DataMagic 技術コラム Vol.3
〈文字コード変換:Unicode(UTF-8)編〉
はじめに
Unicodeは、国際化対応が必要なソフトウェア、主要なOS、プログラミング言語で標準的に用いられています。現実的にネット関連システム、Java/.NETで稼動するシステム、グローバル展開を行っている企業のシステムではUnicodeが一般的に利用されています。
しかし、旧来の業務システムにおいては、JIS,Shift_JIS,EUC,EBCDICといった文字コードが主に使われており、Unicodeへ統一することが難しいのも事実です。
しかし、DataMagicを用いることにより、旧来の業務システムで利用していた文字コードからUnicodeへの変換が可能となるので、さまざまなシステムにおける日本語コードの差異を埋めることが出来ます。
本TIPSでは、IBMメインフレームの固定長データをUnicode(UTF-8)の固定長データに変換する例を紹介します。なお、本TIPSを利用するには、DataMagicがコンピュータにインストールされていることが条件となります。DataMagicの入手先やインストール方法などについては、別稿の「DataMagicをインストールする」を参照してください。

操作方法
手順1 - コード変換対象の固定長データを用意する
まずは、メインフレームのデータを用意します。データが用意出来たら、DataMagicが導入されているPCの下記のフォルダに保存します。こちらのデータは第1回の技術コラムにおいて使用したデータと同じデータとなります。
C:\work\SAMPLE3\(“in”というファイル名で保存)
-
※
今回のTIPSではIBM(zOS)の文字コードの固定長データを利用します。

変換元データのダウンロード(注:サンプルファイルはzip形式となります。解凍してからご利用ください。) ![]()
手順2 - DataMagicのスクリプトファイルをダウンロードし設定する
IBMメインフレームのデータをUnicode(UTF-8)に変換するには、下記のスクリプトファイルをダウンロードして、DataMagicがインストールされているフォルダに保存します。
C:\work\SAMPLE3\(“sample3.igen”というファイル名で保存)
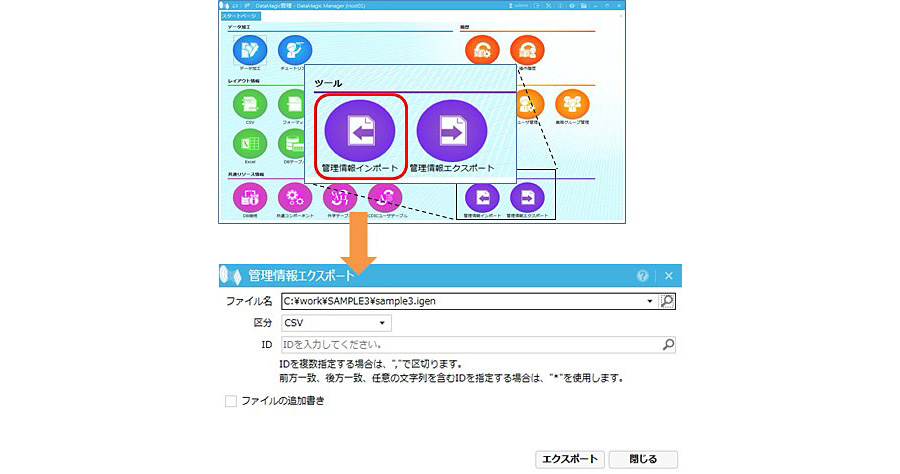
DataMagicの管理画面を起動し、ダウンロードしたスクリプトファイルをDataMagicに取り込みます。取り込みはスタート画面の[ツール]にある[管理情報インポート]アイコンをクリックします。管理情報インポート画面においてダウンロードしたファイルを指定し、インポートボタンをクリックします。取り込みが成功すると、データ加工情報一覧画面にSAMPLE3というIDが登録されます。
スクリプトファイルのダウンロード(注:サンプルファイルはzip形式となります。解凍してからご利用ください。) ![]()
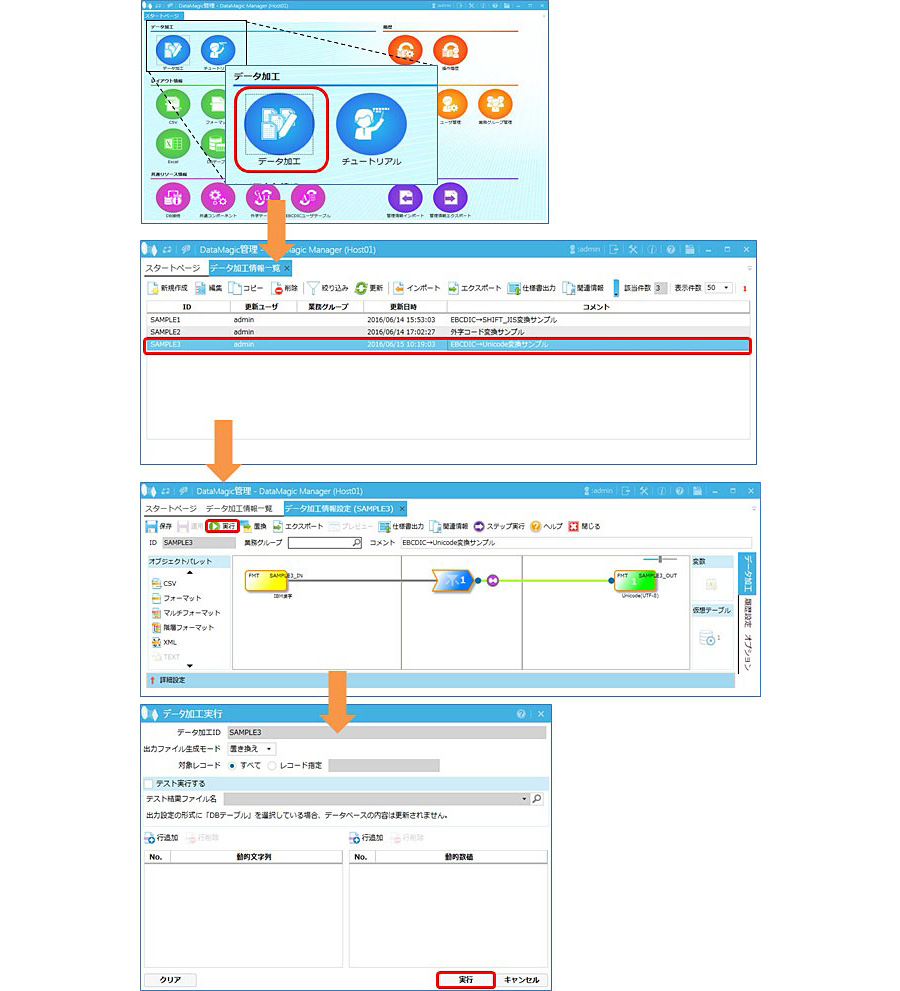
手順3 - DataMagicを実行する
手順2において登録したSAMPLE3というデータ加工情報IDをダブルクリックし、入力設定および出力設定のファイル名が正しく設定されていることを確認します。画面から、SAMPLE3のデータ加工情報IDを開き、画面上部にある「実行」ボタンから行います。
手順4 - 実行結果を確認する
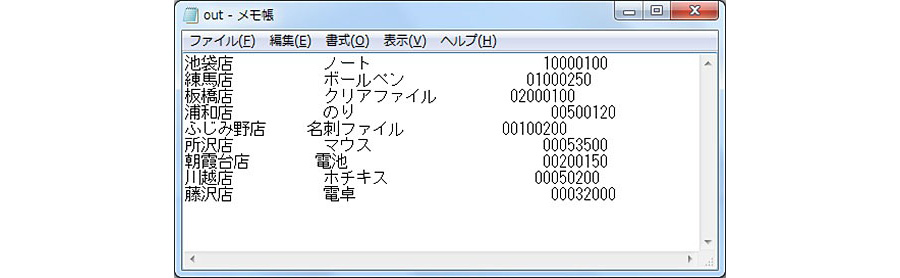
手順3において実行が完了すると、出力設定において指定されたC:\work\SAMPLE3\に“out”というファイルが出来ているのでメモ帳等のエディタで確認して下さい。
最後に
今回はIBMメインフレーム固定長データをUnicode(UTF-8)に変換しましたが、Unicode(UTF-8)を変換元、変換先として使用する場合のいくつかのPointを下記に列挙しますのでご参考にしてください。
Point1:マルチバイト文字は2バイトではなく3バイトに
Unicode(UTF-8)は可変長(1〜4バイト)の8ビット符号単位で表現する文字符号化形式のため、IBMメインフレームやShift_JIS等で2バイトで表現されていた文字の多くが3バイトで表現されます。そのため、変換先としてUnicode(UTF-8)を使用する場合は十分な項目長を用意する必要があります。
Point2:シフトコードなし文字項目(Nタイプ)の扱い
IBMメインフレーム等のEBCDIC系文字コードにおいては1バイト文字と2バイト文字の切り替えに「シフトコード」というものが使用されますが、その切り替えのない項目をDataMagicではNタイプというデータ属性で取り扱います。ただしPoint1でも記載したとおり、Unicode(UTF-8)は可変長(1~4バイト)のコードとなるため、偶数バイトのデータを取り扱う前提のNタイプとは整合性がとれなくなる場合があります。Unicode(UTF-8)の変換を行う場合は漢字・キャラクタ混在型であるMタイプを使用してください。
Point3:機種依存文字
UnicodeにはWindowsとその他で「~」「∥」「-」「¢」「£」「¬」の文字の取り扱いに差異があります。DataMagicのコード変換でこの差異を吸収することが可能です。
ぜひ、DataMagic評価版をダウンロードして、今後の技術コラムを活用してください。
- 評価版は無償で60日間ご利用いただけます。
- 評価版のお申し込み後、90日間の技術サポートを無償でご利用いただけます。
DataMagic コラム一覧
- DataMagic for Windows インストール編
- DataMagic Manager インストール編
- “早い、安い、簡単”が魅力「DataMagic」のススメ
- Vol.1 〈文字コード変換:EBCDIC⇔Shift_JIS編〉
- Vol.2 〈文字コード変換:外字コード編〉
- Vol.3 〈文字コード変換:Unicode(UTF-8)編〉
- Vol.4 〈データ変換:パック⇔ゾーン編〉
- Vol.5 〈固定長⇒CSV データ変換編〉
- Vol.6 (番外編)HUB+DataMagic連携事例
- Vol.7 〈流通BMS⇒CSV変換編〉
- Vol.8 〈マッチング処理編〉
- Vol.9 〈全角⇔半角変換編〉
- Vol.10 〈DBテーブルデータ抽出編〉
- Vol.11 〈データ補正編〉
- Vol.12 〈文字列置き換え編〉
- Vol.13 (番外編)DataMagic導入事例
- Vol.14 〈データソート・ファイル分割編〉
- Vol.15 〈データ集計編〉
- Vol.16 〈ファイルマージ編〉
- Vol.17 〈HULFT定義一括登録編〉
- Vol.18 (番外編)HULFT-WebFiletransfer+DataMagic連携事例
- Vol.19 (導入事例編)弊社利用事例
- Vol.20 〈データマスキング編〉
- Vol.21 〈DB移行編〉
- Vol.22 〈共通コンポーネント:EBCDIC系コードの置き換え編〉
- Vol.22 Appendix 〈共通コンポーネントのインポート手順および実行手順〉
- Vol.23 〈共通コンポーネント:日付変換機能拡張編〉
- Vol.24 〈お客様要望を解決!:不正データがあってもデータ加工できる共通コンポーネント編〉