脱PoC!RAGの本番運用を支える「データパイプライン」とは
社内データ等の特定の情報源を元に生成AIが回答する仕組みを支えるRAG(Retrieval-Augmented Generation)は、ビジネスにおけるデータ活用を推進する鍵として注目されています。しかし、多くの企業でRAGの導入がPoC段階で止まっているのが現状です。このような状況を打破する鍵が、生成AIに高品質なデータを供給する「データパイプライン」です。
このコラムでは、RAGの本番運用を支えるデータパイプラインの構築と、その実現を助けるiPaaSの役割について解説します。
![]() Shinnosuke Yamamoto -読み終わるまで6分
Shinnosuke Yamamoto -読み終わるまで6分
なぜRAGはPoCのまま進まないのか?
RAGの導入プロジェクトがPoC段階から本格運用へ移行できない背景には、共通の課題が存在します。多くの企業でRAGの実証実験が進められるものの、本番稼働が進まない原因は、技術面だけでなく、運用面やデータ管理面に根深くあります。PoCでは限定的なデータセットを用いるため回答精度を検証しやすいですが、大規模な非構造化データを扱う本番環境では想定外の問題が頻発します。さらに、法令遵守やビジネス要件など、PoCでは見落とされがちな要素も、運用フェーズではクリアしなければなりません。
-
▼RAGについてもっと詳しく知りたい
⇒ 検索拡張生成(RAG:Retrieval Augmented Generation) |用語集
回答精度が高まらない
RAGが参照するデータは、PDFやWebページ、音声データなど、多様なフォーマットの「非構造化データ」が非常に多くを占めます。人間には理解できても、RAGの基盤となるLLMが、これらのフォーマットから文脈を適切につかむのは得意ではありません。例えば、文書内の表や画像、複雑なレイアウトがLLMの解析を妨げる要因となることがあります。結果として、LLMが重要な情報を正確に抽出しきれず、RAGの回答精度が大きく不安定になってしまうのです。
非構造化データには、本来の意図とは異なる冗長な情報や、解析の妨げとなる不要なノイズが混入しているケースも少なくありません。例えば、Webページから抽出されたテキストには、広告やナビゲーションリンクなど、生成AIの回答には不要な要素が含まれることがあります。このようなノイズは、LLMが本当に必要な情報を正確に識別し、抽出し、適切に文脈を理解するのを困難にさせます。結果として、RAGはノイズに惑わされ、期待される回答精度を発揮できず、時には誤った情報を生成してしまうリスクさえあります。
-
▼LLMについてもっと詳しく知りたい
⇒ 大規模言語モデル(LLM:Large Language Model) |用語集
回答の裏付けが取れない
生成AIの回答は、ビジネスの場で活用されるからこそ、その正確性が保証されなければなりません。そのためには、回答の根拠となる情報源を明確に示す「透明性」が不可欠です。しかし、PoC段階のRAG実装では、参照元の情報が不足していたり、追跡しにくい設計になっているケースが散見されます。例えば、回答の基になった文書のページ番号やURL、具体的な作成者情報などが紐づいていないと、ユーザーや運用者が回答の裏付けを迅速に確認することが困難になります。
このような状況下では、生成AIが事実に基づかない情報を生成する「ハルシネーション」による誤回答や、参照ミスによる不正確な内容がそのまま利用者に提供されてしまうリスクが高まります。これは企業の信頼性を損ねるだけでなく、誤った情報に基づく意思決定を招く可能性さえあります。本番運用において、RAGの回答に対する情報の透明性と信頼性を高めるためには、データソースとRAGが参照した情報との関連付けを容易にする「メタデータ管理」が極めて重要な要素となります。これにより、疑わしい回答の即時検証と修正が可能になります。
データの二重管理が発生する
RAGを導入する際、既存システムからデータを抽出し、コピーしてRAG専用の検索インデックスとして保持することが一般的です。しかしこのアプローチは、元データとRAG側データの「二重管理」を招き、データの整合性維持を極めて複雑にします。顧客情報や製品カタログ、社内規程など、更新頻度が高いデータを扱う場合、RAG側のデータを元データと常に同期させる必要があり、これは手動では非現実的なほどのメンテナンス負荷となります。自動化を怠れば、データ不整合のリスクが常につきまとうことになります。
さらに、データの二重管理は、多くの運用上・管理上の課題を引き起こします。例えば、アクセス権限の一元管理が難しくなったり、監査証跡の管理が複雑化したりする問題が顕在化します。これはセキュリティリスクやデータガバナンスの観点からも望ましくありません。また、バージョンの管理も煩雑になりがちです。たとえRAGに最新の情報を提供できたとしても、これらの運用コストがかさんでしまえば、費用対効果が悪化し、長期的なシステム運用を持続させることは困難になるでしょう。効率的で持続可能な運用には、二重管理の解消が不可欠です。
データの異常を検知できない
RAGのPoC段階では、扱うデータ量が限られているため、たとえデータの取り込みに問題が発生しても比較的気づきやすいものです。しかし、本番運用では膨大なデータが複数のソースから流入し、人間が目視でデータの正否を判断することはほぼ不可能です。データの取り込みが失敗したり、一部が欠損したりしても、RAGは動作し続け、一見問題なく情報を提供しているように見えてしまう恐れがあります。
運用者が異常に気づかないままRAGが稼働し続けると、知らず知らずのうちに回答精度が低下し、誤情報提供のリスクが拡大します。これはビジネス上の深刻な損失や機会損失につながりかねません。特に、重要なデータが欠損した状態でRAGが応答を生成し続けることは、組織の重要な意思決定を誤らせる可能性すらあります。このような状況を未然に防ぎ、RAGの安定稼働と信頼性維持を目指すためには、データの取り込み状況をリアルタイムで監視し、異常を自動的に検知して運用者に通知する仕組みが不可欠となります。
RAGを本番運用するためのデータパイプラインとは
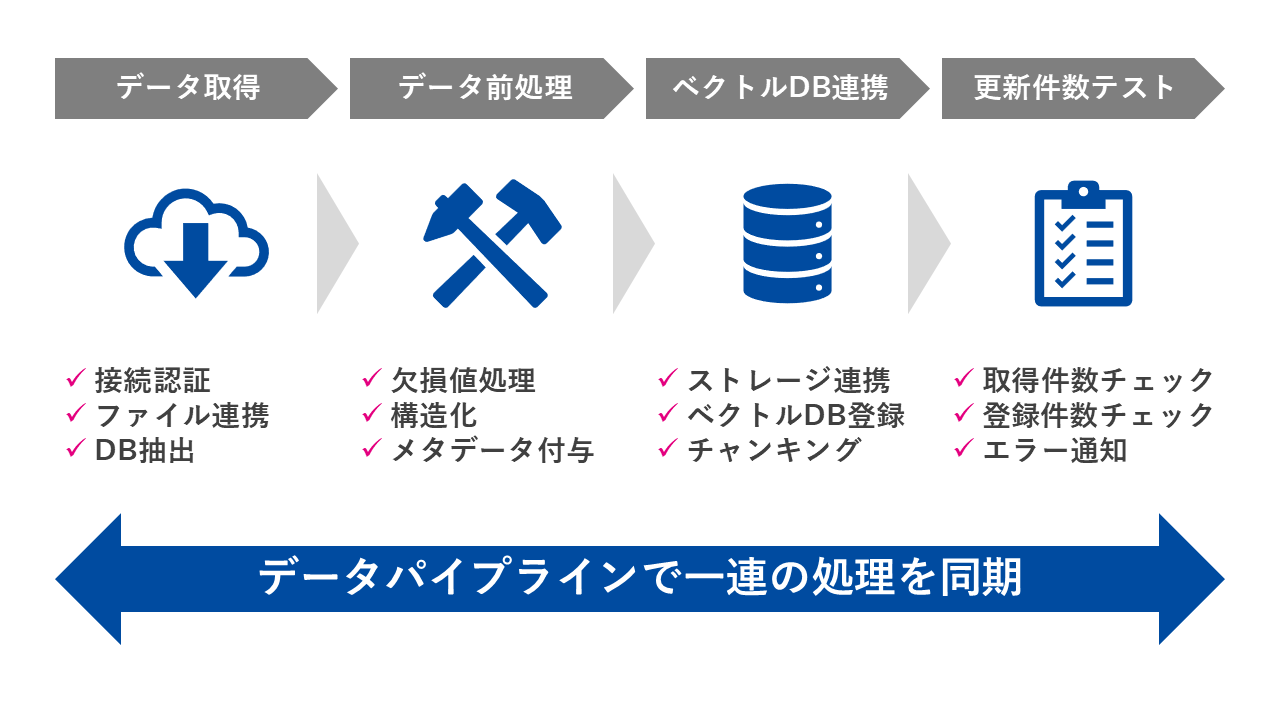
RAGが抱える課題を解決し、本格的な運用へ移行するためには、「データパイプライン」の構築が不可欠です。データパイプラインとは、データの収集から、変換、格納、そして生成AIへの配信に至る一連の流れを、効率的かつ体系的に管理する仕組みを指します。これをRAGの基盤とすることで、異なるシステムに散らばる多様なデータを統合し、その品質を保ちながら、RAGのデータセットを常に最新の状態に保つことができます。
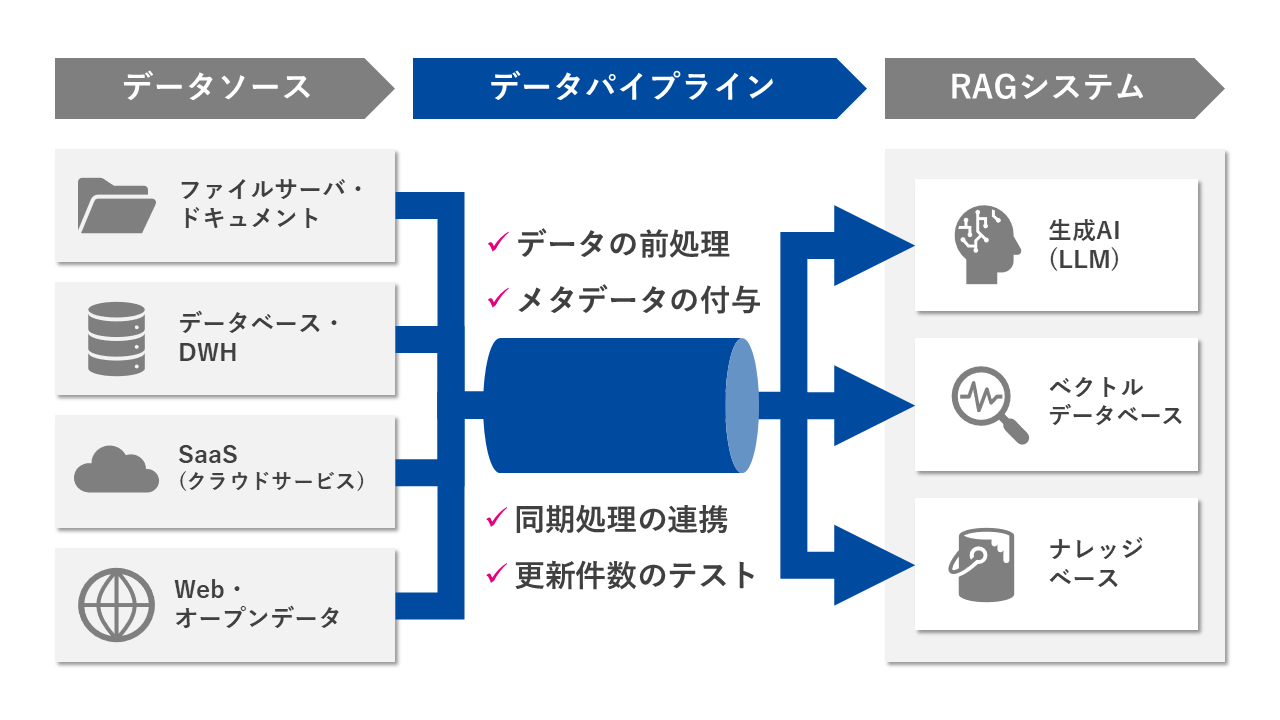
データの前処理
RAG運用において最も重要なステップの一つが、多種多様なフォーマットで存在する生データを、LLMが読解しやすい形に整形・加工する「データ前処理」です。生成AIは文脈や文書構造の把握を得意としますが、PDFの画像データや未整理なテキストファイルなど、データがバラバラな状態では、そのパフォーマンスが安定しません。この前処理工程では、複雑な文書形式を解析し、見出し構造が明確で階層的な形式に統一することで、LLMが効率的に情報を抽出し、回答精度を向上させます。
また、特定の業務要件によっては、文書内の情報を抽出し、意図的にQ&Aペアの形式に変換するといった、さらに高度な前処理も効果的です。これにより、RAGが特定の質問に対してより直接的かつ正確な回答を生成しやすくなります。このようなデータ前処理の工程を自動化し、データパイプラインのワークフローに組み込むことは、本番運用における手動での作業負荷を大幅に削減します。同時に、継続的に高品質なデータをRAGに供給することで、回答精度を安定化させるための鍵となります。
メタデータの付与
RAGが生成した回答の信頼性を確保し、ユーザーが安心して利用できるようにするためには、その情報源を明確に示す「透明性」が不可欠です。この透明性を実現するのが、データそのものに付与する「メタデータ」です。例えば、文書の作成者、最終更新日時、公開範囲、元のシステム名、アクセスURL、関連キーワードなどの情報をアノテーションとしてRAGのデータセットに取り込むことで、生成された回答とともにその根拠となる情報を容易に利用者へ提示することが可能になります。
このメタデータ付与により、ユーザーはRAGが参照した情報の信憑性を自ら確認できるようになり、RAGシステム全体への信頼性が向上します。また、万が一ハルシネーションなどによる誤回答が発生した場合でも、メタデータを通じてその元となった情報を素早く特定し、迅速に訂正する体制を整えることができます。メタデータはデータの鮮度に応じて適切に管理・更新される必要があります。そのため、データパイプラインの設計段階で、メタデータの収集、付与、そして継続的な管理の方法をしっかりと考慮し、運用プロセスに組み込むことが極めて重要となります。
同期処理の連携
RAGを本番運用する上で、参照データが更新されるたびに手動でRAGの検索インデックスを再構築する運用は、効率性とスケーラビリティの観点から非現実的です。特に、データ量が増加し、更新頻度が高まる本番環境では、手動運用では追いつかなくなります。そこで極めて重要となるのが、データソースシステムとRAGの間でデータの更新を検知し、それに伴う一連の処理を半自動または全自動で実行する「同期処理の連携」の仕組みです。これにより、運用負荷を大幅に削減することが可能になります。
この同期処理の連携では、例えば社内データベースのレコード更新や、ファイルサーバーへの新規文書追加といったイベントをトリガーとして、データの前処理、メタデータ付与、そしてRAGの検索インデックス(ベクトルデータベースなど)への取り込みといった一連の工程を一括で自動実行します。これにより、RAGは常に最新のデータを基に回答を提供できるようになり、情報の鮮度と正確性を維持できます。
更新件数のテスト
データパイプラインにおいては、単にデータを取り込むだけでなく、そのデータが期待通りの件数や内容でRAGに反映されているかを継続的に検証する「データ品質テスト」の仕組みが不可欠です。RAGのようなシステムでは、データの取り込みプロセス中に、ネットワーク障害、APIエラー、データ形式の不整合、あるいは処理中断など、さまざまな理由でデータが正しく反映されないトラブルが発生する可能性があります。これらの問題は、すぐにRAGの回答品質に影響を与え、ユーザー体験を損ねる原因となります。
このようなデータ取り込みの異常を放置すると、徐々にRAGの回答精度が低下し、最悪の場合、一部の質問に対して全く回答できなくなる恐れがあります。そこで、更新されたデータソースのレコード数とRAGにインデックス化されたデータの件数の一致、あるいは特定のフィールド内容の異常がないかといったテストを自動的に実行することが重要です。差異や異常を検知した際には、Slack通知やメール、ダッシュボード表示といった自動アラート機能で即座に運用者に通知する仕組みを構築します。これにより、問題発生時に迅速に原因を特定し、対処できるようになり、RAGの安定した回答品質を維持することが可能になります。
データパイプラインを実現するiPaaSとは
ここからは、RAGのためのデータパイプラインを、開発者だけでなくビジネス部門や運用担当者にも扱いやすい形で構築できるソリューション、「iPaaS」の役割とメリットを解説します。
iPaaS(Integration Platform as a Service)は、クラウドベースで提供される統合プラットフォームで、多様なアプリケーションやデータソースを容易に接続・連携できます。RAGが必要とする複雑なデータパイプラインも、iPaaSを活用すれば効率的に構築・運用が可能です。ファイルストレージ、SaaS、DBなど多岐にわたるシステムからデータを引き出し、RAGに最適な形式へ整形するプロセスを、ノーコードまたはローコードで実現します。
-
▼iPaaSについてもっと詳しく知りたい
⇒ iPaaS|用語集
これにより、専門知識なしにデータ連携や変換ロジックを実装でき、運用担当者自身がワークフローの修正やモニタリングも行えます。開発部門の負担を軽減しつつ、ビジネスの要求に迅速に対応できるため、RAGを含む生成AI活用の競争優位性を高めます。
さいごに
PoCでは機能検証に焦点が当たりがちですが、本格運用にはデータ品質の保証、管理、更新といったプロセスが大きな障壁となります。データパイプラインをしっかりと設計・運用すれば、非構造化データの前処理、メタデータ付与、更新同期、品質監視など、RAGにおけるあらゆる局面でデータ品質を確保できます。
iPaaSのようなプラットフォームを活用すれば、複雑なデータ連携や統合プロセスをスムーズに設計・実装でき、開発時間とコストを削減しつつ、ビジネス部門を含むチーム全体で効率的なRAG運用が可能になります
執筆者プロフィール

山本 進之介
- ・所 属:データインテグレーションコンサルティング部 Data & AI エバンジェリスト
- 入社後、データエンジニアとして大手製造業のお客様を中心にデータ基盤の設計・開発に従事。その後、データ連携の標準化や生成AI環境の導入に関する事業企画に携わる。2023年4月からはプリセールスとして、データ基盤に関わる提案およびサービス企画を行いながら、セミナーでの講演など、「データ×生成AI」領域のエバンジェリストとして活動。趣味は離島旅行と露天風呂巡り。
- (所属は掲載時のものです)
おすすめコンテンツ



データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!