![]()
![]()
 “ひらめき”や“仮説”を誰でも検証できる環境を目指し
“ひらめき”や“仮説”を誰でも検証できる環境を目指し
データドリブンプラットフォームを構築
データ活用の意識と取り組みが短期間で“進化”!


株式会社セゾン情報システムズ(現セゾンテクノロジー)は、「データの民主化」の実現、すなわち全社員が自らの意思で自発的にデータを利活用して業務を改善できるようにする、という目標を掲げ、全社データドリブンプロジェクトを発足。「データを集め、溜め、探し、活かす」ためのすべての機能を搭載した基盤「データドリブンプラットフォーム」(以下、DDP)を構築した。同プロジェクトの推進役を務めたコーポレートデベロップメントセンター ITサポート部の佐々木勝氏に、プロジェクトの立ち上げから企画、構築、活用、定着までに行ったことや注意点、DDP活用の成果などについて話を伺った。
※所属は取材時のものです。
“ひらめき”や“仮説”を誰でも検証できる「データの民主化」を目指し、DDPの構築に挑む!
はじめに、今回構築したDDPとはどういうものか、簡単に説明してください。
ひと言でいうとデータウェアハウス(DWH)に活用ツールをドッキングさせた仕組みで、「データを集め、溜め、探し、活かす」ためのすべての機能を搭載した基盤です。社内のユーザーは、検索・抽出しやすい状態で全社に公開されているDWHのデータを参照して、目的に合わせて自らデータマートを作成し、データを利活用できます。
データを「集める」「溜める」のはもとより、その先にある「探す」「活かす」というゴールを達成するために必要なものとして、弊社では「4種の神器」を定めました。欲しいデータがどこにあるかを探せるデータカタログ、データを結合・加工するDWH、データ抽出の処理を自動化するデータ連携ツール、分析・可視化するBIツール。ユーザーは、目的やリテラシーに応じて、これら4つを組み合わせて利用します。
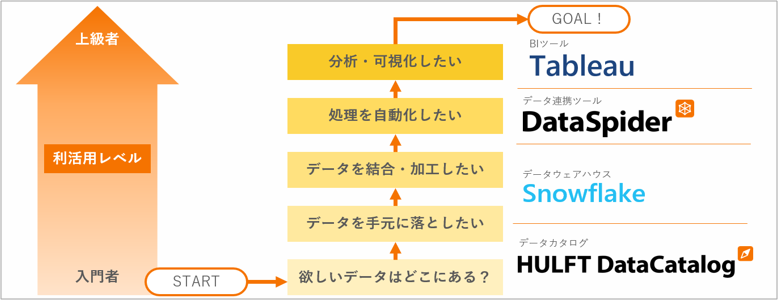
セゾン情報システムズ(現セゾンテクノロジー)のDDPを構成する「4種の神器」。以下の4つのツールからなる
○利用者が必要なデータを探し出し、データの意味を理解するデータカタログ
○データを検索・抽出しやすいよう整理して溜めておくデータウェアハウス
○データの抽出・加工を自動化するデータ連携ツール
○データを様々な切り口で分析・可視化するBIツール
では、そのDDPの構築プロジェクトをどのように進めたのか、順を追って解説してください。
最初にもっとも重要である、「なぜ今データドリブンが必要なのか?」という課題背景を明確にすることから始めました。まずは経営・営業面にとってのメリット。弊社は「データエンジニアリングカンパニー」を標榜し、データを俊敏にビジネスの意思決定につなげるサービスをお客様に提供しています。そうしたビジネスを進める上では、実際にデータを利活用して企業競争力を向上させるという、自らの体験をもってお客様に価値を届けることが大切ですから、その意味で今回の取り組みは重要な意味を持つといえます。
一方、社内のユーザーにとっても大きなメリットがあります。従来弊社では、各社員がそれぞれの担当業務の品質向上や効率化を目的としてデータを利活用したいと思っても、簡単には実行できませんでした。というのもユーザーは、目的に適うデータが社内に存在しているかを自分で調べ、データオーナーに使用目的を伝えてデータの提供を受け、データが表しているビジネス上の意味を確認し、分析・自動化を作り込むという、非常に煩雑な作業をしなければならなかったからです。今回の取り組みによってユーザーは、データ利活用の手順やノウハウを身につけ、あらかじめ使える状態に整理されたデータを手軽に参照し、分析・自動化のツールを自由に使って目的を達成できるようになります。
同時に、私たち情シスの長年の悩みも一気に解消されます。これまでは、データを使って可視化・分析強化したいというニーズが社内に非常に多く存在するのに、情シスのリソース不足によって対応が追いつきませんでした。また、情シスは各業務の専門家ではないので、依頼ごとに求められる分析軸を理解するのに苦労していました。さらに、依頼ごとに構築して400以上に膨れ上がった作業用データベースの管理が非常に大変でした。そうした課題をDDPですべて解決できるのです。
まずそのようにプロジェクトの目的をはっきりさせるのが大切ということですね。
そうですね。加えてもう1つ、実現すべき姿を明確化することも重要だと思います。その点について弊社では「データの民主化」、つまり日々の業務の中で生まれる“ひらめき”や“仮説”を誰でも検証できる状態、と定義しました。そして、それを実現するために、「すべてのデータがこの基盤の中にあると全社員に認知されていること」「データリテラシーのある社員が増え、データに対する影響やリスクを理解できるようになること」など5つのゴールを設定しました。
では、それらのゴールを達成するには、具体的にどういうシステムを作ればいいのか? それを明らかにするために、想定されるユーザー体験をできるだけたくさん挙げ、それぞれについてDDPが備えるべきシステム機能をひとつひとつ定義し、一覧にしました。それを見ながら各機能を実装する優先順位をつけ、アジャイル開発に着手したのです。

セゾン情報システムズ(現セゾンテクノロジー)が掲げるデータ活用の「5つのゴール」
プロジェクトの立ち上げにあたっては、どんな観点から参画メンバーを選ぶかも重要ですよね。
その通りです。そこで弊社ではステークホルダー、DDPの利害関係者の人物像を定義して、その中から誰を巻き込むべきかを検討しました。まず絶対に必要だと考えたのが、データと業務の関連性を知り、意味づけのできるデータオーナーです。また、すでにデータを使ってなんらかの業務を行い、課題や痛みを実感しているデータ利用者の参加も不可欠です。エンジニアだけのプロジェクトチームでもデータ基盤を作ることはできますが、それだと「集める」「溜める」が目的化しがちで、その先にある本当のゴールの達成は難しくなります。データの意味や業務の課題を知る人の頭の中にこそ、DDPに求められる“真の要件”があるわけですから、そうしたメンバーには必ず参画してもらわなければならないと考えました。
加えて、主な利用者になると想定される人や、後ほど詳しく話しますが、データの利活用レベルに合わせて分類した6階層のペルソナからも適任な社員を選び、プロジェクトに巻き込んでいくことにしました。
そうしたメンバーの参画が大事だというのはよくわかりました。ただ、実際には日常の業務で忙しく、全員の協力を得るのはなかなか難しいですよね。
そう、確かに部門間の調整というレベルでは、必要な時間を割いてもらえないでしょう。そこで弊社では、経営層から「全社でデータドリブンを進めていくので、指名されたメンバーはミッションとしてプロジェクトに参画するように」という強いメッセージを発信してもらいました。そうすることで、全社に必要性を認識させ、DDPの要件を握る重要人物として私たちの求める人材をアサインできたのです。
そうしてプロジェクトの全メンバーが一堂に会し、キックオフの実施に至りました。メンバーには、4か月間のタスクフォースとしてプロジェクトへの参加を依頼し、改めて背景課題と目指すべきゴールを共有しました。
それから、プロジェクトへの参画によってメンバーと業務部門が享受できる2つの価値についても説明しました。1つは、情シスメンバーによるスキル習得のサポートによって、メンバーはデータ活用リテラシーを高め、業務の生産性向上を自らの手で実現できるようになること。もう1つは、当該部門が有するデータを集約し共有することで、データを使って業務の属人化を解消できることです。要するに、プロジェクトへの取り組みは、結局自分たちのメリットとして返ってきますよ、と伝えることで、モチベーションの向上を図ったわけです。
そのようにしてプロジェクトが始まり、次の企画・構築のフェーズで最初に取り組んだことは?
まずはデータを集める作業です。社内にどんなデータがあるかを洗い出すため、存在するすべてのシステムを列挙し、それぞれの担当者へのヒアリングを実施しました。そのシステムのデータに責任を持つオーナーはどの部門で、共有する価値のあるものなのかをヒアリングを通じて判断し、「使える」「使えない」「使えそう」の3種類にデータを分けていきました。
次に、対象システムのオーナーとエキスパートを確定させました。調べると社内には約160ものテーブルがあることがわかったので、それぞれについてオーナーが誰なのか、そのテーブルの保有データにもっとも精通しているエキスパートは誰なのかを確かめたわけです。そして、そのデータが分析・自動化・可視化に使えそうかをオーナーとエキスパートに確認して、使えそうにないデータについては除外するなど、DWHに格納するデータを選定していきました。
その際に考慮したポイントは、現状ニーズはないものの将来的にデータ分析に使う可能性を見込めるデータは格納対象としたこと。反対に、秘匿性が極めて高く公開がリスクにつながるデータや、顧客との契約上公開すべきでないデータは格納の対象外としたことです。

セゾン情報システムズ(現セゾンテクノロジー) ITサポート部データドリブンプラットフォームプロジェクトリーダー 佐々木勝※所属は取材時のものです。
単純に社内のあらゆるデータを集めてDWHに格納すればいい、というわけではないのですね。
そうですね。あと、対象データをどのようなタイミング・方式で収集するかを決める際にも注意が必要です。データの種類には大別して3つ、過去の時点情報が必要なため洗替方式で全データを毎日リフレッシュすべき「マスタ系データ」、日々差分データが発生するため前日発生データを追加すべき「トランザクション系データ」、中間データベースでデータを完成させてから洗替・追加すべき「中間的な性質を持つデータ」があります。それらの特性や想定される用途に合わせて、データを格納するタイミングや抽出要件を明確にしておく必要があります。
データを「集める」作業が一段落したら、次は「溜める」作業ですね。
はい。まずはデータの公開範囲を整理しました。当然ながらデータの中には、マスキングする必要のある秘匿性の高いものもあります。よって、テーブル自体、あるいはテーブル内の各項目をどこまで公開すべきかを慎重に検討しなくてはなりません。
結果として弊社の場合、公開方法を4パターンにモデル化しました。「全社員に全データを公開」「社員に公開するが、一部項目は特定部門以外マスク」「特定部門に所属する社員に限り全データを公開」「特定の社員に限り全データを公開」の4つです。
次にデータの下処理です。いわゆる“汚いデータ”、たとえば人によって表現の異なる項目(揺らぎ)などや、単体では使いものにならないデータなどは、そのままではDWHに格納できません。そういうものがないかをオーナーに確認し、ある場合にはデータ連携ツールを使ってきれいにしたり、そもそもの入力運用から変えたりして対応しました。
だいたいここまでが、データを「集める」「溜める」のに必要とされた作業です。次はいよいよユーザーに直接関わる領域、「探す」「活かす」ための作業に入っていきます。

