メタデータとは?基礎から最新動向までFAQ形式で解説
メタデータは、データを定義・管理し、効率的に活用するために不可欠な概念です。
例えば、書籍であればタイトルや著者などがメタデータにあたり、写真や音楽などのコンテンツにも、撮影日やジャンルといった付加情報が存在します。こうしたメタデータはデータ検索や再利用を容易にし、必要な情報を素早く見つけるのに役立ちます。
本記事では、メタデータに関する情報をまとめました。組織全体でメタデータを一貫して管理する体制を整え、効率的な情報活用の実現にお役立てください!
 Yumi Ogawa
-読み終わるまで 7分
Yumi Ogawa
-読み終わるまで 7分

Q1. そもそもメタデータとは何ですか?
Q2. メタデータにはどのような種類がありますか?
- 記述的メタデータ:データを説明するための属性情報。タイトル、作成者、要約などコンテンツに関する基礎情報を整理して管理することが目的です。データの検索性や可視化を高めるうえで、特に役立ちます。
- 構造的メタデータ:データの構成、階層、関連性を示す。データを横断的に活用したい場合、構造的メタデータの整備が特に重要です。
- 管理用メタデータ:保存形式、アクセス権、更新履歴などの情報。組織の内部統制を強化する意味でも、見落とせない要素です。
- 保存用メタデータ:データの保存期間や移行先の場所など、アーカイブやバックアップのために付加される情報。情報ライフサイクル全体を俯瞰し、適切な維持管理を行うために欠かせないものです。
- テクニカルメタデータ:ファイル形式、エンコード情報、ストレージの場所など、データファイルの技術的な詳細情報。システム変更やアップグレードにも対応しやすくなる利点があります。
- ビジネスメタデータ:ビジネスルールや用語集など、業務の運用方針・手続きなどを定義した情報。例えば「顧客」や「商品」という用語の定義を明確にすることで、組織内のコミュニケーションを円滑にし、データ活用における誤解を防ぎます。
Q3. メタデータはどのような場面で使われていますか?
- 検索エンジンによるページ理解
- データベースの設計と管理
- データベースの設計と管理
- 企業の情報ガバナンスや監査対応
- メディアアーカイブ(画像・動画)
なぜ企業や組織でメタデータが注目されているのか、その理由を説明します。
膨大なデータを正しく管理し、有効活用するには、データそのものだけではなく、それを表すメタ情報も整備する必要があります。例えば、急速に増大するビッグデータ環境では、どのデータをどのように使うべきかを判断する手掛かりがなければ、せっかくの資産を活かせません。メタデータを活用すれば、データの検索・再利用が容易になり、分析やレポーティングといったビジネス活動のスピードと質を高められます。
Q4. メタデータは誰が、いつ作成するものですか?
- 自動的に生成されるもの(カメラのExif情報など)
- 作成者が手動で付加するもの(論文の著者情報、商品情報など)
- システム管理者やデータガバナンス担当が整備・管理するもの
があります。
Q5. メタデータが不足していると、どんな問題がありますか?
- 必要なデータを見つけられない
- データの意味がわからない
- 用や再利用ができない
といった問題が発生し、データの価値を活かせなくなります。
Q6. メタデータとマスターデータの違いは何ですか?
- メタデータはデータそのものの情報(属性・構造・履歴)に関する情報
- マスターデータは業務の基幹情報(顧客、製品、社員などのデータの本体)
役割や目的が異なり、マスターデータの「意味づけ」を助けるのがメタデータとも言えます。
Q7. メタデータ管理を効率化するにはどうすればよいですか?
- 専用のメタデータ管理ツール(データカタログなど)の導入
- 明確な命名ルールと記述フォーマット
- データスチュワードなどの責任体制の整備
が効果的です。
メタデータ管理の基本プロセス
上記7つのFAQを踏まえ、次にメタデータを管理するうえで押さえておきたいプロセスをステップごとに紹介します。
メタデータの管理は、戦略立案から日常的な運用まで、段階を踏んだプロセスが求められます。これらのプロセスを体系的に整備することで、組織のデータリソースを最大限に活用できる環境が整います。各ステップでの最適な方法を知り、継続的に改善していくアプローチが肝心といえます。
メタデータ戦略の策定
組織のビジネス目標や伊達指標を考慮しながら、メタデータ管理の全体像と運用方法を計画する段階です。どの部門が主導するのか、どの程度の予算と人員を割くのかなど、重要な意思決定が行われます。ここでの方向性が明確でないと、後のステップでは管理対象や範囲が曖昧になりがちです。
メタデータ要件の把握
次に、実際にどのような情報をメタデータとして収集・管理するのかを明確にします。データ利用者が求める属性や業務フローで必要とされる観点などを総合的に洗い出すのがポイントです。的確に把握できれば、過不足のないメタデータ管理が実現しやすくなります。
メタデータを整理するうえで、必須項目を明確にしておくと無駄のない運用を実現できます。メタデータを記述する際に最低限押さえておきたい項目は以下の通りです。
- ◎データ名
- ◎データ型
- ◎ユニークID
- ◎作成日
- ◎更新日
- ◎著者または担当者の情報
- ◎データの説明
メタデータの作成
要件を踏まえたうえで、メタデータを実際に記述・収集します。データカタログやスキーマ設計ツールなどを活用して、形式を統一しながら管理することが一般的です。ここでの作業精度が後続の運用フロー全体に影響するため、専門知識をもった担当者が関与することが望ましいです。
メタデータの品質管理
メタデータが最新かつ正確であるかを定期的に監査し、レビューを行います。更新漏れや重複、誤字脱字などの問題を早期に発見して修正することで、データ活用の信頼性を高められます。特に組織規模が大きい場合は、メタデータを定期的に点検する仕組み作りが重要です。
メタデータの継続的な運用・保守
最後に、メタデータの更新やアクセス管理、運用ツールのバージョンアップなどを日常的に行うフェーズです。データの増加や業務の変化に合わせてメタデータも変化していくため、継続的な見直しが求められます。ここをおろそかにすると、せっかく構築した管理体制が機能しなくなるおそれがあります。
メタデータ管理における標準とスキーマ
メタデータの国際標準やスキーマについて知ることで、より互換性の高い運用が実現できます。
企業や組織がメタデータを扱う際、標準化されたスキーマや国際規格を活用することで運用効率が飛躍的に向上します。特に、地理情報や図書館情報学の分野では、既存の規格が多岐にわたり、相互運用性を担保するために活用が推奨されます。こうした国際標準を取り込むことによって、異なる組織やシステム間でのデータ連携がスムーズになります。
-
▼データ連携についてもっと詳しく知りたい
⇒ データ連携 / データ連携基盤|用語集

ISO 19115
地理空間情報を取り扱う際に用いられる国際標準で、地理データの品質や内容を共通フォーマットで表現する役割を担います。GISデータの相互利用や共有が必要な際、ISO 19115を導入しているとデータのメタ情報が整合しやすくなります。大規模な地理情報プロジェクトほど、その恩恵は大きいといえます。
JMP(Japan Metadata Profile)
ISO 19115をベースに、日本国内の利用状況や文化に合わせてカスタマイズされたプロファイルです。日本の行政機関や公共事業でGISを導入するときに使われるケースが多く、国内の標準として認知されています。ISO 19115との互換性をもちながら、より運用しやすい設計が特徴です。
その他の国際標準やスキーマ
一般的な文書に対してはDublin Coreが広く用いられており、論文等の引用データ管理ではDataCiteなどが利用されています。これらの国際標準を導入することで、他システムとのデータ連携を容易にし、グローバルに共通言語を持つことが可能になります。自社や自組織のデータ特性に合う標準を選択することが大切です。
メタデータを活用するメリット
メタデータを組織的に管理し、活用することで得られる具体的な利点を紹介します。
メタデータを体系的に整備すると、単なるデータ管理の効率化にとどまらず、業務全体の生産性向上やセキュリティ強化、システム運用の最適化など幅広いメリットを享受できます。組織の成長戦略やDX推進の一環として、メタデータの活用スキルを早期に確立しておくと、データ駆動型のビジネスモデルへスムーズに移行できます。
データ活用効率の向上
メタデータによってデータの所在や意味合いが整理され、必要な情報をすぐに参照できるようになります。分析のベースとなるデータを迅速に見つけ出すことができ、重複作業も減らすことが可能です。結果的に、データ分析のサイクルが短縮され、組織のスピード感を高めます。
データセキュリティの強化
アクセス権やログ情報などをメタデータとして管理しておけば、誤ったデータ流出や不正利用を防止しやすくなります。監査ログを活用すれば、万一のインシデント発生時でも対応がスムーズです。特に個人情報や機密情報を扱う業界では、メタデータによるセキュリティ対策が必須となります。
システム開発・運用の最適化
メタデータの整備は、新規システム開発や既存システムの拡張においても大変有用です。必要なデータの仕様や構造を正確に把握しやすくなるため、要件定義や設計フェーズでのミスが減り、実装コストを削減できます。運用フェーズでも、変更やトラブル発生時に迅速かつ的確な対応が可能になります。
メタデータの最新動向
AI時代の到来により、メタデータは単なる“データのデータ”という役割を超え、“データ活用の原動力”へと進化しています。
最後に近年注目されている3つの最新動向を紹介します。
Ingest-Native AI:取り込み時点での自動メタデータ生成
これまでメタデータの作成は、コンテンツ制作後に人手で行うか、ツールによる後処理が一般的でした。しかし近年、「Ingest-Native AI」と呼ばれるアプローチが注目されています。
これは、映像や音声コンテンツの取り込み(ingest)段階でAIを介在させ、自動的にタグや説明文などのメタデータを生成する技術です。
たとえば、欧州のメディア企業 DPG Media は、Amazon BedrockやAmazon Transcribeといった生成AIサービスを活用し、以下のような自動処理を実現しました:
- 動画の音声から登場人物名・話題のキーワードを抽出
- ジャンルやムードなどを分類
- 生成されたメタデータをそのままアーカイブ検索に利用
この取り組みにより、動画編集や配信のワークフローが大幅に効率化され、人的工数が大きく削減されたと報告されています。
-
▼生成AIについてもっと詳しく知りたい
⇒ 生成AI(Generative AI)|用語集
コンテンツの真正性を保証する「CAI / C2PA」
生成AIによるフェイク画像や動画の流通が課題となる中、メタデータを活用して「そのコンテンツが信頼できるか」を判断できる仕組みが求められています。
こうした背景から注目されているのが、AdobeやThe New York Times、Microsoft などが共同で進めている国際標準「CAI(Content Authenticity Initiative)」および「C2PA(Coalition for Content Provenance and Authenticity)」です。
これらの取り組みでは、コンテンツに対して以下のような改ざん防止メタデータ「Content Credentials」を付与します:
- 撮影者・制作元
- 編集履歴(何を、どのように加工したか)
- 日時・位置情報
- デジタル署名による改ざん検知
これにより、画像や動画の「出どころ」と「編集の痕跡」を誰でも確認できるようになります。
Adobe Photoshop や Behance、Cloudflare などがすでにこの機能に対応し始めており、今後はニュースメディアやSNSプラットフォームへの導入も進む見込みです。
ブロックチェーンでメタデータの不変性を担保する試み
メタデータは改ざんや消失のリスクを持つため、「誰が・いつ・どんな情報を付けたのか」を正確に残し、信頼できる形で管理することが重要です。
そこで登場するのが、ブロックチェーン技術によるメタデータの管理です。
現在、C2PAをはじめとする一部のプロジェクトでは、メタデータとコンテンツをブロックチェーンに記録し、真正性と履歴を保証する仕組みが検討・実装されています。これにより
- 改ざん検知
- 著作権保護
- アクセス権管理
といった観点から、長期的な信頼性の確保が期待されています。
商用利用はまだ限られていますが、NFTや著作権管理、公共データの真正性検証などへの応用も見据えた動きが活発化しています。
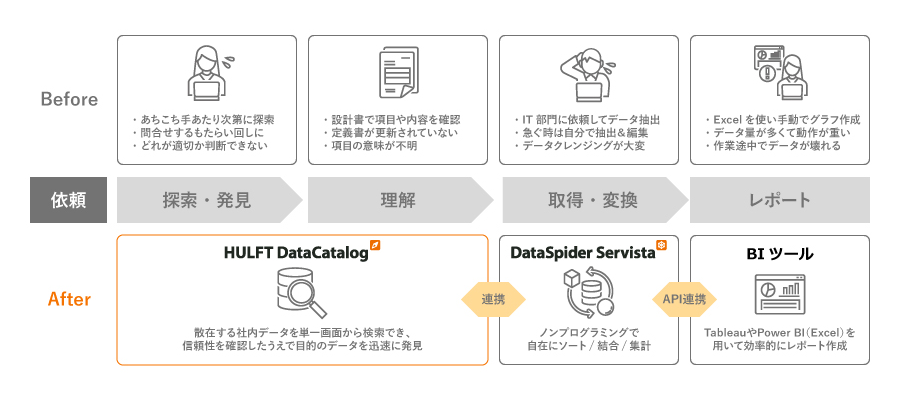
セゾンテクノロジーのメタデータ管理ソリューション「HULFT DataCatalog」
HULFT DataCatalog(ハルフト データカタログ)は、企業内で分散管理される様々なデータの概要(メタデータ)を自動収集してカタログ化。所在や来歴を可視化し、データに関するナレッジを共有することで、データ探索の効率化とデータの内容に関する理解促進を支援します。
まとめ
メタデータは、データを整理し可視化するうえで欠かせない要素であり、企業のデータ資産を効果的に活用する原動力です。メタデータは、もはや単なる「補足情報」ではなく、情報の信頼性を保証し、効率的な活用を可能にする基盤技術へと進化しています。目的に応じた種類のメタデータを整備し、管理プロセスを適切に構築することで、分析やDX推進の基盤を強固にできます。組織のニーズに合わせてメタデータ戦略を最適化し、常に最新技術との融合を図る姿勢が、これからのデータ社会での成功を左右するでしょう。
執筆者プロフィール

小川 優美
- ・所 属:マーケティング部
- 広告代理店での2年間のコピーライター経験を経て、その後はIT業界一筋。B2CからB2B、日系ベンチャーから大手外資系まで、さまざまな企業での経験が強み。広報、ブランディング、プロダクトマーケティング、キャンペーンマネージャーなど、一貫してマーケティングにまつわるさまざまな業務に従事し、2024年5月より現職。プライベートでは、自然と触れ合うこと、温泉&銭湯が大好き。
- (所属は掲載時のものです)
おすすめコンテンツ



データ活用コラム 一覧
- データ連携にiPaaSをオススメする理由|iPaaSを徹底解説
- システム連携とは?自社に最適な連携方法の選び方をご紹介
- 自治体DXにおけるデータ連携の重要性と推進方法
- 生成 AI が切り開く「データの民主化」 全社員のデータ活用を阻む「2つの壁」の突破法
- RAG(検索拡張生成)とは?| 生成AIの新しいアプローチを解説
- Snowflakeで実現するデータ基盤構築のステップアップガイド
- SAP 2027年問題とは? SAP S/4HANAへの移行策と注意点を徹底解説
- Salesforceと外部システムを連携するには?連携方法とその特徴を解説
- DX推進の重要ポイント! データインテグレーションの価値
- データクレンジングとは何か?|ビジネス上の意味と必要性・重要性を解説
- データレイクハウスとは?データウェアハウスやデータレイクとの違い
- データ基盤とは?社内外のデータを統合し活用を牽引
- データ連携を成功させるには標準化が鍵
- VMware問題とは?問題解決のアプローチ方法も解説
- kintone活用をより加速するデータ連携とは
- MotionBoardの可能性を最大限に引き出すデータ連携方法とは?
- データクレンジングの進め方 | 具体的な進め方や注意点を解説
- データ活用を支えるデータ基盤の重要性 データパイプライン選定の9つの基準
- 生成AIを企業活動の実態に適合させていくには
- Boxとのシステム連携を成功させるためのベストプラクティス ~APIとiPaaSの併用で効率化と柔軟性を両立~
- RAGに求められるデータ基盤の要件とは
- HULFTで実現するレガシーシステムとSaaS連携
- データ分析とは?初心者向けに基本から活用法までわかりやすく解説
- 今すぐ取り組むべき経理業務の効率化とは?~売上データ分析による迅速な経営判断を実現するデータ連携とは~
- Amazon S3データ連携のすべて – メリットと活用法
- ITとOTの融合で実現する製造業の競争力強化 – 散在する情報を統合せよ!
- データ分析手法28選!|ビジネスに活きるデータ分析手法を網羅的に解説
- Amazon Auroraを活用した最適なデータ連携戦略
- 生成AIで実現するデータ分析の民主化
- データ活用とは?ビジネス価値を高める基礎知識
- iPaaSで進化!マルチRAGで社内データ価値を最大化
- Microsoft Entra ID連携を徹底解説
- iPaaSで実現するRAGのデータガバナンス
- 銀行DXを加速!顧客データとオープンデータで描く金融データ活用の未来
- データ統合とは?目的・メリット・実践方法を徹底解説
- 貴社は大丈夫?データ活用がうまくいかない理由TOP 5
- 連携事例あり|クラウド会計で実現する経理業務の自動化徹底解説!
- 顧客データを統合してインサイトを導く手法とは
- SX時代におけるサステナビリティ経営と非財務データ活用の重要性
- メタデータとは?基礎から最新動向までFAQ形式で解説
- データは分散管理の時代?データメッシュを実現する次世代データ基盤とは
- API連携で業務を加速!電子契約を使いこなす方法とは
- BIツール vs. 生成AI?両立して実現するAI時代のデータ活用とは
- 脱PoC!RAGの本番運用を支える「データパイプライン」とは
- モダンデータスタックとは?全体像と構成要素から学ぶ最新データ基盤
- データ分析の結果をわかりやすく可視化!〜 ダッシュボードの基本と活用徹底ガイド 〜
- Boxをもっと便利に!メタデータで始めるファイル管理効率化
- メタデータで精度向上!生成AI時代に必要なメタデータと整備手法を解説
- HULFTユーザーに朗報!基幹システムとSalesforceを最短1時間でつなぐ方法
- 脱炭素経営に向けて!データ連携基盤でGHG排出量をクイックに可視化
- データが拓く未来のウェルスマネジメント
- iPaaSが必要な理由とは?クラウド時代に求められる統合プラットフォーム
- 顧客データがつながると、ビジネスは変わる。HubSpot連携で始める統合データ活用
- AI時代のデータ探索:ベクトル検索の手法とデータ連携方法を解説
- RAGのドキュメント検索の精度を高めるチャンク分割とは
- 名刺管理データを真価に変える:CRM・SFA活用で営業力を最大化
- ETL・ELT・EAIの違いとは?データ連携基盤を最適化するポイントを徹底解説
- Marketoと外部ツールのデータ連携で実現するBtoBマーケティングの効率化
- 鍵はデータの構造化!生成AIの回答精度を高める前処理の実践
- データ連携基盤で実現するこれからの防災DX《前編》
- データ連携基盤で実現するこれからの防災DX《後編》
- 効率性と柔軟性を併せ持つ「ローコード×データ連携」で競争優位性を手に入れる!
- Oktaを軸に広がるIdP連携・データストア接続・iPaaS活用の完全解説
- 銀行の不正検知を強化する行内データ活用戦略:予測・予防型への転換ポイント
- 生成AIの費用対効果をどう測る?ROI指標と見落としがちな観点を解説
- AIの嘘をどこまで許容する?情シスが知るべきRAGハルシネーション抑止策
- API連携とは?基本の仕組み・メリット・導入手順などを徹底解説!