データ基盤とは?
社内外のデータを統合し活用を牽引
あらゆるビジネスでデータの重要性が増す中、複数のシステムや部門に分散したデータを統合的に管理する仕組みを持つことは、もはや不可欠です。これを一体的に支え、ビジネスに活かせる形で活用するのがデータ基盤です。
本記事では、データ基盤の基本的な概要や構築の必要性、主要な構成要素までを総合的に解説します。
さらに、成功事例を踏まえ、データ基盤構築において重要となるポイントを整理していきます。社内外のデータを統合し、組織的なデータ活用を牽引するための知見をぜひ参考にしてください。
![]() M.Takahashi
- 読み終わるまで 5分
M.Takahashi
- 読み終わるまで 5分

データ基盤とは
企業活動で生まれるデータは、営業や顧客管理、製造現場のセンサー情報など多岐にわたります。
データ基盤とは、企業や組織が多様なデータを統合的に収集・蓄積・加工・分析するためのシステムや技術の総称です。複数のシステムや部門に分散したデータを効率的に集約し、一元的に利用できる土台として機能します。経営層から現場担当者まで、同じデータセットを参照できるようになるため、部門を超えた連携や意思決定のスピードを格段に向上させる効果が期待できます。
なぜデータ基盤が必要か
データは意思決定の軸となる貴重な資産です。大量のデータを迅速かつ正確に分析できれば、新商品やサービスの開発に役立つ洞察を得られるでしょう。データ基盤がもたらすメリットを、データ活用の加速、業務効率化とコスト削減、データ品質の向上と一元管理の3つの観点から解説します。
データに基づく施策の立案
データを一覧できる環境が整備されると、新しい分析手法やツールを迅速に導入しやすくなります。すべてのデータが集まることで、クロス分析や高度な機械学習モデルの構築もスムーズに行えます。
例えば、顧客データと販売データを横断して分析することで、顧客セグメントごとの購買傾向が明らかになり、新製品のターゲット設定やマーケティング施策の精度が高まります。データ基盤があることでこうした作業が効率よく実行できるのです。
業務効率化
統合されたデータを活用することで、同じデータを重複して管理する無駄が減り、さまざまな部署同士が共通のデータを共有しやすくなります。その結果、レポート作成などの業務時間を大幅に削減することが可能になります。
また、分析ツールやレポート作成の標準化を進めると、ツールのライセンス費用や運用コストもまとめて管理しやすくなります。これにより、長期的な視点でコストを抑えながらデータ活用を推進することが可能となります。
データ品質の向上と一元管理
データの入力ミスや重複を監視する仕組みを持つことで、データ品質が向上します。統合されたデータベースやデータウェアハウスを使用すれば、自動的にバリデーションをかけることも容易です。
特に顧客情報など機密度の高いデータにおいては、セキュリティ面でも集中管理によるメリットがあります。アクセス権限の管理を一元化できるため、組織全体のコンプライアンスやガバナンスに寄与しやすくなるでしょう。
データ基盤の主要構成要素
データ基盤は、収集から保存、分析に至るまでの一連のプロセスを支える複数の要素によって成り立っています。ここでは、データ収集、データ蓄積、データ加工、データ管理、そして分析や可視化といった主要な構成要素に注目します。
これらの要素は相互に連携し、データを活用できる形に整備するのが大きな役割です。将来の増加を見越してスケーラブルであることが、企業の成長を下支えするデータ基盤のあり方と言えます。
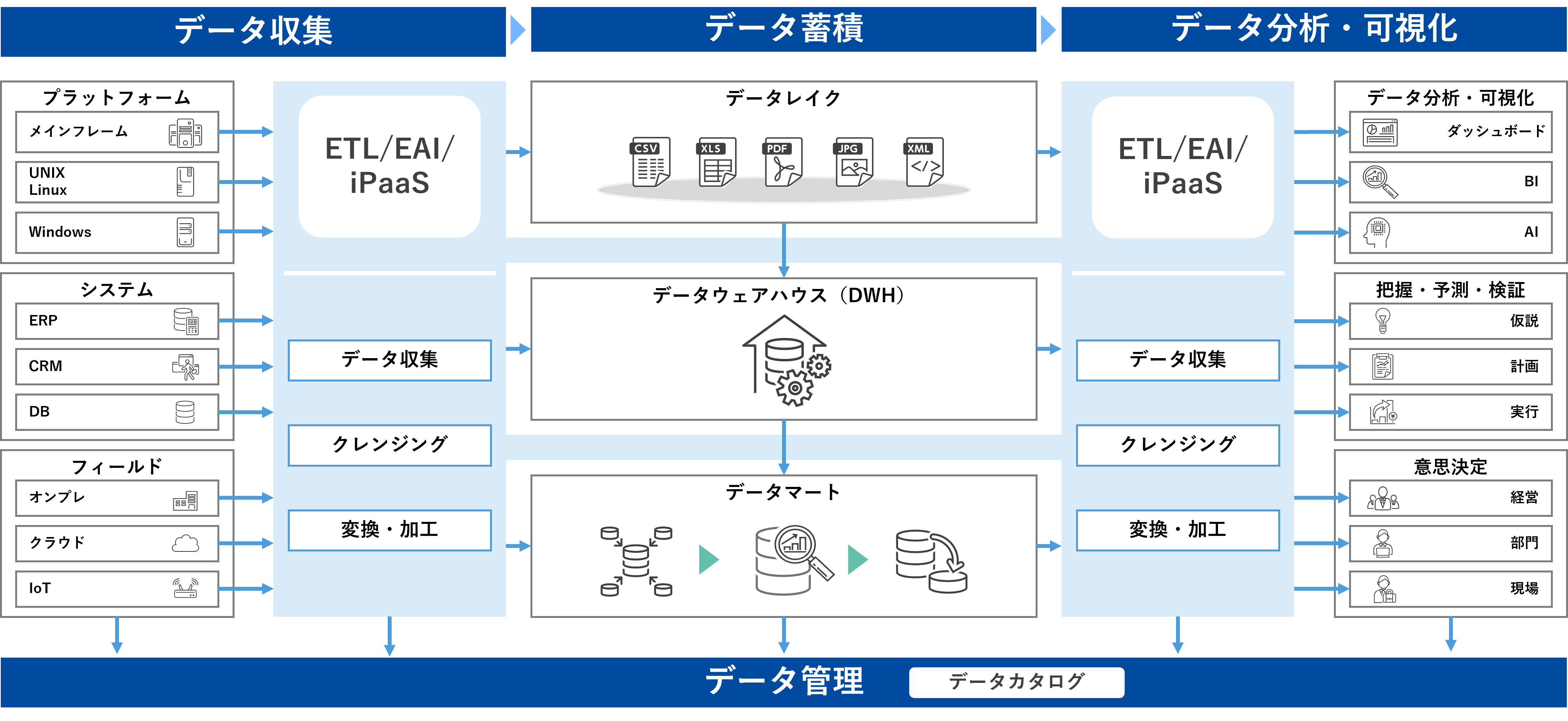
それでは、各構成要素を順に見ていきましょう。
データ収集
センサー情報やWebサイトの行動履歴、社内の基幹システムなど、多種多様なソースからデータを取得し、一元化する工程がデータ収集です。ここで鍵となるのは、データを効率的かつ安定的に取り込む仕組みを構築することです。データ取得が不安定だと、分析結果に悪影響を及ぼし、基盤全体の信用性が損なわれてしまいます。
データを取り込む際に意識すべき点として、接続方法とデータ形式の統一があります。企業のデータは、オンプレミス、クラウド、SaaSなどに分散していることが多く、API経由で取得できるものやファイルとして取得するものなど、さまざまなパターンに対応する必要があります。そのようにデータの取得方式や形式が異なる場合でもスムーズに統合でき、増え続けるデータソースにも柔軟に対応できるように、ETL(Extract/Transform/Load)やiPaaS(Integration Platform as a Service)等のデータ連携ツールを活用するケースが一般的です。ETLやiPaaS等のデータ連携ツールの違いについては、以下の記事でご解説しています。
-
▼データ連携ツールの違いについて知りたい
⇒ 「システム連携とは?自社に最適な連携方法の選び方をご紹介」
データ蓄積
集めたデータを保管する場所としては、データレイクやデータウェアハウス、データマートが一般的に利用されます。これらの違いについて以下に説明します。
データレイク
データレイクは生データ(構造化データ、半構造化データ、非構造化データを含む)をほぼそのまま蓄積する目的で使われます。データ形式を問わずに保存できるため、あらゆる種類のデータを蓄積できます。
主なデータレイクサービス:Amazon Simple Storage Service (Amazon S3)、Azure Data Lake Storage、Google Cloud Storage、Snowflake
-
▼データレイクについてもっと詳しく知りたい
⇒ データレイク|用語集
データウェアハウス(DWH)
データレイクに蓄積された生データを分析やレポーティングのために構造化し、蓄積する目的で使われます。データを投入する段階で、データの加工処理が必要となる場合がほとんどです。
主なデータウェアハウスサービス:Amazon Redshift、Microsoft Azure Synapse Analytics、
-
▼データウェアハウス(DWH)についてもっと詳しく知りたい
⇒ DWH|用語集
データマート
データウェアハウスから特定のビジネス部門(例えば、マーケティング、人事、財務など)に関連したデータを抜き出して蓄積したものです。特定のビジネスニーズに焦点を当て、部門の日常業務や分析業務をサポートするために利用されます。
上述したデータウェアハウスサービスでは、一般的にデータの抽出・整理を備えており、データマートを作成することができます。
オンプレミスかクラウドか
データ基盤を構築・運用するにあたり、自社のオンプレミス環境とクラウドのどちらが最適かを選択します。オンプレミスに構築する場合、システムを正確にサイジングすることが重要になりますが、データ基盤は将来取り扱うデータがどれくらい増えるか予測が難しく、初期段階で正確にサイジングすることは困難です。
よって、ビジネスの成長に合わせて柔軟にリソースを追加・削除でき、初期投資が抑えられる、クラウドベースのマネージドサービスが主流となっています(「主なサービス」として挙げたサービスもこれに該当します)。クラウドベースのマネージドサービスでは、アップデートも自動的に行われるため運用負担が軽減され、常に最新の技術・環境を利用できることもメリットとして挙げられます。
-
▼オンプレミスについてもっと詳しく知りたい
⇒ オンプレミス|用語集
データ加工
収集・保管された生データを実際に分析可能な状態に変換するプロセスを担当するのが、データ加工・処理の領域です。抽出段階で必要なデータを分離し、変換段階でクレンジングやフォーマット変換を施し、最終的にデータウェアハウスなどに格納します。このプロセスをしっかりと確立することで、データの品質と一貫性が向上し、分析作業を効率化することができます。特に変換時にエラー検出や重複除去を行うことで、後続の分析で誤った結果を出さないようにすることが重要です。
データ管理
膨大な量のデータを保有する企業では、データの検出や分析、データそのものの信頼性に問題が生じがちです。企業や組織が保有しているデータ資産を整理、分類、管理するための仕組みとして利用されるのがデータカタログです。データの属性や特性を定義するデータをメタデータといい、データカタログは、そのメタデータを管理する目録といえます。
メタデータには、各データの構造や属性、作成日時、作成者などが記述されています。そのため、データカタログを用いれば、必要なデータの所在を容易に検出し、データの利用や共有、保護などを実現できます。
-
▼データカタログ製品について詳しく知りたい
⇒ 散在したメタデータを収集・整理・カタログ化。「HULFT DataCatalog」
データ分析と可視化
最終的に、ビジネス価値を生み出すのはデータから得られる示唆や洞察です。可視化と分析は、データ基盤により整備されたクリーンなデータをどのように活用するかの要となります。
BI(Business Intelligence)ツールは、多様なデータセットから必要な指標を抽出し、グラフやレポートにまとめるソフトウェアです。プログラミングスキルがなくても扱える製品が増えており、幅広い従業員がデータを活用する土台を提供します。
データ分析を成功させるためには、ビジネスドメインに対する理解も欠かせません。グラフやレポートにまとめて可視化することがゴールではなく、分析結果をどう解釈し、どのようなアクションにつなげるかをチーム全体で共有する仕組みが必要です。
成功するデータ基盤構築の秘訣
データ基盤は技術要素だけでなく、社内体制や運用プロセスを含めた総合的な取り組みが重要です。特に、導入後の運用をいかに定着させるかが成果を左右すると言っても過言ではありません。
それぞれの部署が利用したいデータや分析内容を明確にしておくことで、要件定義がスムーズになり、導入後に活用が進みやすくなります。あわせて、セキュリティ対策やガバナンスを強化することで、データの信頼性を高めることも欠かせません。

導入事例から学ぶ成功のポイント
他社の成功事例では、プロジェクトの初期段階から経営層と各現場の目線を合わせ、明確なKPIを設定し、結果を定期的に共有していることが多いです。要件定義を明瞭化し、運用体制を確立したうえでスモールスタートするなど、段階的に拡張するアプローチも効果的です。
成功事例の企業では、まずは一つの部署や課題に絞り込んでデータ基盤を利用し、早期に成果を得ることで社内での理解と賛同を得ています。その後段階的に範囲を拡大していくことで、大規模な投資リスクを抑えつつ着実にデータ活用を進めています。
一方、導入目的があいまいで「とりあえずデータ基盤を構築しよう」といった方針だけが先行し、現場ニーズと乖離した結果、システムが形骸化してしまうケースが見られます。こうした失敗を防ぐには、導入目的を明確化し、運用体制や利用計画をしっかりと固めることが重要です。
まとめ
データ基盤は、企業内外の膨大なデータを統合し、ビジネス価値を生み出すための基礎となる仕組みです。ビッグデータ時代には欠かすことのできない存在となりつつあり、これを活かせるかどうかが企業の競争力を左右します。
構築のステップでは、目標設定と要件定義、ツール選定から実装、そして運用・改善に至るまで、一貫性のあるプロセスを築く必要があります。途中の段階で経営層を含む社内関係者と連携を密に取りながら、段階的に拡大・改善していくことが成功への近道です。
他社の成功事例を参考にしながら、自社に最適なデータ基盤を築き上げて、さらなるビジネス拡大を目指していただければ幸いです。
執筆者プロフィール

M.Takahashi
- ・所 属:マーケティング部
- セゾンテクノロジーに入社後、HULFTをはじめとしたデータ連携製品事業に従事。パートナーセールス、カスタマーサポートなどを経て、現在はマーケティングを担当。データ連携の重要性や最新情報を発信しています。
- (所属は掲載時のものです)
おすすめコンテンツ


AI時代に注目が集まるデータ連携基盤のiPaaS。そんな時代のニーズに応える「HULFT Square(ハルフトスクエア)」の製品詳細をご確認ください。

データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!