HULFTの課題解決ソリューション|AIプロジェクトリーダー向け
“見やすい資料”は生成AIには読みにくい…
生成AIに誤解させない“伝わるデータ”の作り方
「見た目はきれいな資料なのに、AIの答えがズレてしまう」——そんな経験はありませんか?生成AIがデータ形式を正しく読み取れず、意図と異なる回答を返すケースが増えています。
本記事では、こうしたデータを生成AIにとって扱いやすい形式へと整形・変換することで、RAGの回答精度を飛躍的に高める実践的な前処理の工夫を紹介します。
なぜ生成AIは誤解するのか?
「この資料を渡せば、きっとAIが答えてくれるはず」——そう期待して生成AIに情報を読み込ませたにもかかわらず、返ってきたのは見当違いの答えだった。そんな経験はありませんか?
実はこの“ズレ”の多くは、AIの性能不足というよりも、「AIから見たときの情報の読みづらさ」に原因があります。人間にとっては視覚的に整った資料でも、生成AIにとっては意図がうまく汲み取れない“誤解されやすいデータ”であることが少なくありません。
たとえば、PDFファイルには表や段組み、見出しなど、視覚的な要素が使われます。しかし生成AIが受け取るのは、それを構成する文字情報だけ。そこに表の意味や構造、段落の区切りといった文脈は存在せず、テキストの羅列として解釈されてしまいます。その結果、「関連情報が飛び飛びに読まれる」「同じ意味の語句が重複・混在する」「文書の意図が伝わらない」といった事態が起こるのです。
また、HTMLのように構造が明確なフォーマットであっても注意が必要です。生成AIはプログラムではなく言語モデルであり、タグの意味を機械的に処理するのではなく、自然言語として“解釈”しようとします。そのため、複雑なレイアウトや過剰な装飾、無意味なタグが多く含まれると、文脈を見失ってしまうリスクがあります。
生成AIはあくまで「読み物」としてのテキストを前提に学習されています。したがって、平易なデータ構造、意味の通る文の流れ、余計な装飾のない情報が与えられるほど、本来の実力を発揮します。
資料自体に問題があるわけではありません。人間にとっては見やすく丁寧に作られたコンテンツでも、それが「AIにとって読みやすい」とは限らない——。このギャップを理解することが、生成AI活用における第一歩なのです。

RAGの精度を左右する「前処理」の重要性
生成AIに情報を与える際、どのような形式でデータを渡すか——それがRAGの精度に大きく影響します。いくら高性能なAIを使っても、読み取りづらいデータでは期待する答えは得られません。
RAGは、質問に対して外部の文書を参照しながら回答を生成する仕組みです。そのため、参照元となるデータが適切に整理されていなければ、検索精度も回答生成精度も低下してしまいます。重要なのは、どんな情報を、どのような単位で、どのような形にしておくかという「前処理」の工程です。
単にPDFをテキスト化するだけでは不十分です。段落の区切り、表の意味づけ、見出しと本文の関係など、AIが文脈を理解しやすくなるような工夫が求められます。
つまり、前処理とはAIにとって“読解しやすい状態”を整える作業です。この工程を丁寧に行うことで、RAGの性能を最大限に引き出すことができます。
ファイル形式ごとに異なる「読みづらさ」とその対策
生成AIに正確な回答を出させるには、与える情報が「AIにとって読みやすい形式」になっていることが重要です。ところが現実には、業務で使われる多くのファイルがAIには読みづらい構造を持っており、それぞれに応じた前処理が必要になります。
- PDFファイル
たとえば、PDFには、紙で保管されていた契約書などをスキャンした画像PDFが含まれます。こうしたファイルはテキスト情報を持たないため、OCRによって文字を抽出し、テキスト形式に変換する必要があります。
- 画像ファイル
JPEGなどの画像ファイルも、ホワイトボードの写真や手書きの議事録など、重要な情報を含みます。こちらもOCRで文字を抽出し、意味のある形で出力する必要があります。
- 音声ファイル
音声ファイル(MP3など)には、会議やインタビューなどの内容が記録されていますが、AIにとっては「何も書かれていない」状態です。音声を文字起こししてから前処理を行うのが一般的です。
- HTMLファイル
HTMLはWebページや社内ポータルで使われますが、タグやリンク、特殊文字などが多く含まれており、ノイズが多く検索効率が下がりがちです。タグや記号を除去し、マークダウンなどのシンプルな形式に整えることで、RAGでの活用がしやすくなります。
- Excelファイル
Excelは構造化された表形式のデータを扱えますが、内容を理解するには列と列の関係性も踏まえて読む必要があるため、AIが正しく意味を理解できません。前処理でフラットな構造のQ&A形式に変換することで、より精度の高い検索・回答が可能になります。
- JSONファイル
JSONはECサイトや外部サービスから取得したデータに多く使われますが、階層構造が深いため、情報の分割や検索が難しくなります。CSVに変換してフラットな構造にすることで、扱いやすいナレッジに変換できます。
- XMLファイル
XMLも同様に階層が複雑で、医療や金融、行政などの業界標準フォーマットとして広く使われていますが、そのままではRAGに向きません。CSVへの変換によって、検索性と汎用性が格段に向上します。
- その他マニュアル類
また、業務マニュアルや製品マニュアルのように情報量が多いファイルは、非構造化のままだと検索精度が上がりません。こうした文書は、Q&A形式に変換し、CSVなどで構造化することで、RAGでの活用精度を大きく高めることができます。
- ベクトル化(エンベディング)
そして、もうひとつ重要なのがエンベディングです。これは、前処理を終えたデータをRAGに取り込むために、AIが扱える「数値ベクトル」に変換する工程です。インプットされたテキストや構造化データは、そのままではベクトルDBに格納できないため、エンベディング処理によって意味の近さを数値として表現する必要があります。
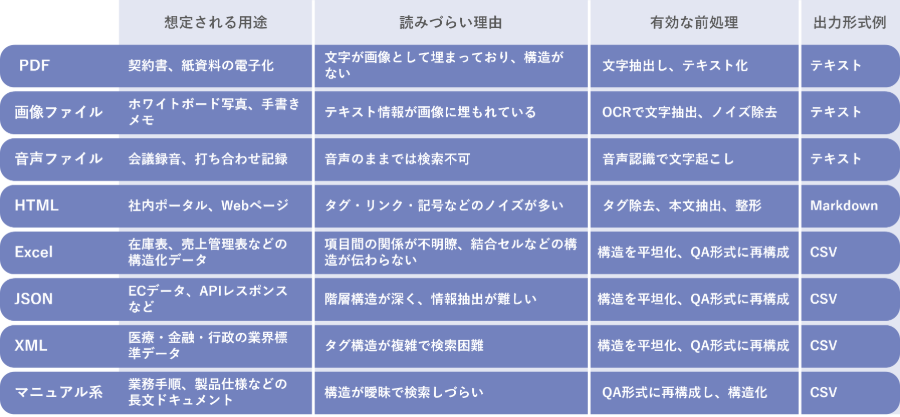
このように、ファイルごとに異なる特性と課題を理解し、それに合った前処理を行うことで、“人にとっての資料”を“AIが理解しやすいデータ”へと変換できます。RAG活用までを見据えた前処理の工夫が、生成AIの回答精度を大きく左右するのです。
実装のハードルをなくし、AI活用を加速する「前処理の型」
前章で紹介したような前処理は、理解すればするほど「自分たちでやるには難しい」と感じるかもしれません。画像から文字を読み取ったり、HTMLのノイズを取り除いたり、非構造化データをQ&Aに変換したり──ひとつひとつは実践的ですが、手作業やスクラッチ開発で対応するには限界があります。
こうした課題に対し、HULFT Squareでは、よくある前処理を“使えるかたち”でパッケージ化したアプリケーションを提供しています。これらは、生成AIやデータ処理機能を活用した実用的なテンプレートで、ノーコードでそのまま利用できるのが特長です。
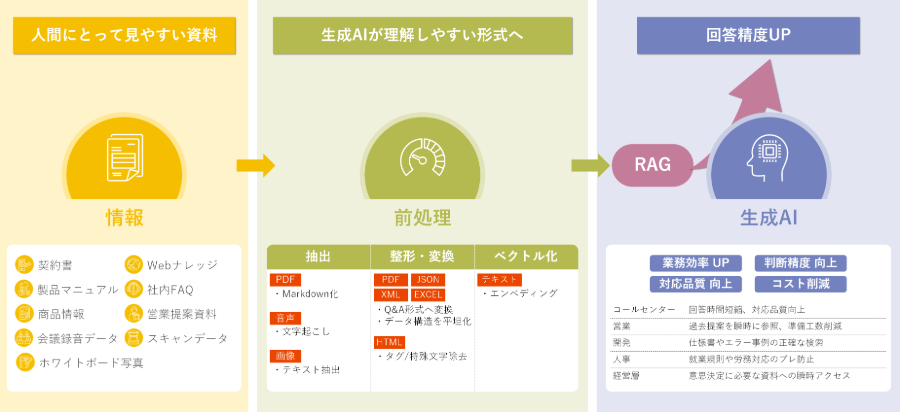
具体的には、以下のような処理を提供します。
| データ | 用途 | ニーズ | 処理内容 | アプリケーション |
|---|---|---|---|---|
| PDFファイル | 契約書、紙資料の電子化 | スキャンPDFのままでは人の目でしか確認できないため、テキスト抽出して取り込みたい | テキスト抽出 | AI前処理 PDFからテキスト抽出 |
| マニュアル、手順書 | PDFファイルはのままでは検索精度が低いので、構造化データに変換して取り込みたい | Q&A形式への変換 | AI前処理 PDFからQA表作成 | |
| 画像ファイル | ホワイトボード写真、手書きメモ | ホワイトボードの撮影写真や手書きメモなどは、画像からテキスト抽出して取り込みたい | テキスト抽出 | AI前処理 画像からテキスト抽出 |
| 音声ファイル | 会議録音、取材録音 | 会議の録音データなどは、音声をテキスト化して取り込みたい | テキスト抽出 | AI前処理 音声からテキスト抽出 |
| HTMLファイル | 社内ポータル、Webページ | HTMLタグや特殊文字、記号などがノイズになるため、それらを削除して取り込みたい | HTML タグの削除 | AI前処理 HTMLタグの削除 |
| 特殊文字、記号の削除 | AI前処理 特殊文字・記号の削除 | |||
| Excelファイル | 在庫表、売上管理表 | そのままでは回答精度が低いため、フラットなデータ構造に変換して取り込みたい | Q&A形式への変換 | AI前処理 ExcelからQA表作成 |
| JSONファイル | ECデータ、APIレスポンス | 階層構造が複雑でチャンク分割が困難なので、フラットなデータ構造に変換して取り込みたい | Q&A形式への変換 | AI前処理 JSONからQA表作成 |
| XMLファイル | 医療・金融・行政など業界標準フォーマット | 階層構造やタグが複雑で検索精度が低いため、フラットなデータ構造に変換して取り込みたい | Q&A形式への変換 | AI前処理 XMLからQA表作成 |
| テキストデータ | すべての整形済みデータ | ベクトルDBに格納するために、数値ベクトルに変換したい | エンベディング | AI前処理 エンベディング&ベクトルDB格納 |
これらのアプリケーションは、HULFT Squareをご契約中のお客様であれば無償でご利用可能で、現在は一部が公開済み、今後も順次追加を予定しています。
このように、再現性の高い前処理を誰でもすぐに使える状態にしておくことで、生成AI導入プロジェクトの立ち上がりが加速し、PoCの成果検証も短期間で実現可能になります。データ加工の属人性を排除することで、チーム全体の生産性と品質を安定させることにもつながります。
AIプロジェクトを「実験」に終わらせず、業務で成果を出すフェーズへと確実に進めていくうえで、前処理の標準化は極めて重要な鍵になります。
整形前と整形後で、AIの答えはどう変わるか
これまで説明してきた前処理の効果を、実際の検証データで裏付けます。社内実験にて、データをそのままAIに渡す場合と、前処理でQA化やフォーマット変換を行った場合の回答精度を比較しました。
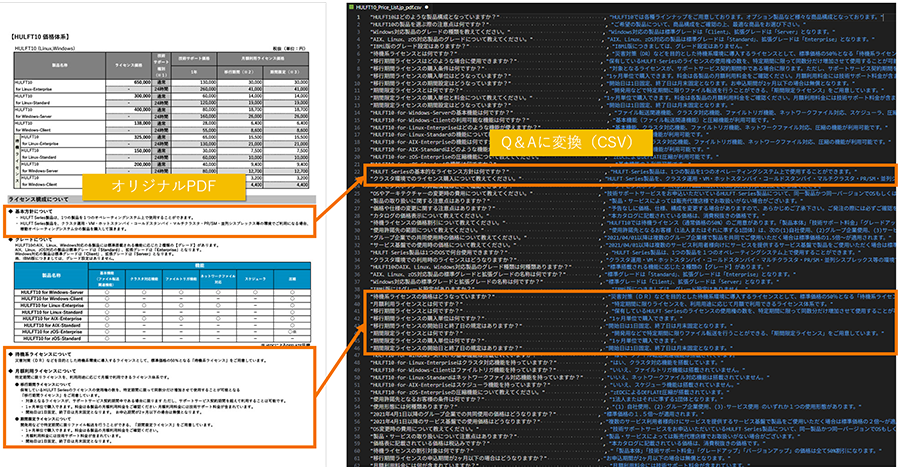
事例1:PDF価格表のQA化による精度向上
HULFT10の価格表を題材に、
a) PDFのまま読み込み
b) Q&Aに分解してテキスト形式で読み込み
の2パターンで10件の質問を3種類の大規模言語モデル(LLM)に投げて正答率を比較しました。
結果は全てのモデルで顕著な精度向上を示し、QA化によるデータ整形が回答の正確性を大きく高めることを実証しました。
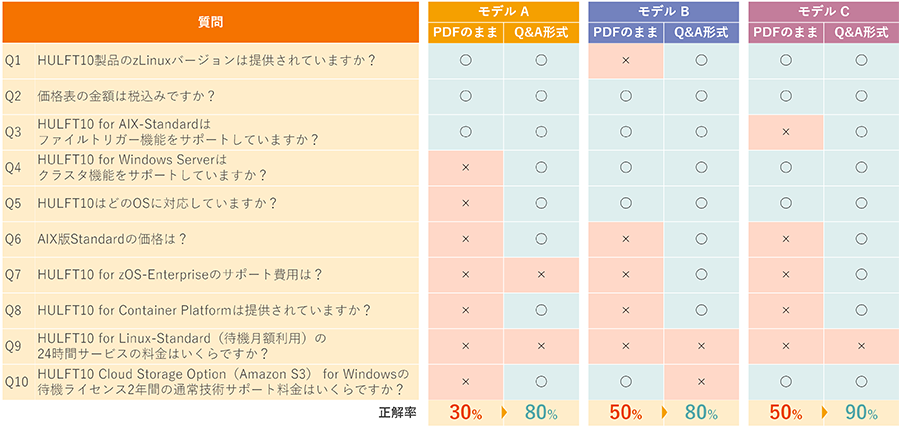
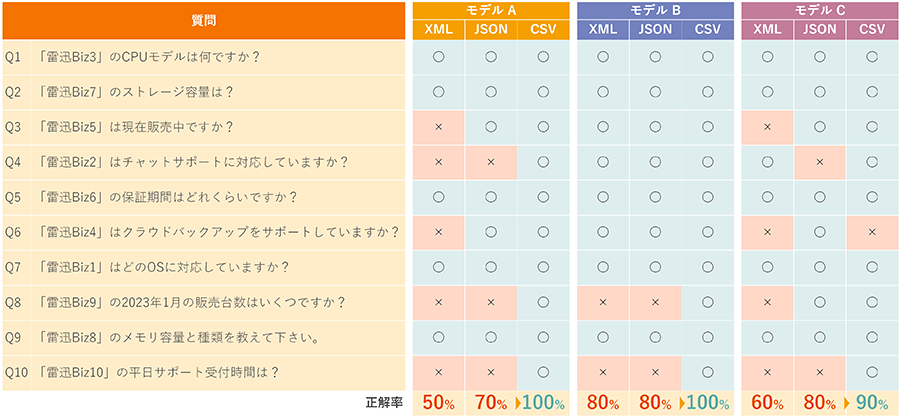
事例2:XML・JSON・CSV形式での回答精度比較
架空の商品データをXML、JSON、CSV(Q&A分解化)の3形式で準備し、3種類のLLMに10件の質問を投げて比較しました。

結果、CSVにQA化したデータが全体的に最も高い正答率を記録し、複雑な階層構造を持つXMLやJSONよりも単純化されたCSV形式の方がAIが理解しやすいことが分かりました。
まとめ
本記事では、生成AIの回答精度を高めるために不可欠な「データ前処理」の重要性を解説し、ファイル形式ごとの読みづらさの理由とその対応策を具体的に紹介しました。さらに、実際の検証データを通じて、前処理による回答精度の向上を数値で示し、その効果を裏付けました。
実際の検証では、HULFT Squareアプリケーションを活用することで、手間のかかるデータ整形作業を効率的に行うことができ、プロジェクト推進の負担軽減に役立てられることが分かりました。こうした前処理の考え方や方法は他のツールや仕組みでも実践可能であり、ご自身の環境やニーズに応じて取り入れていただけます。
今後も、より多様なデータ形式や複雑な業務要件に対応する前処理の技術やノウハウが発展していくことが期待されます。生成AIの活用を進める上で、こうした基盤づくりや準備が、質の高い成果を生む大きなカギとなるでしょう。
本稿が、皆様のAIプロジェクトの一助となり、より効果的な活用につながることを願っております。
ご参考)生成AI導入に関するご相談も承っています
セゾンテクノロジーでは、生成AIの業務活用に向けた導入支援や、データ前処理をはじめとする基盤整備のご支援を行っています。
「社内にある情報をAIで活用したい」「PoCを始めたいが何から手をつけるべきか分からない」といったご相談も含め、お気軽にご連絡ください。
ご相談・お問い合わせはこちら
https://www.hulft.com/service/hulft-square/inquiry


