メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
生成AIの活用が進む中、データの文脈を読み解くうえで重要となるのがメタデータです。メタデータを正しく整備することで、必要な情報にスムーズにアクセスしやすくなり、回答の精度向上も期待できます。本記事では、なぜ生成AIにメタデータが必要なのか、どのようなメタデータを整備すればよいのか、そして具体的な整備手法について解説します。
![]() Shinnosuke Yamamoto -読み終わるまで6分
Shinnosuke Yamamoto -読み終わるまで6分

生成AIにメタデータが必要な理由
いまや生成AIは情報検索や要約・翻訳の役割に留まらず、 RAGやAIエージェントに見られるように、社内外のデータに接続することで付加価値を生み出したり業務を効率化することが当たり前になりました。
そもそも生成AIの回答精度は、どれだけ適切にデータの背景や文脈を理解できるかに大きく左右されます。メタデータは、データの作成日時や意味づけ、所有部門などを示す付加情報で、AIにとっては学習時や回答時の重要なヒントとなります。
▼メタデータの基本は以下で解説

メタデータとは?基礎から最新動向まで徹底解説
メタデータに関する情報をまとめました。組織全体でメタデータを一貫して管理する体制を整え、効率的な情報活用の実現にお役立てください!
-
▼生成AIについてもっと詳しく知りたい
⇒ 生成AI(Generative AI) |用語集
-
▼RAGについてもっと詳しく知りたい
⇒ 検索拡張生成(RAG:Retrieval Augmented Generation)|用語集
生成AIによるメタデータの使い方
生成AIがどのようにしてメタデータを利用するかは、RAGやAIエージェントといった仕組みや、データの形式によって異なる部分がありますが、一般的にはデータを検索するプロセスと回答するプロセスで用いられます。
PDFドキュメント等の非構造化データを検索する場合、検索対象になるドキュメントの数は膨大になりがちです。ユーザーが望むひとつのドキュメントにたどり着くには、生成AIはこの広大な検索範囲の中から探し出す必要があります。例えば、このドキュメントが業務マニュアルなのか提案書なのか、経理関連のドキュメントか法務関連のドキュメントかがメタデータとして管理されていれば、検索対象を絞り込んで効率的に検索を行うことが可能です。
データベースなど表形式で管理されている構造化データを検索する場合は、データを抽出するためのクエリ(SQL)を組み立てる上で役立ちます。テーブルやカラムの定義をメタデータとして把握することで、ユーザーの要望に基づいた最適なテーブルとカラムを選択し、適切な抽出条件でデータを取得します。
回答時には、メタデータをもとに参照しているデータがどのようなデータなのかを前提知識として生成AIが理解することで、適切な文脈や意図に沿った回答を導くことができるようになります。
メタデータが不十分な場合に起こり得ること
メタデータが不十分だと、生成AIが適切な情報へ到達できず誤った回答を導くリスクが高まります。一見すると小さな情報の抜けや更新漏れでも、回答結果に大きな影響を及ぼすことがあります。
例えば、企画担当者がチャットボットに「1年間の売上について、顧客のグループ毎の傾向を分析して。」と投げかけた結果、以下の回答が返ってきたとしましょう。
商談管理データベースをもとに2019年の売上傾向を分析しました。各顧客区分ごとの分析結果は以下の通りです:
2019年の顧客区分コード1の顧客の売上は、見積金額が安定していました。総売上は990,000円で、最大の売上は12月に記録されました。春と秋に若干のピークが見られます。
2019年の顧客区分コード2の顧客の売上は、一貫して安定していました。総売上は820,000円で、最大の売上は11月に記録されました。年間を通じて安定した売上傾向があります。
この回答に違和感を感じた方もいるかもしれません。この違和感は、メタデータが整備されていないことで実際に起こり得ることです。違和感の正体についてもう少し深掘りをします。
誤ったデータソースを選択してしまっている
企画担当者は、会計データベースに登録されている売上実績の分析を想定していましたが、ここでは商談管理データベースの売上記録を参照しています。もしこれらの売上が連動せず、個別に管理されていれば、売上という名前が同じでも計上タイミングや計算式等の定義が異なっている可能性があります。
古いデータを取得してしまっている
更新日時がメタデータとして管理されていない場合は、一度取り込んだ情報の刷新が難しくなり、古いデータをいつまでも使い続けることになります。最新情報を参照するつもりでも、生成AIが更新時点を把握できず、結果的に誤った回答を返してしまう原因になりかねません。
コード番号ではデータの意味が分からない
回答の中では顧客区分コード1・2が登場しますが、コード体系が不明瞭であったりすると、生成AIは情報の解釈を誤る可能性があるほか、ユーザーから見てもどういう意味かが分かりません。単なる文字列や数字の羅列だけでは、何を表しているのか分からず、回答の筋が大きく外れてしまう恐れがあります。
本当は元のデータを見て確認したいのに辿れない
商談管理データベースとだけ書かれても、実際にどのようなデータを抽出して回答したのか、どのドキュメントを参照しているのか、実際のデータを見たいということもあるでしょう。必要な参照元の情報がメタデータとして記録されていない場合、情報の信頼性を掘り下げたい時に行き着く先が不明になってしまいます。
生成AIの回答精度を高める重要なメタデータ
生成AIが正しく回答するためには、データにひもづく情報を多角的に整理しておくことが重要です。ここでは、代表的なメタデータの項目を取り上げて解説します。
生成AIが参照できるメタデータにはさまざまな種類がありますが、どのデータを誰が管理し、どの時点の情報なのかといった基本的な情報は特に重要です。RAGのような検索強化の仕組みにおいては、それぞれのメタデータを有効に使うことで、無駄な検索を省き正確性を高めることができます。

主管部門・更新者:誰のデータか?
データの所有部門や担当が分かるメタデータがあれば、情報の信頼性を迅速に判断できます。また、最新の更新状況を追うためにも、誰が更新作業を行っているのかが高い精度の回答にとって重要です。責任所在がはっきりすることで、生成AIが参照すべきデータ源を正しく絞り込みやすくなります。
例えば、売上に関するデータが営業部門管理なのか経理部門管理なのかが明確であれば、生成AIはより正しい文脈で回答を組み立てられます。担当者や部署の情報をメタデータ化しておくことで、問い合わせに対する追加確認先やデータ鮮度の追跡も容易になります。
用語・コード体系:何のデータか?
コードや用語が多用されるデータでは、その定義をメタデータとして保持することが非常に大切です。文字や数字だけでは解釈できない意味づけがある場合、生成AIが誤解したまま回答してしまうリスクが高まります。
例えば商品コードや地域コードなどは定義が細かく異なり、誤って他のコードと混同すると分析結果も狂ってしまいます。生成AIがコードの説明を把握できれば、検索や回答の際に文脈を正しく判断し、より適切な情報を提供できるようになります。
作成日・更新日:いつのデータか?
生成AIが古い情報を参照して回答するのを防ぐためにも、日時に関するメタデータは不可欠です。特にトレンドや時点による違いが大きい分野では、作成・更新日を正しく把握しておくことが回答の正確性を左右します。
売上データや顧客情報などは、月次・年次での変遷が重要になるケースが多々あります。生成AIが作成日や更新日を参照できれば、問い合わせの時点に最も近いデータを選び出して回答し、旧情報によるミスを減らせるのです。
配置場所・URL:どこのデータか?
データがどのサーバやどのファイルパス、あるいはどのウェブページにあるのかを把握していると、後から再確認や追加のデータ取得がしやすくなります。生成AIによる回答で疑問点が出てきたときにも、配置場所やURLが明確ならばすぐに原データにアクセスしてクロスチェックが可能です。
例えばドキュメントへのリンクがメタデータとして登録されていれば、AIが回答した内容を裏付けたいときに参照先をユーザーに提示できます。最終的な意思決定の材料として信頼度を高めるうえでも、配置場所を示すメタデータは欠かせません。
業務・収集目的:何のためのデータか?
データがどういった目的で集められているのかは、生成AIによる回答に大きく影響を与えます。目的を踏まえたうえで回答を導けば、無用な情報を取り除き、より的確な内容に絞り込むことができます。
例えば、顧客アンケートデータがマーケティング施策の改善に使われるものなのか、あるいは製品開発の参考データなのかで重視すべき観点は違います。生成AIが業務・収集目的を理解できるようメタデータを与えることで、回答に含めるべき優先情報を適切に選定できます。
導出方法・算定式:どのようなデータか?
計算や集計を経て作られたデータは、その算定式やプロセスをメタデータとして残しておくことで正しく評価できます。背景を知らないまま利用すると、生成AIが計算結果の前提を見誤る可能性があります。
例えば、利益率の算定式やマスターデータの連携ルールが明示されていれば、生成AIが数値の裏付けを理解しやすくなります。結果としてユーザーへの説得力ある回答が生み出され、データの活用価値が高まっていきます。
生成AIのためのメタデータの整備方法
メタデータを整備する手段として、データカタログやシステム連携、さらにはAIによる自動生成などが挙げられます。自社の規模やデータの性質に合わせて最適な方法を選び、複数のアプローチを組み合わせることも有効です。
管理体制を整えないままデータを拡充しても、誰も手に負えない状態になる可能性があります。だからこそ、スキーマ設計や運用ルールを明確に定めたうえで、継続的にメタデータを更新する仕組みを作ることが大切です。
データカタログによるメタデータの管理
データカタログとは、企業内に散在するデータの概要や属性を一元的に管理する仕組みです。データの説明や所有者情報、ファイルレイアウト、テーブル定義書などをまとめて登録することで、いつ誰がどのデータを閲覧・更新したかも含めて追跡が容易になります。
これにより、これまでは分散していた定義情報や文書を集約し、更新状況を一目で把握できるようになります。結果として、生成AIが参照できるメタデータの精度が高まり、回答の根拠となる情報を簡単に見つけやすくなるメリットがあります。
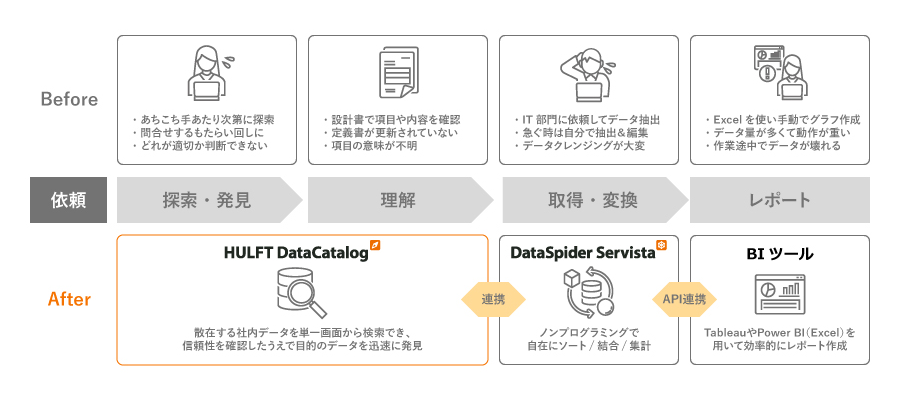
セゾンテクノロジーのメタデータ管理ソリューション「HULFT DataCatalog」
HULFT DataCatalog(ハルフト データカタログ)は、企業内で分散管理される様々なデータの概要(メタデータ)を自動収集してカタログ化。所在や来歴を可視化し、データに関するナレッジを共有することで、データ探索の効率化とデータの内容に関する理解促進を支援します。
データ連携によるメタデータの付与
データベースやクラウドストレージ、SaaSなど、データソース側で更新日時や更新者、URLといった情報を保持している場合があります。この場合では、データ連携によって自動的にこれらの情報をメタデータとして取得することができます。メタデータを人手で入力する手間を大幅に削減できるうえ、リアルタイムで情報が更新されるメリットがあります。
このような連携を行うことで、人為的な入力ミスを最小限に抑えつつ、タイムリーに正確な情報を維持しやすくなります。大規模なデータ運用環境では特に効果が高く、メタデータの網羅性を保ちながら更新コストを削減できます。

iPaaS型データ連携基盤 HULFT Square(ハルフトスクエア)
HULFT Squareは、「データ活用するためのデータ準備」や「業務システムをつなぐデータ連携」を支援する日本発のiPaaS(クラウド型データ連携プラットフォーム)です。各種クラウドサービス、オンプレミスなど、多種多様なシステム間のスムーズなデータ連携を実現します。
AIによるメタデータの自動生成
レガシーシステムが持つ古いデータの場合だと、そもそもテーブル定義書やデータの説明書がないという場合もあるかもしれません。この場合は、データの中身をもとにテーブルやカラムの意味をAIで推測させ、メタデータとして補完させるというアプローチが考えられます。
また、テキストファイルや画像、音声といったファイルであれば、OCRや画像認識モデル、音声認識モデルと連携することで、どのようなデータなのかを示すサマリーや、検索時の分類基準となるタグ情報を自動的に生成して付与する方法があります。特に非構造化データは普段の業務の中で頻繁に新規作成・更新されるため、生成AIに参照させるためにも、事前にAIによって自動的にメタデータを拡充していくことが重要です。
まとめ
メタデータを整備することで生成AIの回答精度や運用効率が大幅に高まります。正確な検索やデータの絞り込みだけでなく、回答そのものの信頼度や説得力を裏打ちするための土台ともいえます。データが増え続ける現代において、早めにメタデータの整備手法を検討し、継続的に運用していくことが重要です。
一度メタデータの枠組みを構築すれば、新たなデータが入るたびにスムーズに情報を付加できるようになります。これによって生成AIを活用したデータ活用がより強力かつ効率的になり、顧客対応や社内業務の最適化に直結する成果を期待できるでしょう。
執筆者プロフィール

山本 進之介
- ・所 属:データインテグレーションコンサルティング部 Data & AI エバンジェリスト
- 入社後、データエンジニアとして大手製造業のお客様を中心にデータ基盤の設計・開発に従事。その後、データ連携の標準化や生成AI環境の導入に関する事業企画に携わる。2023年4月からはプリセールスとして、データ基盤に関わる提案およびサービス企画を行いながら、セミナーでの講演など、「データ×生成AI」領域のエバンジェリストとして活動。趣味は離島旅行と露天風呂巡り。
- (所属は掲載時のものです)
おすすめコンテンツ



データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!