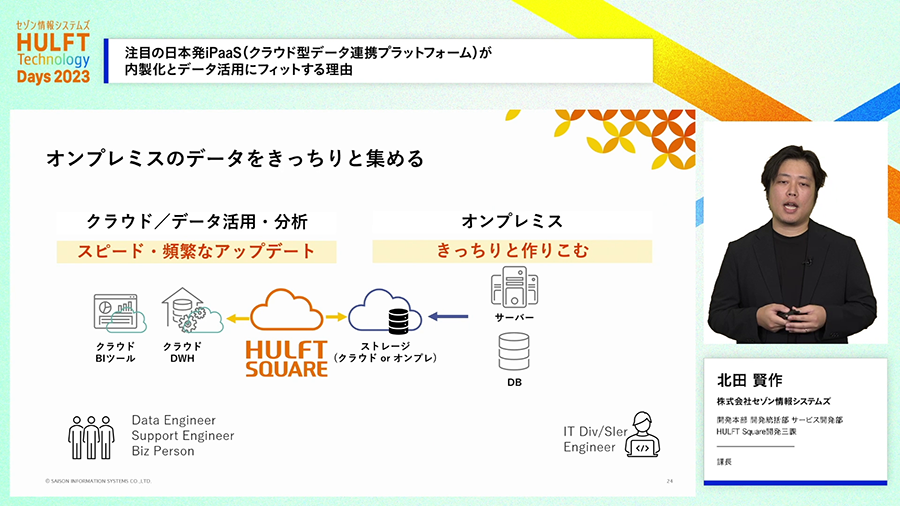
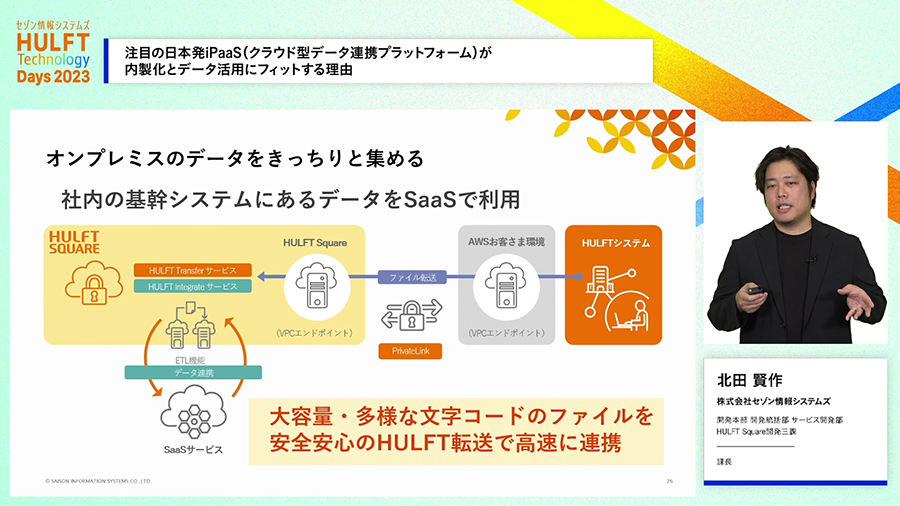
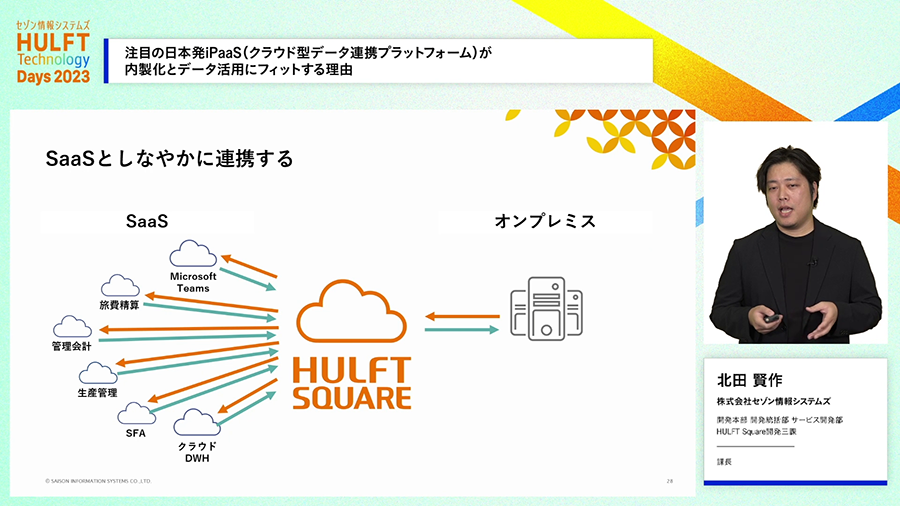
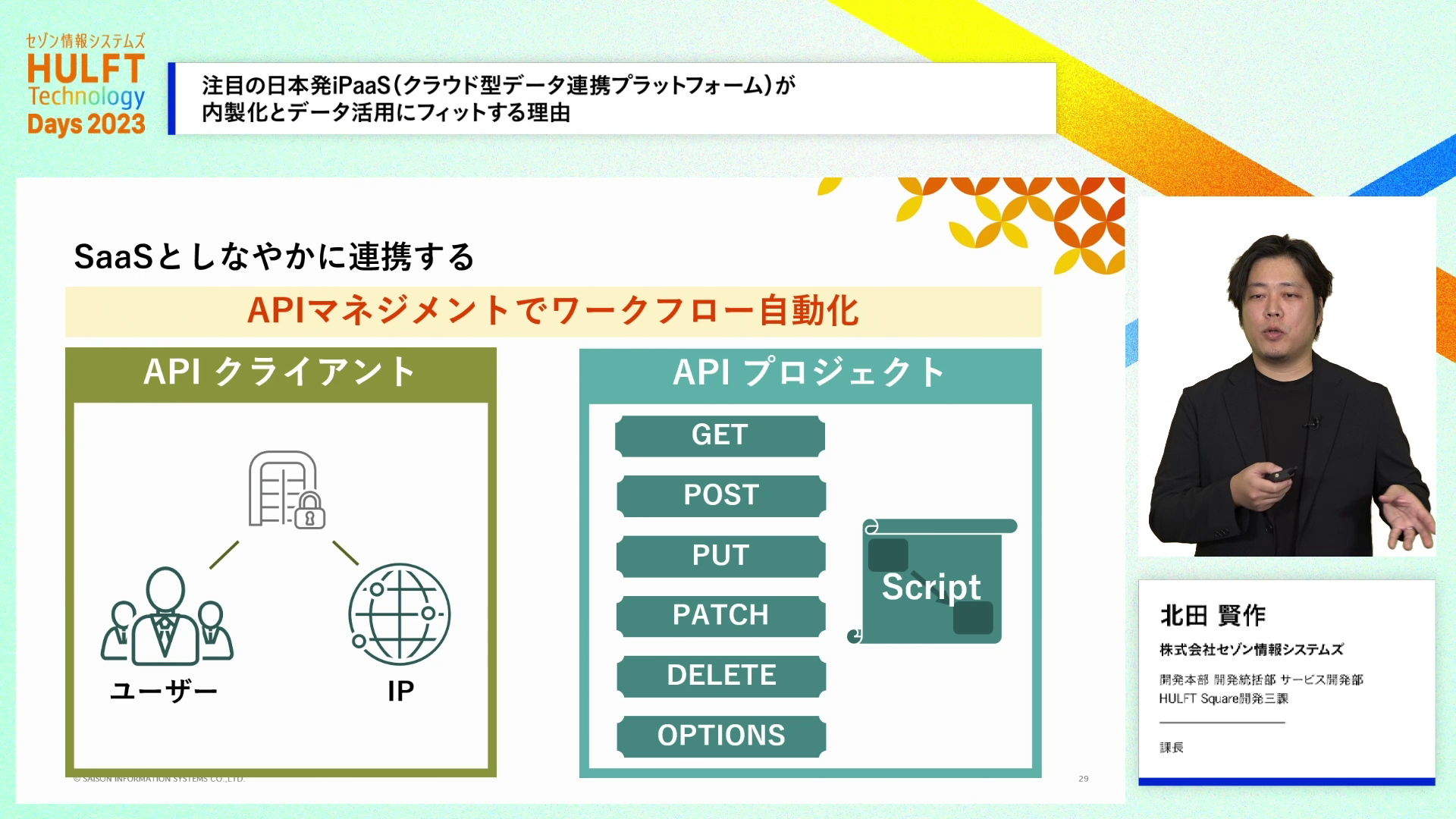
また、GUIで作った連携処理をAPIとして外部から呼び出すことも簡単にできるため、外部から呼びだされる連携処理も自分たちで作りこむことができます。
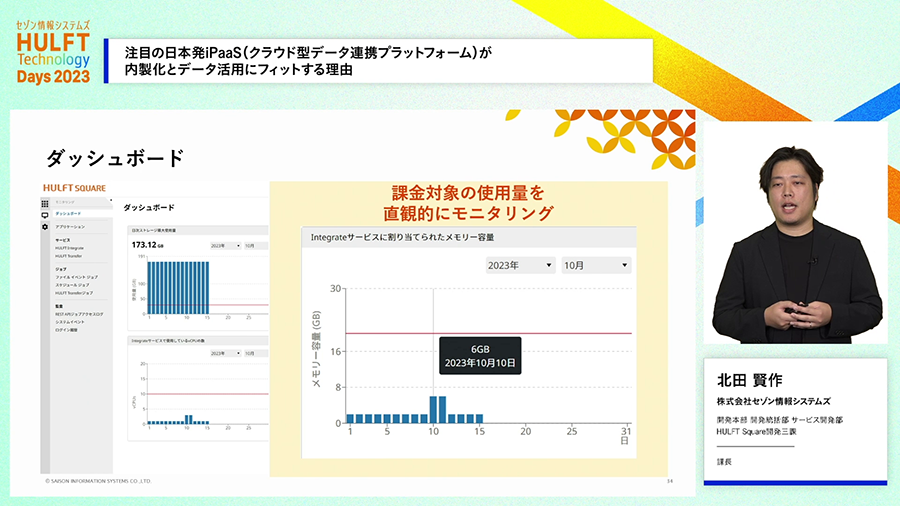
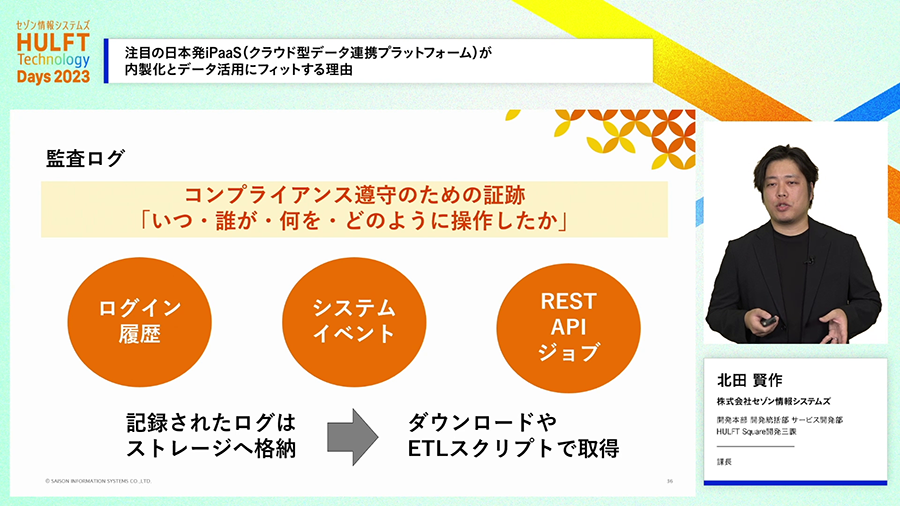
HULFT Squareは継続的に機能強化が進められていますが、その中から、重要なものを紹介します。サービス利用をスムーズにするSSO(シングルサインオン)対応の強化、運用をスムーズにするダッシュボード機能や監査ログ機能の強化、また、既に開発済みの連携スクリプトを選ぶだけで利用できるアプリケーション機能などが注目頂きたい新機能です。


ついに登場!HULFT新バージョン
大竹 純
株式会社セゾンテクノロジー 開発本部 開発統括部 プロダクト開発部 HULFT 開発一課
引き続いて、近いうちの正式リリースが予定されている「HULFT10」の紹介です。こちらは長年支持頂いているファイル連携基盤製品としてのHULFTの新製品を紹介させていただきました。
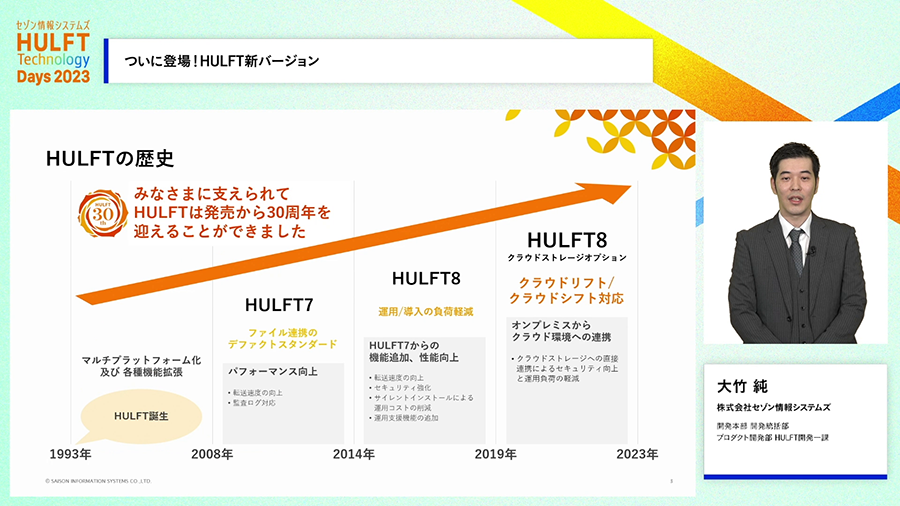
HULFTは1993年の提供開始から2023年で30年になりました。ファイル連携ミドルウェアとして日本で圧倒的なデファクトスタンダード製品となり、日本の社会を支えるITの足回りとして長年ご利用を頂いてきました。最初はメインフレーム時代からUNIX時代への移り変わりにおいて、メインフレームとUNIXを連携する手段として、その後はWindowsやLinuxなど動作する環境をどんどんと広げてきました。
あるいはそのために、HULFTは新しいものではないという印象もあるかもしれません。しかし、HULFTは時代にあわせて新機能の強化を続けてきました。今では、Amazon S3などの主要クラウドのオブジェクトストレージとの直接のファイル転送にも対応しており、クラウド環境と旧環境の連携手段として、あるいは既存ITをクラウド環境へリフトする手段としても活用いただくようになっています。

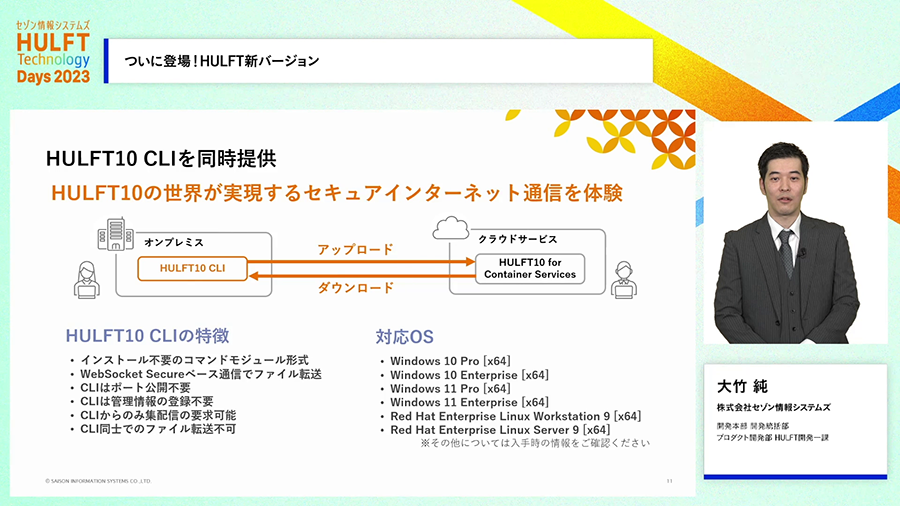
HULFT10ではさらに、クラウド時代にあわせてクラウドネイティブな製品に進化します。コンテナに対応し、コンテナオーケストレーションでの利用も想定した製品になり、インターネット回線経由での直接転送もHULFT自体の機能で自然に行えるようになります。
コンテナは昨今よく話題になるマイクロサービスを実現する技術的基盤でもあります。ハードウェアごと仮想化する仮想マシンに対し、OS上の環境だけを切り離すのでオーバーヘッドが少なく軽量かつ迅速に利用できることが特徴です。また、コンテナ環境そのものが標準化された実行環境となってきており、コンテナ対応することで多くの環境で動作させることもできます。

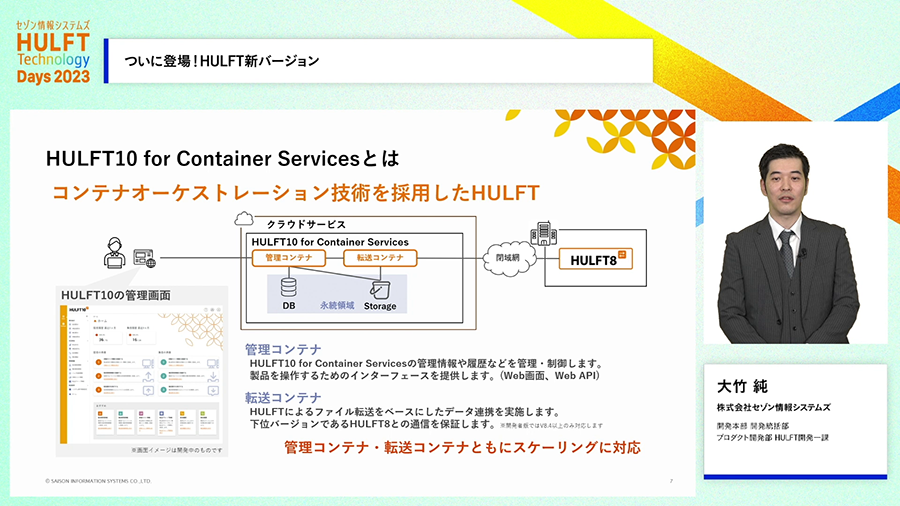
また、多数のコンテナを制御管理する技術で、昨今のマイクロサービスを実現する基盤となっているコンテナオーケストレーション技術の環境にも対応します。HULFT自身の機能についても、管理機能を担うコンテナとファイル転送機能を担うコンテナ(マイクロサービス)に分割、それぞれを冗長性確保や負荷状況にあわせてコンテナ数を自動増減するような、まさに今風の利用にも対応します。つまりマイクロサービスの世界にしっかりなじんだHULFTの登場です。
また、製品操作のインターフェースもWebUIとWebAPIと、こちらも今風のものになります。WebUIはUIデザインもまさに今風のものになっています。

コンテナ対応ではまずAWSの環境、Amazon ECSに対応する予定です。対応ができると、HULFTを購入して利用したい時にもAWSのMarketplaceで購入してすぐに利用可能になり、旧来と比べて購入して利用するまでが大幅にスピーディーになります。そのあと利用できるように環境を整える準備も、AWSの機能(AWS CloudFormation)で大半が済むようになります。
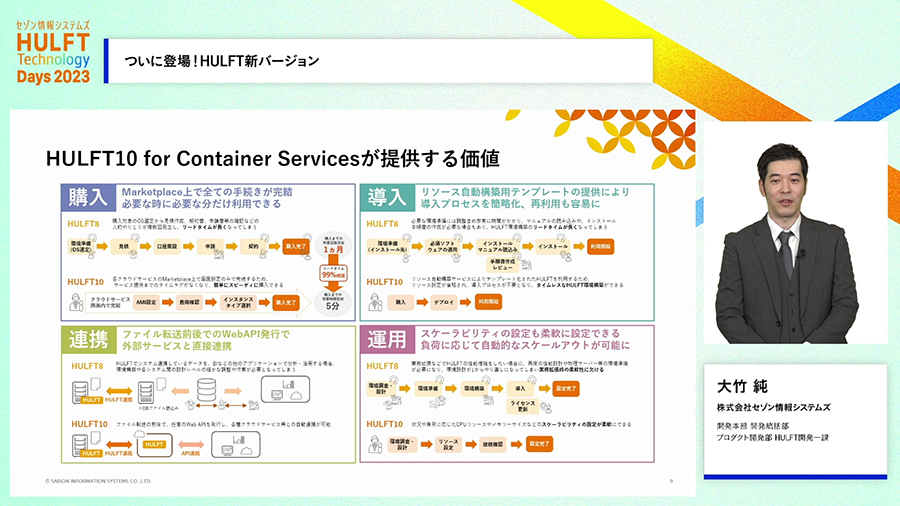
また、従来のHULFTからの継続的な機能改良も行われます。セッションではキーワードのみ紹介させていただきますが「ホスト名拡張」「タイムゾーン対応」「メタ情報(管理情報)拡張」「ファイルID拡張」「管理情報の有効期限追加」「管理情報の受付時間帯追加」「転送ファイル名拡張」「コード変換拡張」「履歴出力拡張」などの強化も行われます。

プロフェショナルノーコードツールDataSpiderの今とこれから
吉崎 智明
株式会社セゾンテクノロジー 営業本部プロダクト企画部
次はDataSpiderについてのセッションです。
昨今、DXへの取り組みが盛んになりましたが、調査によると、成果が上がっているという回答はまだ多くありません。なぜうまく行っていないのか、調査においてその課題として最も多く挙げられているのが「人材不足」になります。
DXを進めるために人材不足を解消する、そのためにはどんな方法があるでしょうか。人材採用で解決できるでしょうか?採用がうまく行っているなら人材不足だという話にはならないでしょう。外部パートナーの活用では、継続的な取り組みの支援やタイムリーな取り組みが阻害されることでしょう。そうなると期待されるのが「内部人材の活用」による取り組み、つまり社内人材のリスキリングや内製化の取り組みになります。
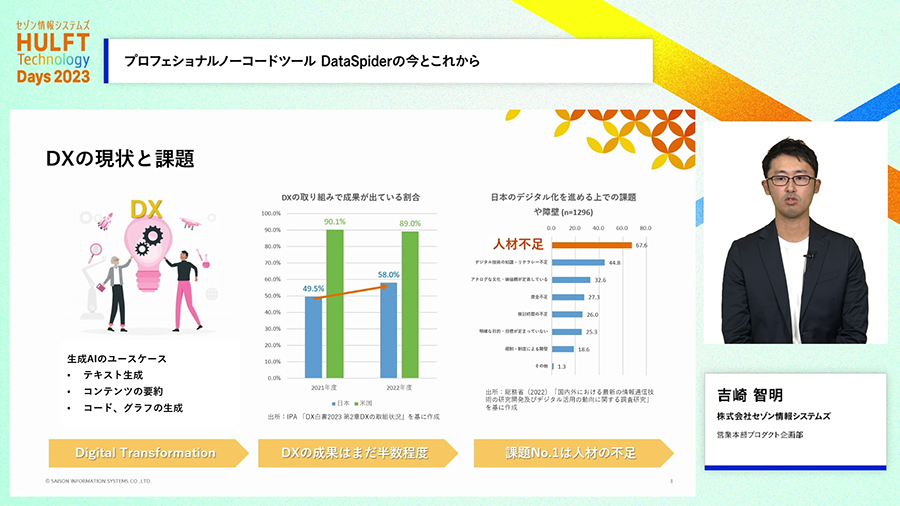
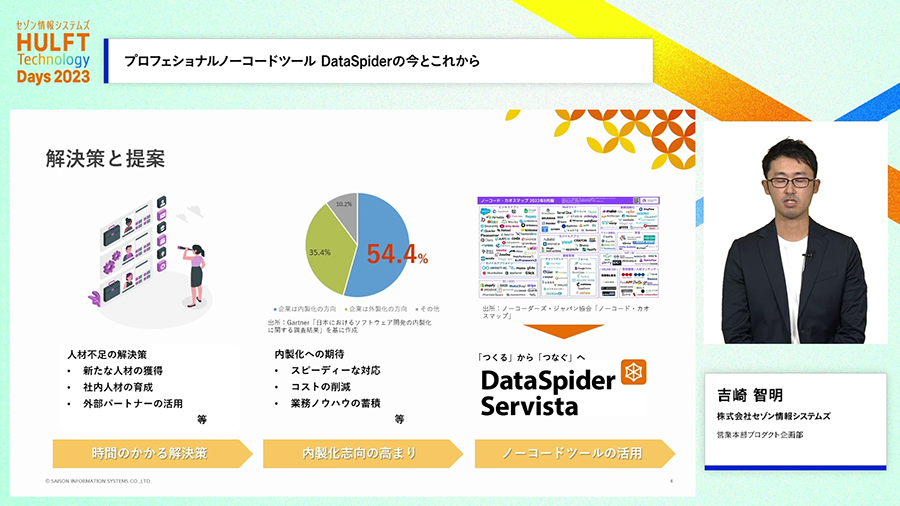
内製化は世間においても期待も寄せられています。内部人材での取り組みなら、ニーズがあった時に素早く対応できるでしょうし、既存の人材の活用ならコスト増も引き起こしにくいでしょう。そしてなにより、自分たちで取り組めば自分たちにノウハウも溜まってゆく好循環も期待できます。
では内製化は、どのようにすれば取り組めるでしょうか。弊社のDataSpiderは内製化を実現するために役に立てることが多いと考えています。
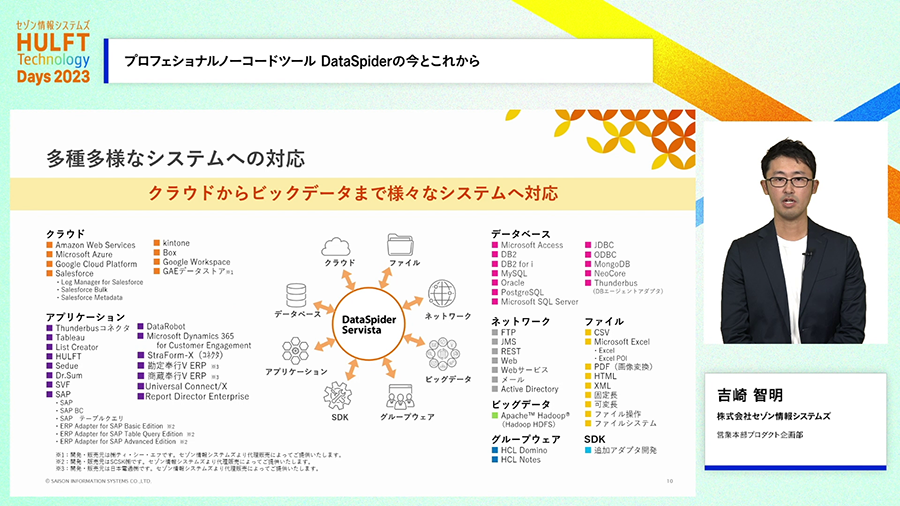
DataSpiderは、ノーコードで様々なデータやシステムの間で連携処理を実現できるツールです。多種多様な連携先に対応しており、開発から運用までデータ連携基盤に必要な機能を備えています。

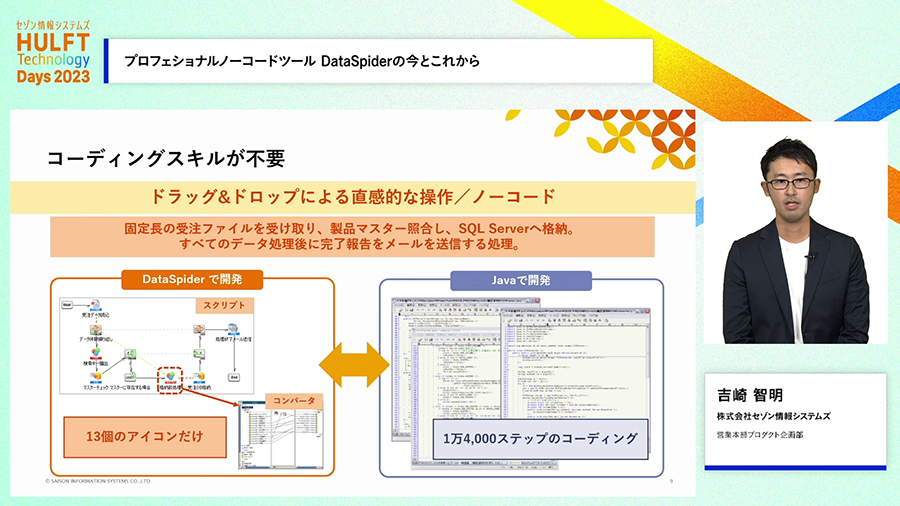
ノーコードとはどういうことでしょうか。GUI上でアイコンを配置して線でつなぎ、各種設定を行うだけで開発できるので一般的なプログラミングのようにソースコードを書く必要がありません。下記の例では帳票のファイルを受け取りマスターデータを読み取って加工するような処理をしていますが、DataSpiderならGUIでアイコンを13個配置して設定すれば開発できており、同等の処理をJavaで実装すると1万4000ステップが必要である例となっています。
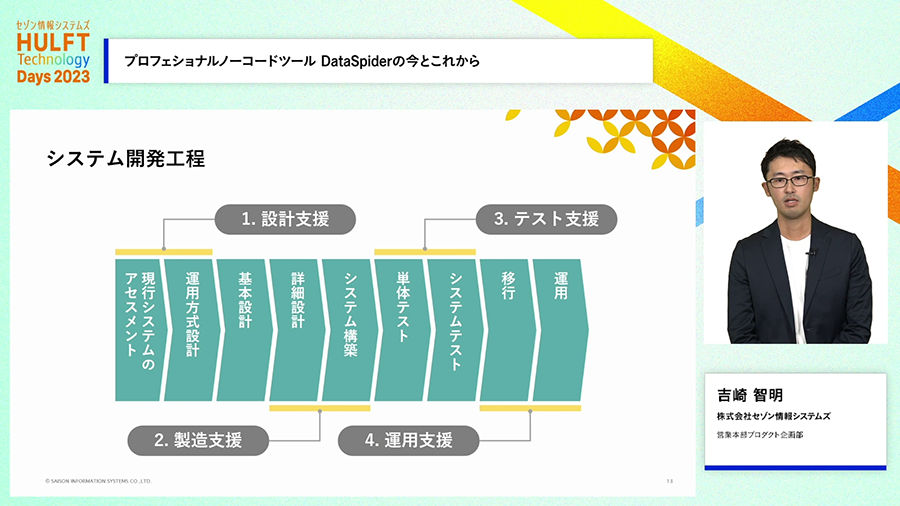
GUIだけで簡単にできる、多くの接続先に対応している、実はその程度なら世間にそう名乗っている製品は他にもあったりします。DataSpiderがそのようなプロダクトと違うのは、GUIだけで効率的に開発できる特徴を持ちながら、高い性能や安定稼働が求められる企業のシステムを支えられるような、本格的なITシステムにも向いている性能や機能を持っていること、つまりプロフェッショナルなシステムに求められる能力も併せ持っているところにあります。


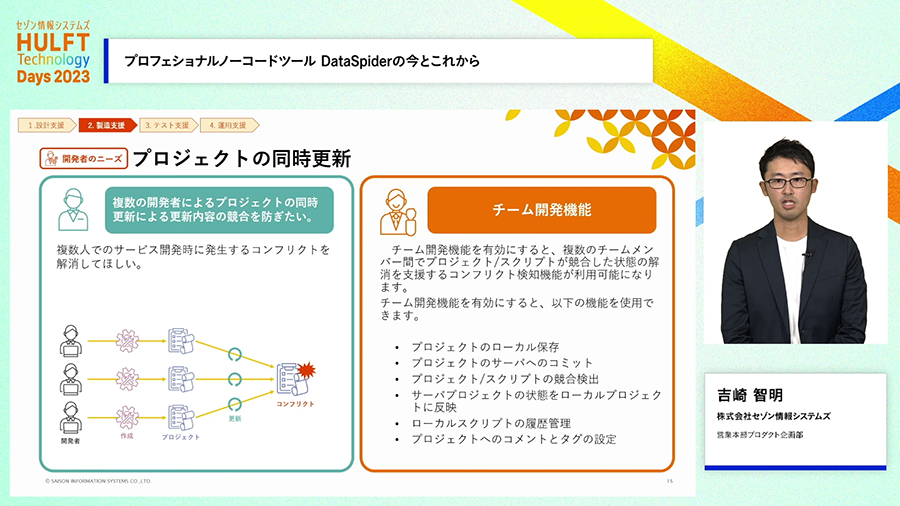
たとえば、本格的なシステム開発では多人数による開発が必要になってきます。その場合に、Aさんの書き換えとBさんの書き換えが衝突して作ったものが壊れるような事態は避けねばなりませんし、それを避けるためにAさんとBさんの同時作業を制限すると生産性が下がってしまいます。DataSpiderではチームの複数人が同時に開発作業を進めるような状況でもデータが壊れないようにする機能が備わっています。
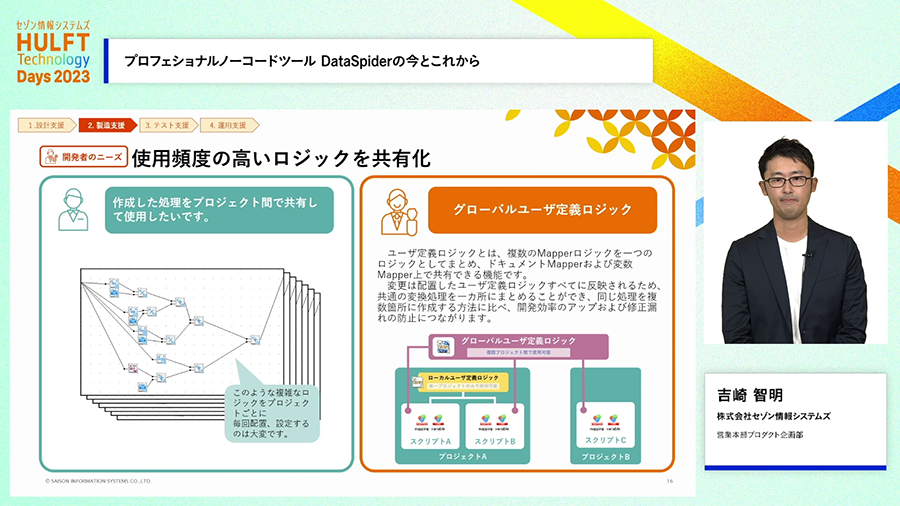
また、共通する処理を共通部品として作成して、開発プロジェクトの広範囲で共有する機能も備わっています。
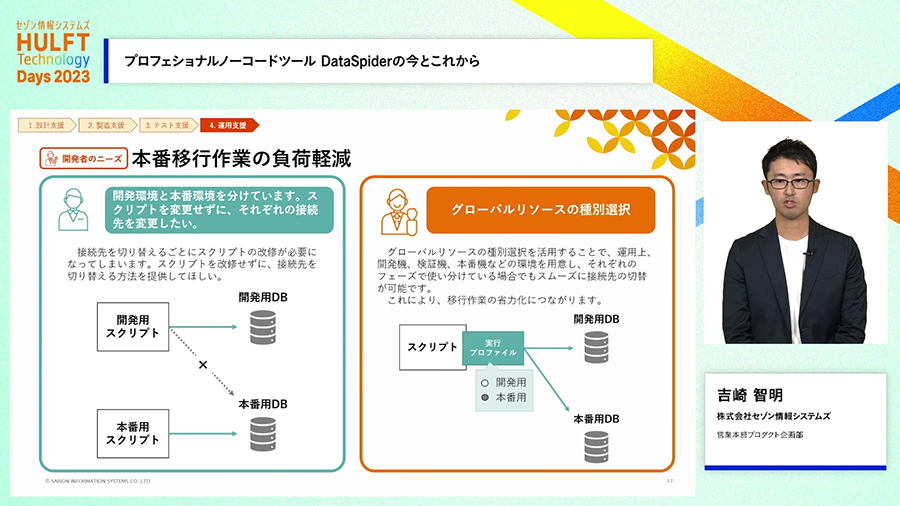
また、連携処理を試行錯誤などもしつつ「開発をする環境」と、業務を支えるために「実際に稼働している環境」は分離しておく必要があります。簡易なツールではこれら環境が分離されておらず、本番環境で動いている処理を書き換えて開発をするしかないこともあります。DataSpiderでは、開発環境は本番環境からきちんと分離されており、開発が完了してきちんと動作することを確認した連携処理を、本番環境にそのままスムーズに移行する機能も備わっています。
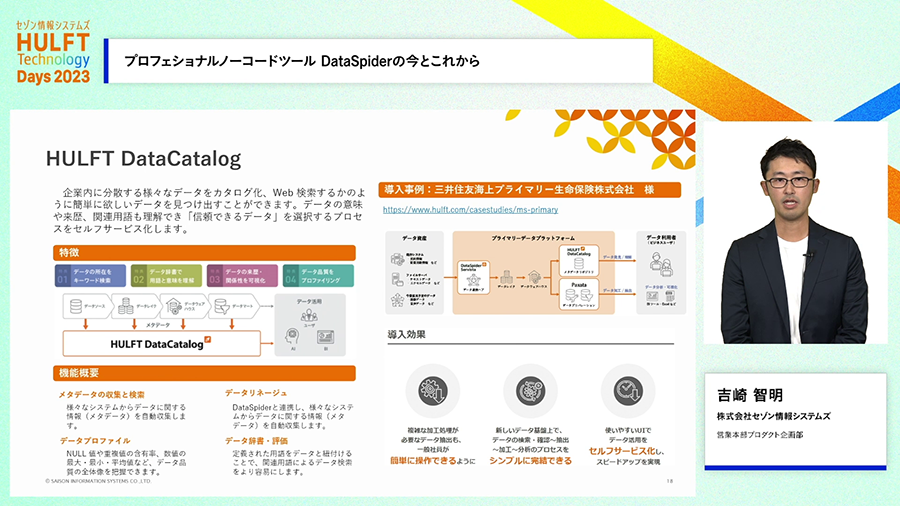
さらには、製品ファミリーのHULFT DataCatalogを合わせて導入いただくと、DataSpiderの連携処理を読み取って解読し、連携処理で参照しているデータソースの一覧や、データソースから関係する連携処理を調べることも出来るようになります。
このデータを変更したらどの処理に影響が及ぶのかとか、あるいはこの連携処理を改修したらどこのデータに影響しうるかというのは、一般的に神経を使うことで既存の連携処理を改修するときには苦労の元になりやすいのですが、HULFT DataCatalogを併用すれば影響範囲をスムーズに見える化することができます。
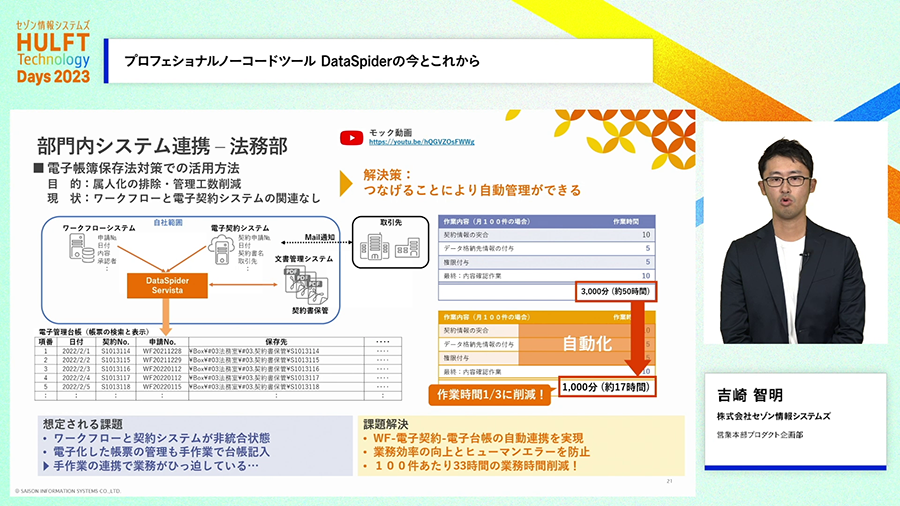
連携処理の開発がIT活用でそんなに効果があって重要なものだろうか?と思えるかもしれません。しかし、企業内でのニーズには連携すれば解決できる問題が数多くあります。以下の例は、電子帳簿法対応で、ワークフローシステムと電子署名システム、文書管理システムなどの間の手作業が発生して困っているような状況を、DataSpiderが連携して自動化した例です。
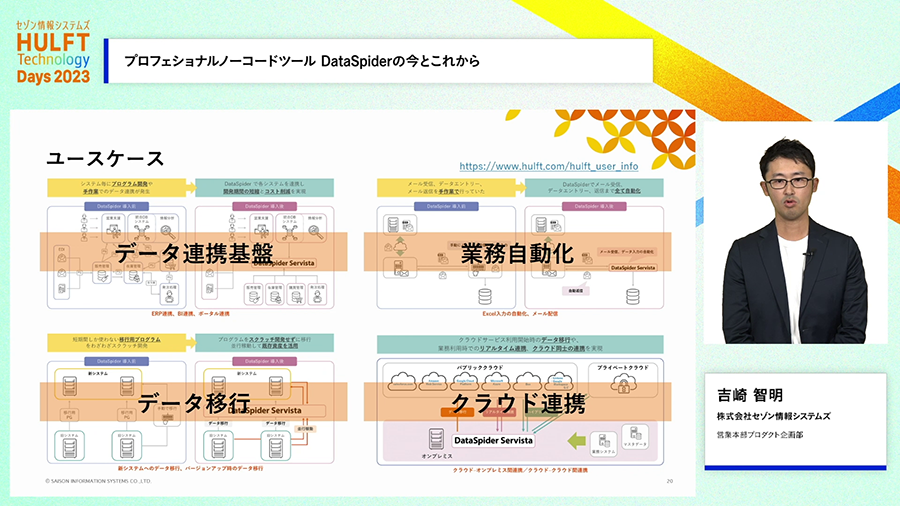
今後のDataSpiderですが、これまでに引き続いて接続アダプタの充実や機能強化、および開発環境の機能強化に取り組んでゆきます。さらに加えて、弊社のもう一つの「つなぐ」製品である、HULFT Squareと連携し、組み合わせ利用できるように機能整備を進めます。


データ連携製品同士をどうして組み合わせるのか?と思えるかもしれません。しかしクラウドサービスとして効率的に利用できるiPaaSと、オンプレミスの自社システム内で自社の思った通りにしっかり運用できるDataSpiderには多くの特性の違いがあり、両プロダクトを組み合わせて利用できるようにしようと考えています。
クラウドの利便性は理解しているがクラウドに全部のデータを出すのはちょっと、と思っているならDataSpiderを利用しつつHULFT Squareを組み合わせれば良いはずです。あるいは、HULFT Square側からオンプレミス側にあるデータやシステムへのデータ連携にもどかしさを感じているなら、HULFT SquareにDataSpiderを組み合わせればよいはずです。

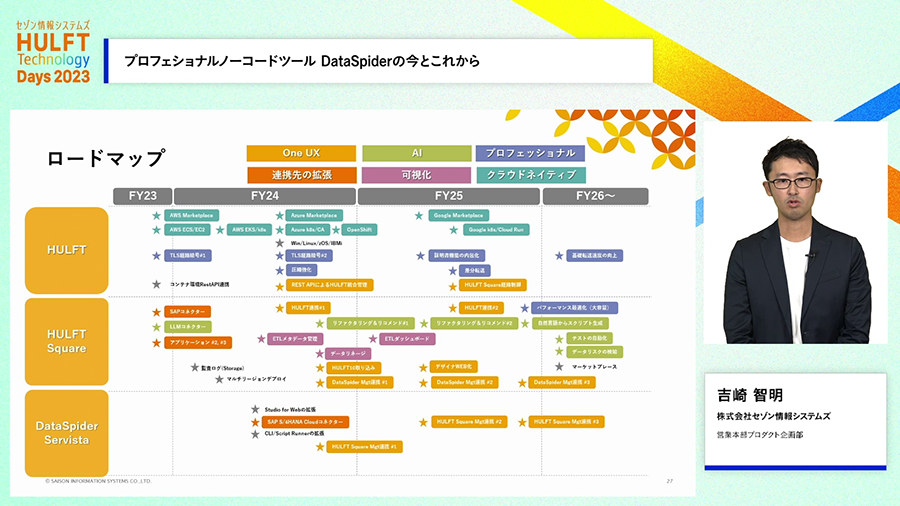
DataSpiderとHULFT Squareをうまく組み合わせて利用できる機能の整備に取り組むことのみならず、クラウドとオンプレミスに限らない様々な「Hybrid」なデータやデータ連携の利用を支援し、様々な境界を取り除いて「つなぐ」取り組みを今後は進めていきます。
HULFT SquareとAWSで始めるデータ活用の民主化
吉田 成利 氏
アマゾン ウェブ サービス ジャパン合同会社 AWSテクノロジー パートナーシップ
Data&Analyticsシニアパートナーソリューションアーキテクト
AWSのサービスと弊社HULFT Squareを組み合わせてデータ活用基盤を実現する方法について紹介を頂きました。
現在、世界に存在するデータは爆発的に増えつつあり、現存するデータの9割はなんと過去2年間に生成されたという話もあるそうです。そして、データに基づいてビジネスをしている組織、データドリブンを実現している組織は20%以上の成長を達成する可能性が8.5倍も高いという調査結果もあるようです。


データを価値に変えることが重要であると思える状況ですが、多くの企業ではデータを十分に活用することができていません。データを戦略的資源として扱うことに成功している企業はなんと26%に過ぎないとのことです。

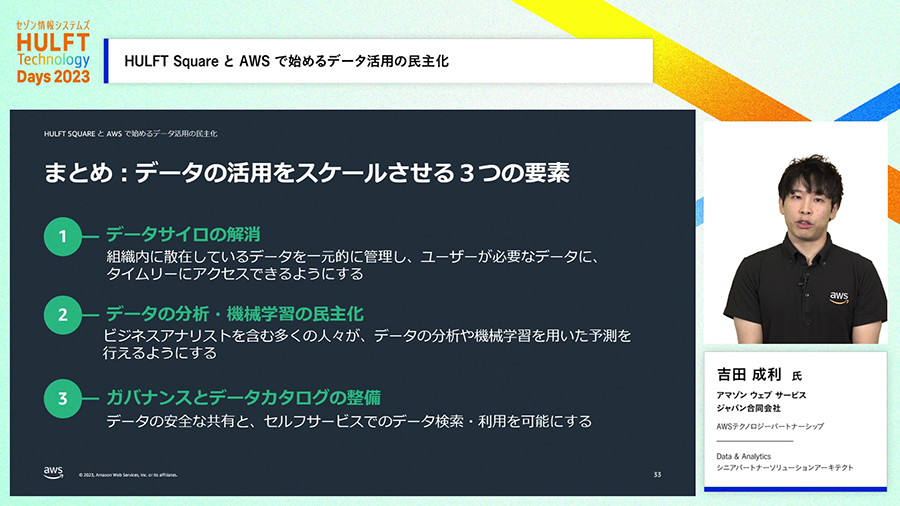
データ活用を進めようとしてデータ基盤を構築する、そのような取り組みにおいて従来は三つの典型的な問題があったとのことでした。まずは部門ごとなどにデータ活用の取り組みやデータ自体がバラバラになっており、それらの間でサイロ化が進んでしまって全社的な取り組みが出来なくなってしまう問題。そしてそのような事態を避けようとDWHなどで全社データ基盤を作るも、全社的な様々なニーズを十分に受け入れたデータ基盤にできない問題。そして、大量のデータが集められた全社データ基盤が十分な性能を出せなくなってしまう問題です。
以下、このような問題を解消し、データ活用をうまく進めるデータ基盤を構築する方法を考えます。


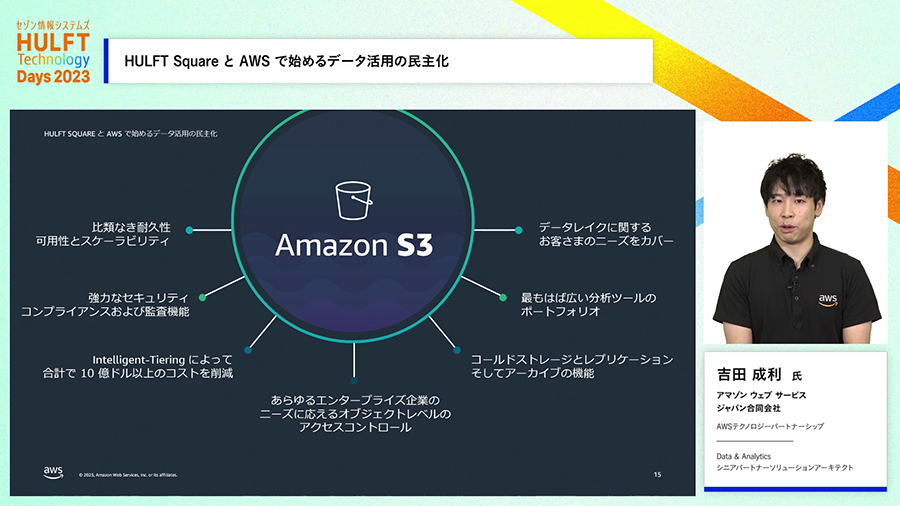
まず、様々なところからデータを受け入れる基盤を構築します。多種多様なデータソースから「HULFT Square」でデータを収集し、そのデータをデータレイクとして「Amazon S3」に投入します。
Amazon S3は様々なデータを、データフォーマットによらず、非常に大きなサイズのデータでも問題なく格納することができ、データレイク全体で巨大な容量になっても十分な処理性能を維持することができます。クラウド側の障害でデータが消えてしまわないように高度な冗長構成も取られているサービスです。さらにはコスト面でも効率性が高いサービスです。

データレイクにデータを溜めた後はどうしたらいいでしょうか。AWSのDWHであるAmazon Redshiftでデータ分析の基盤を作ることができます。
Redshiftは一般的なDWHの機能が備わっているだけでなく、AWSの様々なサービスとの連携機能も備えています。例えば、データコピーすることなくAmazon S3にデータを置いたまま分析クエリを打てる機能、外部のRDBに入っているデータと組み合わせた検索結果を得られる機能、さらにはRedshiftに対するSQLで機械学習を利用できる機能も備わっています。

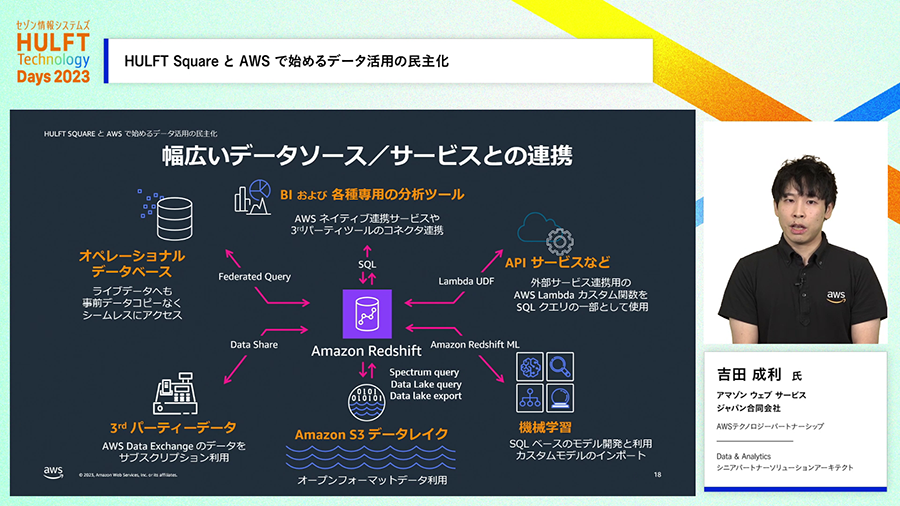
HULFT Squareを利用すると、多種多様なデータソースへの連携機能を活用して、Amazon S3やAmazon Redshiftなどのデータ基盤へのデータ連携がノーコードで実施できます。さらには、自社運用不要で小さく始められるクラウドサービスのiPaaSなので、最初から大きな予算を投じることなくスモールスタートで使い始めることもできます。
ノーコードで実現できることは大変重要なことで、データを活用したいユーザ部門が(社内IT部門や外部パートナーに依頼することなく)自らセルフサービスでデータ連携を実施して、データレイクやDWHでデータ活用ができることになります。


HULFT SquareではAWSの様々な機能が併せて利用できることも紹介いただきました。
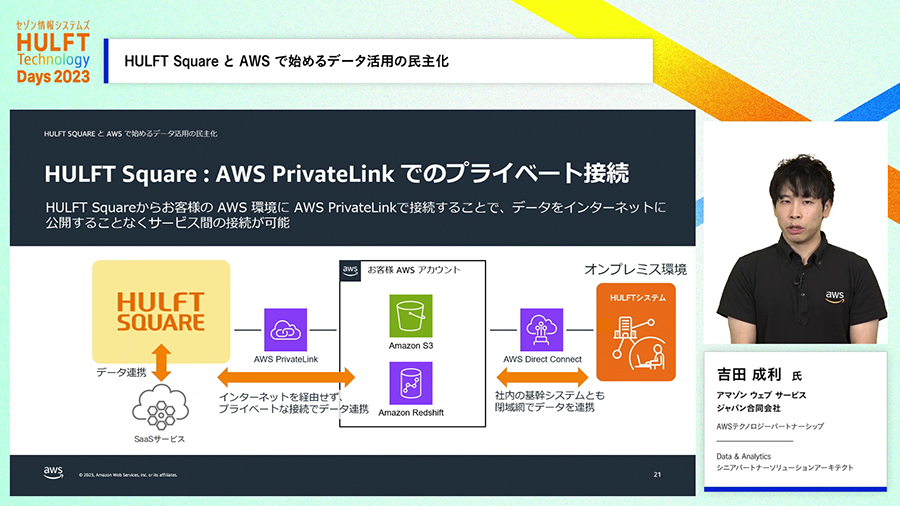
オンプレミスの環境からインターネットを経由せずにAWSとの間でデータ転送ができるAWS PrivateLinkにも対応しているため、セキュアさを重視する必要があるデータでも利用しやすくなっています。
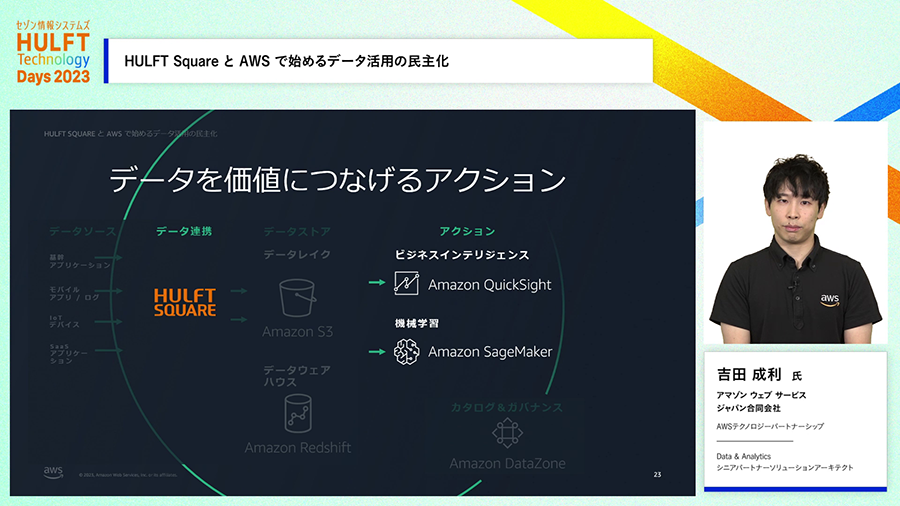
データレイクやDWHに溜めたデータを用いて何かの知見を得ることや、得た知見を使ったアクションもAWS上で出来ます。
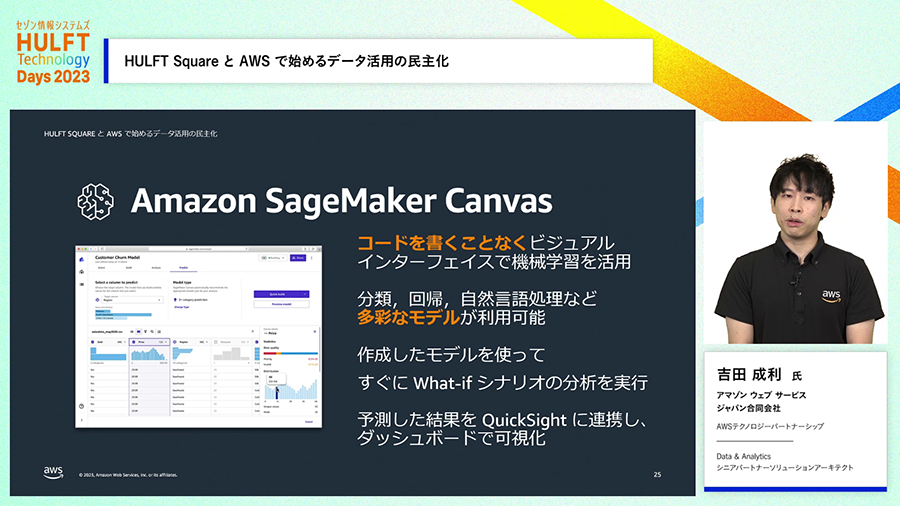
DWHに対してSQLで問い合わせをして、その結果をビジュアルに可視化してレポート作成などができるBIツールであるAmazon QuickSightを活用することができます。Amazon SageMakerを活用すれば機械学習を用いたデータ活用にも取り組めます。特にAmazon SageMaker Canvasはコードを書くことなくGUIだけで機械学習を活用できるサービスであり、ユーザ部門などより広い人たちが自ら機械学習を使って成果を出すことを可能にします。

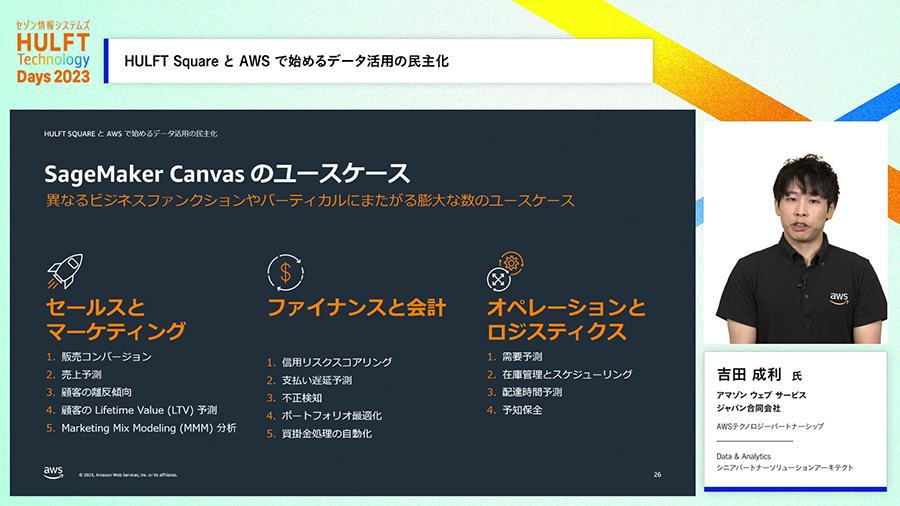
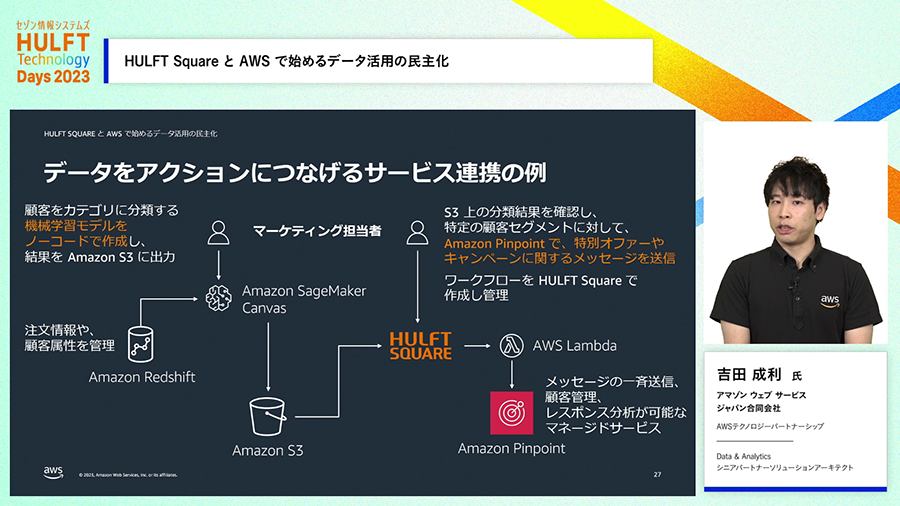
機械学習を活用して得られた知見をビジネスのアクションにつなげることもできます。SageMakerの処理結果をAmazon S3に格納、HULFT Squareがそれを参照して外部にデータを連携することや、外部のシステムの機能を起動することで、データから機械学習で得た知見から、その判断でビジネスの打ち手を自動的に実行する仕組みも実現できます。
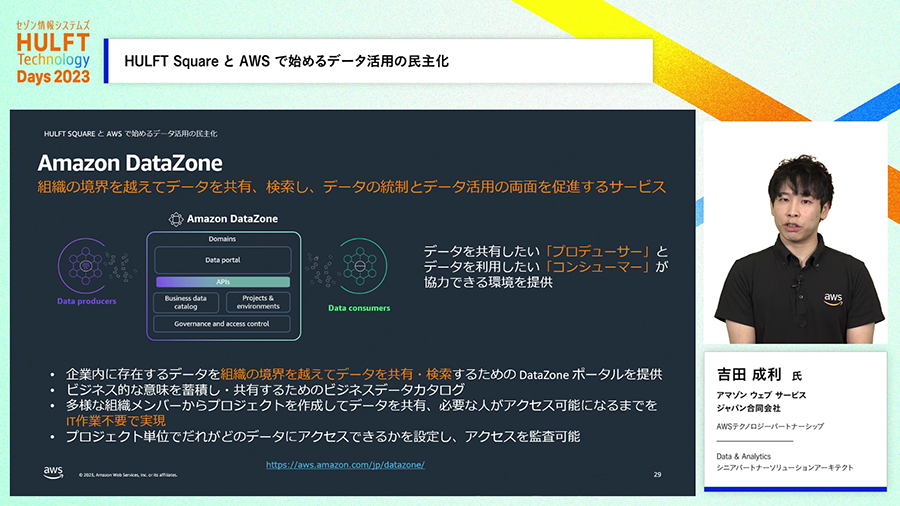
また、データ基盤の活用で問題になるのは、社内の各部門からスムーズにデータが提供される環境の整備や、データを必要とする各部門がスムーズに必要なデータを見つけて利用できる環境の整備です。AWSではこれらについても解決できる機能を提供しています。
Amazon DataZoneを使うと、データレイクやDWHにどんなデータが格納されているか、データカタログを検索して利用者が自分で必要なデータを見つけることができます。
では、そのような整備されたデータ環境は誰が整備するのかというと、こちらもユーザ部門が自ら行うことができます。自部門が持つデータについてどういうデータがあるのか説明を添えて共有することができます。
そしてデータは利用申請を経て利用できるようにすることもでき、検索して見つけた利用したいデータがあった場合には利用申請をすると、そのデータを提供しているユーザ部門が自分で許可するか判断し、許可されればデータをすぐ利用することができます。
多くのデータ基盤ではこのような取り組みで、ITに詳しい人やデータを管理する人の作業を経る必要があり、彼らに処理負荷が集中してしまう問題がありますが、ユーザ部門で多くのことが解決できる仕組みになっています。
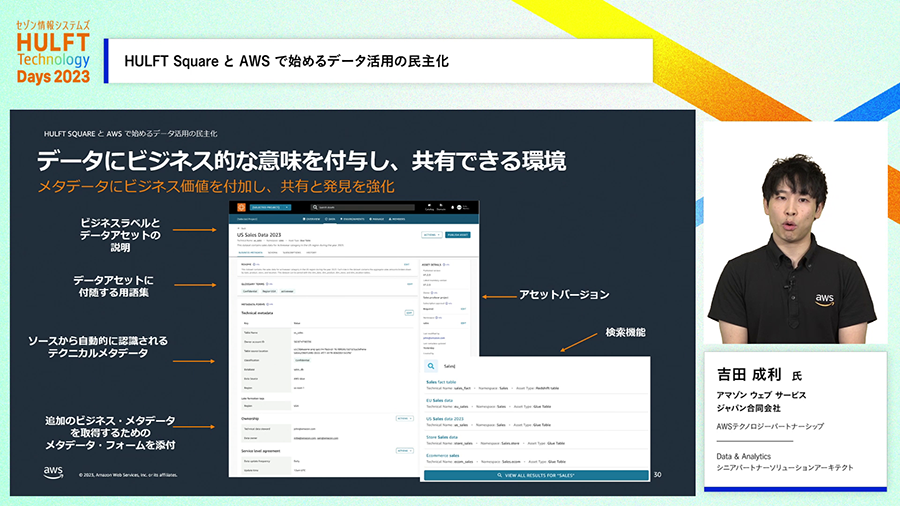

最後に以上をまとめたスライドになります。ユーザ部門が自らデータ活用に取り組める環境の整備、つまりデータ活用の民主化が必要であり、その実現には「AWSのサービス」と「HULFT Square」を組み合わせた活用が有効です。
HULFTイベントレポート 一覧
- 第1回 スマート工場EXPOに出展しました!
- 第2回 関西IoT/M2M展に出展しました!
- 第3回 Japan IT Week 春「AI・業務自動化展」に出展しました!
- 第4回 スマートファクトリーJapan 2019 に出展しました!
- 第5回 TerraSkyDay 2019にDataSpider Cloudを出展しました!
- 第6回 第13回 ITヘルスケア学会 学術大会に出展しました!
- 第7回 Box World Tour Tokyo 2019
- 第8回 シーコン・フォーラム2019でDataSpiderとPIMSYNCを紹介しました!
- 第9回 FIT2019(金融国際情報技術展)に出展しました!
- 第10回 HULFT DAYS 2019 今年も開催しました!(その1)
- 第10回 HULFT DAYS 2019 今年も開催しました!(その2)
- 第10回 HULFT DAYS 2019 今年も開催しました!(その3)
- 第11回 「RPA DIGITAL WORLD 2019」に出展しました!
- 第12回 「地方創生 EXPO」に出展しました!
- 第13回 HULFT DAYS 2021 今年も開催しました!
- 第14回 HULFT DAYS 2022 今年も開催しました!(その1)
- 第14回 HULFT DAYS 2022 今年も開催しました!(その2)
- 第14回 HULFT DAYS 2022 今年も開催しました!(その3)
- 第15回 DXをもっと加速!HULFT DAYS STEP UP Seminar 2022 を開催しました!
- 第16回 HULFT Technology Days 2023 今年も開催しました!(その1)
- 第16回 HULFT Technology Days 2023 今年も開催しました!(その2)
- 第16回 HULFT Technology Days 2023 今年も開催しました!(その3)
- 第17回 HULFT Technology Days 2023 今年も開催しました!(Business Day:その1)
- 第17回 HULFT Technology Days 2023 今年も開催しました!(Business Day:その2)
- 第18回 HULFT Technology Days 2023 今年も開催しました!(Technical Day:その1)
- 第18回 HULFT Technology Days 2023 今年も開催しました!(Technical Day:その2)
- 第19回 AWS re:Invent 2023出展特設ページ
- 第20回 HULFT Technology Days 2024 今年も開催しました!(1日目:その1)
- 第20回 HULFT Technology Days 2024 今年も開催しました!(1日目:その2)
- 第21回 HULFT Technology Days 2024 今年も開催しました!(2日目)
- 第22回 HULFT Technology Days 2024 今年も開催しました!(3日目)
企業内・企業間通信ミドルウェアのデファクトスタンダード「HULFT8」

顧客満足度No.1 EAIソフトウェア
「DataSpider Servista」
