生成 AI が切り開く「データの民主化」
全社員のデータ活用を阻む「2つの壁」の突破法
ビジネスにおけるデータ活用はもはや必須の時代。しかし、企業の全社員がでそれぞれの業務でデータ活用を進める「データの民主化」を実現するためにはいくつかの課題が立ちはだかります。本記事では、生成AIを使って、業務に忙殺されがちな社員がスムーズにデータを活用できる仕組みを実現した当社の事例を通じて、「2つの壁」を突破するための具体的なアプローチを掘り下げます。
![]() Seiji Hosomi
- 読み終わるまで 8分
Seiji Hosomi
- 読み終わるまで 8分

ビジネスにおいてデータ活用が重要とされる理由
ビッグデータやクラウドコンピューティングの発展により、企業はデジタルプラットフォームを活用して膨大なデータを生成するようになりました。市場の急速な変化に伴い、データを活用した迅速な意思決定や競争優位の確保が、現代ビジネスにおける重要なトレンドとなっています。
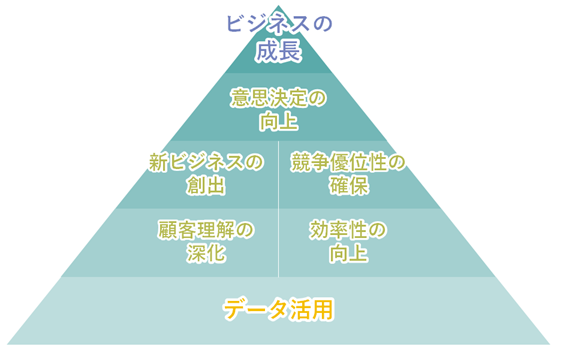
ビジネスにおいてデータ活用が重要視される理由はいくつかあります。
-
意思決定精度の向上:
データに基づく意思決定は、感情や直感に頼るよりも信頼性が高く、具体的な情報をもとに戦略を策定することでリスクを低減できます。 -
顧客理解の深化:
顧客の行動データを分析することで、ニーズや行動パターンを把握し、パーソナライズされたサービスや商品の提供が可能となり、顧客満足度の向上に寄与します。 -
効率性の向上:
業務プロセスのデータ分析を通じて、無駄やボトルネックを特定し、効率改善の手段を見出すことができます。 -
競争優位性の確保:
データを効果的に活用することで、市場のトレンドを把握し、競合他社に先駆けた施策を策定することができます。 -
新しいビジネスモデルの創出:
データ分析を通じて、未開拓の市場や新サービスのアイデアを発見し、ビジネスの成長につなげることが可能です。
データ活用は専門職から一般社員へ
従来のデータ分析は、主に専門のデータサイエンティストやアナリストによって行われていました。
これらの専門家は高度な技術や知識を持ち、データの収集、解析、可視化を担当していました。そのため、データへのアクセスや分析は一部の専門担当者に限定され、多くの社員や部門はデータを十分に活用できない状況でした。結果として、意思決定はデータに基づくものではなく、経験や直感に依存することが多かったのです。
このような背景から、「データの民主化」という考え方が広まり始めました。
データにアクセスできる人が増えることで、情報に基づいた迅速な意思決定が可能になり、様々な視点からデータを活用することで、新たなアイデアや解決策が生まれ、イノベーションが促進されます。
また、データをオープンにすることでプロセスや結果への理解が深まり、データ分析スキルが広がることで個々の能力が向上し、組織全体のパフォーマンス向上にも寄与します。
| 観点 | 従来のデータ分析 | データの民主化 |
| 分析する人 | 限られた専門家(データサイエンティスト、アナリスト) | 一般社員 |
| メリット | - 高度な専門知識を持つ専門家が正確かつ精密にデータを分析 - 高度な分析ツールや手法を使用可能. |
- 意思決定が迅速かつデータに基づいたものになる - 多様な視点でデータを活用し、新たなアイデアが生まれやすい |
| デメリット | - データにアクセスできる人が限られており、組織全体での活用が難しい - 社員レベルでは意思決定が経験や直感に依存する |
- 分析の精度が低くなる可能性がある(専門家ではないため) - 社員間でのデータ理解度に差が生じる可能性がある - データの適切な利用方法やセキュリティが不足するリスク |
| データ活用の速度 | - 分析結果が出るまでに時間がかかる | - 迅速にデータを活用でき、即時の意思決定やアクションが可能 |
| イノベーション | - 専門家による分析が主導し、改善提案や新しいアイデアは限られる | - 様々な部署や社員がデータを活用するため、アイデアや解決策の多様性が増す |
| 組織内のスキル | - データ分析スキルは限られた専門家に集中 | - 組織全体でデータ分析スキルが向上し、個々の能力が高まる |
| 競争力 | - 効率的な意思決定が遅れる可能性があるため、競争力に影響を及ぼす場合がある | - 競争優位性を高めるため、全社員がデータを活用して意思決定することで組織全体のパフォーマンスが向上 |
このように、「データの民主化」は単なるトレンドではなく、効率的で競争力のある組織を構築するための重要な戦略となっています。企業がデータを積極的に活用し、全社員がその力を引き出す環境を整えることが、今後の成功に繋がるのです。
「データの民主化」を支えるデータ基盤
データの民主化を進めるには、すべてのユーザーがデータにアクセスし、利用できる環境が必要です。
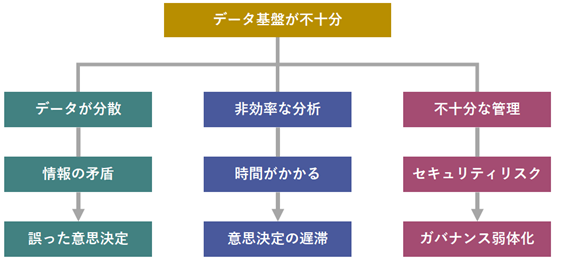
データ基盤が不十分な場合、データは複数のシステムやフォーマットに分散し、必要な情報を見つけることが難しくなります。この結果、データの整合性が欠け、異なるソースからの情報が矛盾することが増え、誤った意思決定につながるリスクが高まります。
また、分析作業が非効率になるため、迅速な意思決定が困難になります。さらに、データ管理が不十分なため、情報漏洩や不正アクセスといったセキュリティリスクが増加し、データ利用に関するルールが曖昧になることで、ガバナンスが弱体化し、コンプライアンスや品質管理も難しくなります。これらの問題は、ビジネスの成長や効率に大きな影響を及ぼします。
データ基盤は、その目的や企業の特性によってシステム構成が異なりますが、ノウハウの多くはすべての企業に共通して役立つと考えられます。特に、効果的なデータ活用を推進するための組織文化の醸成といったノウハウは非常に重要であり、全社的な活用を目指しているにもかかわらず、完成したデータ基盤がITスキルやデータリテラシーを必要とするものとなってしまう結果、多くの社員がその恩恵を受けられず、目的達成には程遠い状況が多く見られます。
データ基盤の「構築」がゴールではなく、むしろ構築後からが本当のスタートなのです。社員がデータを「活用」する部分こそ、その真価が試されると言えるでしょう。
「データの民主化」に取り組んだ企業の事例
株式会社セゾンテクノロジーでは、「データの民主化」、つまり全社員が自らの意思で自発的にデータを活用して業務を改善できる環境を目指すという目標を掲げ、全社データドリブンプロジェクトを発足しました。プロジェクトの一環として、「データを集め、溜め、探し、活かす」ための機能を全て搭載した基盤「データドリブンプラットフォーム」(以下、DDP)を構築しました。
プロジェクトの立ち上げから企画、構築、活用、定着までの過程や注意点、DDP活用の成果については、こちらの記事で紹介しています。
DDP プロジェクトでは、「業務の痛みを知る人の頭の中にこそ“真の要件”がある」と考え、プロジェクトの初期段階から業務部門の関係者に参画してもらいました。
エンジニアだけでデータ基盤を構築することも可能ですが、その場合、「集める」「溜める」が目的化し、本当のゴール達成が難しくなります。「真に使える」データ基盤を提供するためには、業務担当者への詳細なヒアリングを行い、必要かつ十分なデータを抽出することが不可欠です。しかし、日常業務に忙しい業務担当者の協力を得るためには、担当部門の責任者や経営者にも働きかけ、得られるメリットを具体的に示すなど、プロジェクト運営において工夫が求められます。
全社員が安心して利用できるデータ基盤にするために
「誰でも閲覧できる」とはいえ、フルオープンは避けるべきです。個人情報や契約上公開できないデータをどのように守るかは非常に重要です。ガバナンスの観点からアクセス制限を課しすぎると、データ活用の意欲が阻害される恐れがあります。
また、データ基盤を効果的に利用してもらうための仕掛け作りも重要です。すべての取り組みにおいて「データを社員の共有財産と捉え、価値を分かち合う」ことが意識されています。具体的には、データを活用してみようと思えるモチベーション向上施策として以下のようなことに取り組みました。
- ユーザーが迷子にならないような情報集約サイトの設置
- ユーザー向けの開発テンプレートやチュートリアルの整備
- 技術面で悩んでいる社員には教育や支援を施し、やりたいことの手助けをする
- 好事例やナレッジを共有し、ユーザー同士で「いいね」と称え合う文化を醸成する
データドリブンに立ちはだかる2つの壁
データドリブンプラットフォーム(DDP)を全社展開してから一年が経ち、利用者数は全社員の3割を超えましたが、当初の想定人数にはまだ達していません。この状況を「ユーザーの利用を鈍化させる課題があったはず」と捉え、ユーザーヒアリングを実施して原因を探ったところ、次のような課題が浮き彫りになりました。
- 普段の業務に忙殺され、ツールやSQLを学習する時間が取れない
- ツールがオーバースペック。もっとライトに自動化・可視化したい
- データが存在することは知っているが、欲しいデータを探せない
- 具体的なアクションにつながるような情報や事例が欲しい
- データをどこまで信用して良いのか分からない
-
これらの5つの課題を大別すると、以下の2つの壁が存在するということがわかります。
「データ活用スキルの壁」
「データを理解する壁」
です。

この2つの壁を突破するために、DDPプロジェクトでは「DDP 2.0」と題した新たな取り組みを開始します。DDP 2.0の目指す姿は以下のとおりです。
- ツールやSQLを知らなくてもデータを扱えるようにする(データ活用の壁の克服)
- ユーザーが望む情報(メタデータ)が提供されるようにする(データを理解する壁の克服)
全社データ活用を鈍化させる「2つの壁」を生成AIで突破
ユーザーの利用を鈍化させる2つの壁、「データ活用の壁」と「データを理解する壁」を突破するために、プロジェクトが着目したのが「生成AI」です。
セゾンテクノロジーが生成AIを用いて行ったアプローチを見ていきましょう。
「生成AI」でデータ活用の新たなステップへ
ChatGPT、Gemini、Claudeなどに代表される「生成AI」は、自然言語を理解し、文章や会話を作成する能力を持っています。
この「自然言語で問い合わせて回答を生成する」という特性を活用することで、データドリブンに立ちはだかる2つの壁「データ活用の壁」と「データを理解する壁」を突破できるのではないかと考えたのです。
しかし、生成AIはインターネット上に公開されているデータをもとにトレーニングされているため、トレーニングデータに含まれない特定の個人情報や、企業の機密データ、最新のリアルタイムデータなどに基づいた回答を得ることはできません。
この課題を克服するために用いられるアプローチが「RAG」と呼ばれる手法です。RAGとは「Retrieval-Augmented Generation」の略で、情報検索と回答生成を組み合わせた手法です。以下のプロセスで機能します。
- 1. 情報検索:ユーザーからの質問やリクエストに基づいて、関連する情報を外部データベースから検索します。
- 2. 回答生成:検索した情報をもとに、生成AIが自然言語で回答テキストを生成します。
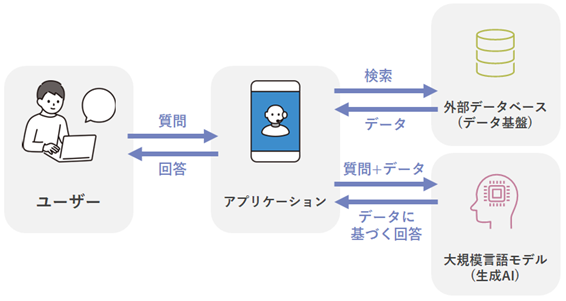
この手法により、AIが本来アクセスできない外部のデータ基盤に含まれる情報をもとに回答を生成できるようになります。その結果、回答は単なるモデルの知識に依存するものではなく、最新の情報やより関連性の高い情報に基づくものとなり、信頼性が向上します。
そして、RAGを使って2つの壁を超えるアプリケーションを開発したのです。
2つの壁を超えるアプリケーション
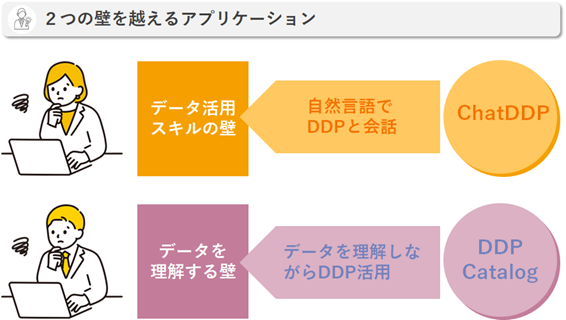
自然言語でデータ基盤にアクセスできる「ChatDDP」
まず「データ活用の壁」を突破するためには、ツールやSQLを知らなくてもデータを扱えるようにする必要があります。そのために、自然言語でデータ基盤にアクセスできる「ChatDDP」という仕組みを開発しました。
ChatDDPでは、ユーザーが自然言語で問い合わせを行うと、生成AIがその内容を理解し、必要なデータを特定します。そして、そのデータが格納されているテーブルから情報を検索するためのSQL文を生成します。このSQLが情報検索システムによってデータ基盤に対して実行され、生成AIが回答を作成するために必要なデータが取得されます。取得したデータは再び生成AIに送られ、自然言語での回答が生成されます。
これにより、ユーザーはSQLやツールを使うことなく、データ基盤に格納されているデータに基づいた信頼性の高い回答を得ることができるようになりました。
ChatDDP Demo
データを理解しながらDDPを活用するための「DDP Catalog」
次に「データを理解する壁」に対しては、「検索からアウトプットまでユーザーに寄り添い、対話しながらデータ活用をサポートする仕組み」が必要と考え、ChatDDPに続く第2の仕組み「DDP Catalog」の開発に着手しました。
DDP Catalogでは、データの所在や意味について自然言語で問い合わせると、関連するテーブルや項目情報のほか、そのデータをソースとするTableauダッシュボードや事例記事へのリンク、資料のURLなどが案内されます。
例えば、ユーザーが「パイプラインが分かるTableauはどこにありますか?」と問い合わせると、DDP Catalogはパイプラインを示すTableau CloudのURLを提示し、同時にTableauが参照しているデータや実行しているSQLを回答します。それに加えて、ユーザーは示されたSQLの一部を編集して再実行したり、データを手元にダウンロードしたり、そのデータを使ってグラフを生成するよう指示したりすることも可能です。
これにより、ユーザーはデータの格納場所やシステム上の項目名といった専門用語を意識することなく、生成AIが導き出した思考過程を検証したり、その思考に基づくパラメータを修正して新たな仮説を検証したりすることが容易になります。
DDP Catalog Demo
まとめ
本記事では、全社員でデータ活用を実現する「データの民主化」のために考慮すべき事項と、そのステップ、さらには「データの民主化」に立ちはだかる壁の乗り越え方について具体的な事例とともに紹介しました。
全社的なデータ活用によってビジネスの成長を達成するためには、データ基盤の構築がゴールではなく、構築後の活用こそが核となります。
セゾンテクノロジーでは、DDPプロジェクトにおける経験を基に、課題整理、効果確認、知識の蓄積を行い、その実体験に基づくノウハウをお客様にも提供しています。自社導入による経験と知見を活かし、お客様の課題を早期に発見し、効果的に解決します。
データ基盤の整備だけでなく、その活用と定着、さらには生成AIの導入を効率的に進めたいとお考えの方は、ぜひご相談ください。
執筆者プロフィール

細見 せいじ
- ・所 属:マーケティング部
- 都内のSierで約10年システム開発に従事したのち、2016年 アプレッソ(現:セゾンテクノロジー)にjoin。 データ連携ソフトウェアDataSpiderの開発エンジニア→プロジェクトマネージャーを経て、現在はマーケティング部でデータ利活用領域を担当。 システムエンジニア時代に培った IT システム活用経験をベースに、お客様の『データ利活用』『デジタル・トランスフォーメーション』を支援している。
- (所属は掲載時のものです)
おすすめコンテンツ


AI時代に注目が集まるデータ連携基盤のiPaaS。そんな時代のニーズに応える「HULFT Square(ハルフトスクエア)」の製品詳細をご確認ください。

データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!