〈開発者ブログ 連載〉Vol.5
~ データの可視化・分析について ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか

"Analytics"から見たAWS re:Invent(2023年度編)
データ分析・可視化に関する記事の5回目。
2023年11月27日から12月1日まで、ラスベガスで開催されたAWS re:Inventに参加しました。
はじめに断っておきますが、発表されたUPDATEをまとめた内容ではありません。
それは私に求められていることではないので、あくまでデータエンジニアから見た視点でレポートしたいと思います。
ETLの使われ方をあらためて理解する
内容に入る前に少しおさらいです。
みなさん、最近Data Preparationって耳にしますか。
Tableau Prepが出てきたころはよく耳にした記憶がありますが、最近そんなに聞かないですよね。
でも別に古い定義になってしまったわけではなく、現役で使われています。
Data PreparationはETLの使われ方のひとつです。
ETLというのはプロセスまたはツールを指しますが、ETLという単語だけで会話をしてしまうと粒度が粗すぎることがあります。
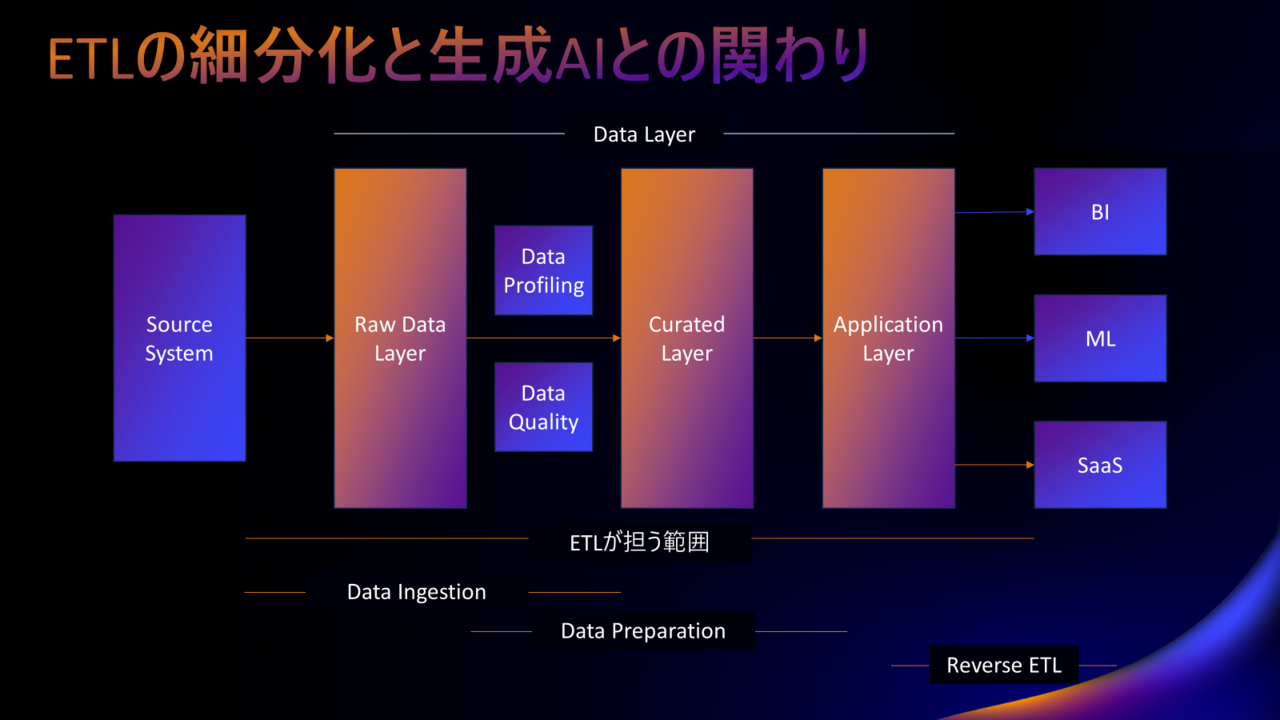
(発表用資料から持ってきているのでヘッドラインがおかしいのは気にしないでください)
ということで、データ分析基盤においてETLってどういう使われ方をするのか、ということをおさらいします。
※データ連携基盤のことはいっかい脇におきます、そちらは自明なので
使われ方は以下に大別できます。
- Data Ingestion | (DWHなどへの)データの取り込み
- Data Preparation | データの編集・加工 → データマートの作成など
- Reverse ETL | 分析基盤から、SaaSや基幹システムなどへのデータの戻し
どこの話をしているか、というのを明確にしないと誤解が生まれる可能性があります。
たとえば、昨年のre:Inventで発表されたzero-ETLに対する受け止め方は本当に人それぞれでした。
私はというと、メッセージ性の強さには感心しましたが、内容に関しての驚きはありませんでした。
2022年のre:Invent後の同名記事にも書いていますが、zero-ETLのzeroはData Ingestionだけを対象としています。
これはこの記事を書いている現時点でも変わっていません。
Data IngestionにおいてETLの利用が減っていくことは昨年のre:Invent以前から規定路線でした。
従って驚きもなかったのですが、zeroが全体にかかると受け止めたらびっくりしますよね
ETLはData Ingestion, Data Preparation, Reverse ETLに大別できることをいまいちど理解いただければと思います。
たとえばAWSの発表でETLに関するものを見る、となると基本的にGlueのUPDATEを追うことになると思います。
ですが、それだと大局的に見れなくなります。Data PreparationはGlueとは別のサービスで実装されていたりするので。
AWSでデータ利活用基盤を構築するとなると基本的に複数のサービスを組み合わせます。
アーキテクチャの中でそれぞれのサービスが担う役割だとか概念モデルをベースに追っていくのが良いかなと思います。
もちろん個々のサービスのUPDATEを追った方が良い方もいます。それはロールによります。
データエンジニアの場合は、サービスのUPDATEを追うよりも、大局的に見た方が良いかなというのが私の見解です。
今回はData Ingestion, Data Preparationという観点で見ていきたいと思います。
Data Ingestion
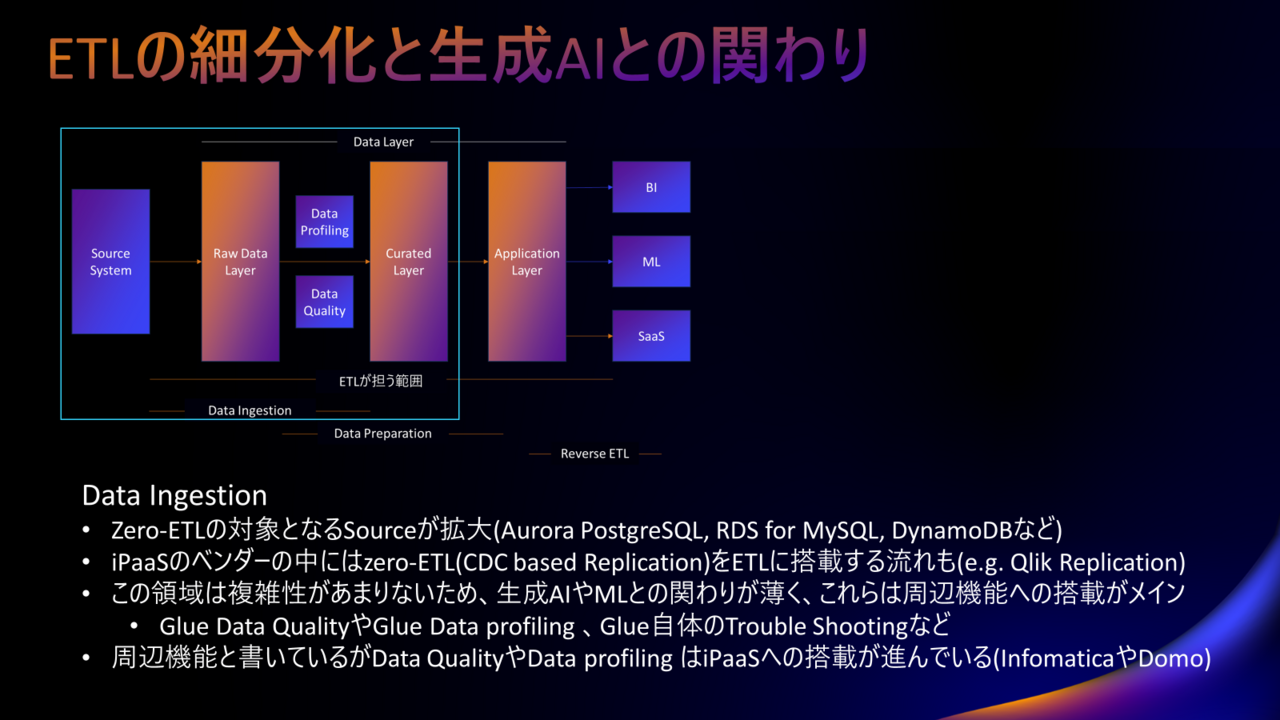
まずはData Ingestionについて書きます。
Data Ingestionは何かというと、ほとんどの場合はDWHにデータをそのまま入れることを指します。
※DWHじゃない場合もありますので正確性を重視した表現ではありません
Data Ingestionはzero-ETLが対象にしている領域だと書きました。
zero-ETLというのは何かというとCDC(Change Data Capture)を利用したレプリケーションです。
もっと平たくいうと、元データの変更を検知して、同期する仕組みです。
データをそのままDWHに入れるだけですので、ETLが無くてもよさそうというのは想像が着くのではないでしょうか。
※現実はまた違うのですが今回は割愛します
昔からSQL LoaderやBCPユーティリティを利用してやっていることと変わりません。
そしてここはやることが単純ですから、生成AIとの関わりもあまりありません。
ただし、Data Ingestionを終えたデータはその内容や品質をチェックする必要があります。
データの取り込みが成功しても、それが使える/使ってよいデータであるかどうかはまた別の話ですよね。
これらを担うData ProfilingやData Qualityという仕組みがあり、AWSに限らずサービス化がされています。
理解を深めてもらうために、それぞれどういうことを実現する仕組みなのかという一例を示します。
- Data Profilingとはデータをチェックしてこの列には個人情報が含まれているね、などを示してくれます。
- Data Qualityはデータの分布が予め指定した閾値の範囲内にあるかなどを確認して、異常などを検知します。
勘の良い方はお気づきかと思いますが、(生成AIかは別として)AI,MLと非常に相性の良い領域ですね。
そして、Data IngestionにおいてETLの存在感が薄くなる一方で、その周辺のData ProfilingやData Qualityの機能はiPaaSへの搭載も進んでいます。
また、(日本語としておかしいですが)zero-ETLがETLに搭載されつつあります。
すなわち、CDCを利用したレプリケーションを利用できるETL(というかiPaaS)が出てきています。
Data IngestionにおけるETLは、Data ProfilingやData Quality、そしてzero-ETLを機能として搭載していくのか否か。
そして搭載するのであればAI,MLを活用してデータエンジニアやデータスチュワードの生産性向上に寄与していけるのか。
というあたりがポイントになりそうです。
(機能追加するのが正解と思っているわけではありません)
Data Preparation

続いてData Preparationです。
Data martを作る、BIのセマンティックモデルを作る、MLの特徴量セットを生成するなどの業務が該当します。
データエンジニアとそれ以外でこの領域対する理解の解像度が大きく異なってくると思うので、まず補足から入ります。
Data Preparationにおいて最初にデータエンジニアがとる行動は、ソースデータの確認です。
※データを探すとこからスタートするケースもあります。
具体的に何を確認するかというと、データのカーディナリティとディストリビューションです。
データにどういう種類のレコードが存在していて、どういった分布になっているかということを確認します。
その過程でデータカタログなども利用します。
まずETLのエディタを開くのではなくて、SQLでソースデータを細かく確認していく、というイメージですね。
それを踏まえた上で、Data PreparationにおいてAWSが何をやろうとしているか。
これはSageMaker Canvasを見るとわかりやすいです。
SageMaker Canvasでは、自然言語でデータのカーディナリティとディストリビューションを確認できます。
データエンジニアはこの確認をまず日付列で確認する、次に区分列で確認するなど細かく条件を変えながら実施していくのですが、こういうのはインタラクティブに確認できると効率的ですから生成AIと最も相性の良い領域です。
結果はヒストグラムの形で簡易的に可視化されて確認できます。
そして、確認が出来たらそのデータをそのままソースとしてETLのエディタに遷移できます。
これは本当にシームレスで、データエンジニアの仕事の流れをよく理解しています。
たとえばTableau Pulseなどインタラクティブに簡易的な可視化ができる機能は多くのサービスに搭載されています。
BIもインタラクティブに可視化されると便利なケースが多いので、それも正当な進化ではあるのですが、データ加工の事前準備段階での簡易的な可視化に着目されているのは初めて目にしました。
今後、BIだけではなくdbtの領域においてもこういった方向性での進化がされていくことが予想されます。
Data Preparationにおける生成AIの活用方法としては、自然言語でのデータのカーディナリティとディストリビューションの確認がこれまで聞いた中で一番利用価値がありそうだなというのが所感です。
データ人材の不足により生じるギャップ
少し趣が変わりますが、私がいくつかのセッションを受けて感じたギャップについて述べます。
以下の図は、データ分析基盤を実現するためのアーキテクチャ例です。
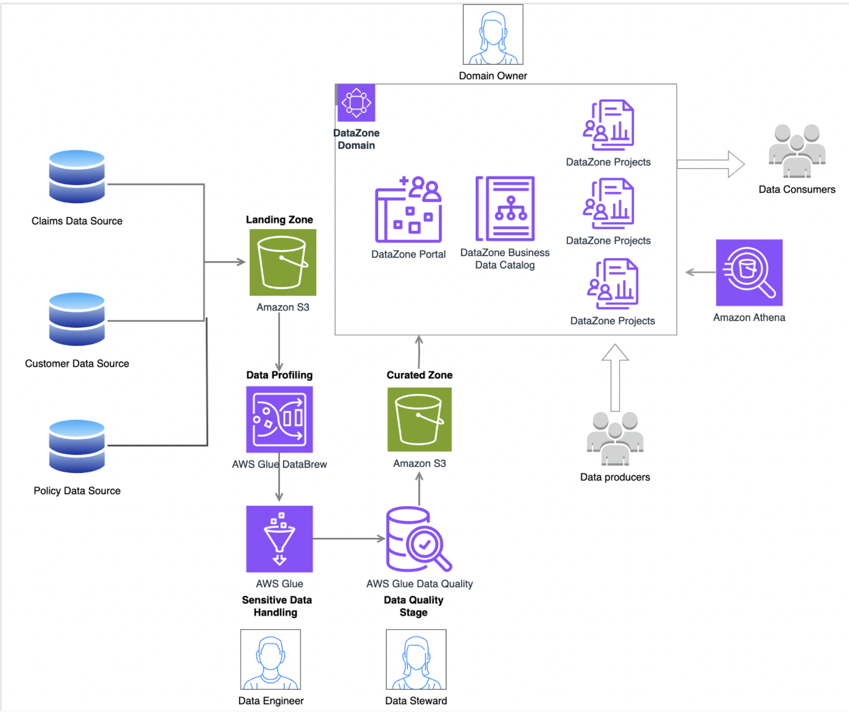
下の方に先ほど書いた、Data Qualityなどが登場しますね。
Data Qualityは、データスチュワードが責任を持って担保するような表現になっています。
ところが、日本ではデータスチュワードはニーズに対して人材が圧倒的に不足しています。
日本のデータスチュワードは適任者をアサインできてもデータを探索することに精いっぱいで、Data Qualityをチェックする余裕がありません。
また、図の中のData Zoneが示している部分は、データメッシュを実現するための仕組みを機能させています。
ここではData Producersという人たちが登場しますが、データメッシュにおけるData Producersは事業部門にいることを念頭に置いています。
こちらも、日本において事業部門でData Producerの職務に人をアサインするというのは非常に困難です。
細かい内容は置いていて、AWSの提示するアーキテクチャが念頭に置いた組織体制を日本では構築できない、ということだけ理解してもらえればと思います。
この図のアーキテクチャは日本でもすぐに実現できます。
しかし、そのアーキテクチャを最大限に機能させるためには、人材や仕組みが圧倒的に不足しているのです。
一方で、問題がパワー不足であるとすると、生成AIのエンパワーによって状況を変えることが出来る可能性があるとも考えることが出来ます。
Data QualityやData ProfiingはAI,MLと相性が良い領域だと先ほど書きました。
もう一歩進んで、ここがある程度自動的に運用されていく方向に向かう可能性は大いにあると感じました。
まとめ

書きたかった内容はすべて画像に含まれているので、上の画像を参照ください。
Data Ingestion, Data Preparationはそれぞれにあわせた専門的な進化を遂げています。
これに追従するのもよいですが、一方で専用ではなくGeneralで使えるというのもひとつの方向性かなと思います。
ここでどちらの方向に向かうべきか結論を書けるような内容ではありません。
いずれにせよAWSをはじめとして世界がどういう方向性に向かっているか、というのはベースの知識として理解を揃えておいた方が良いので今回のレポートを書きました。
今回のre:Inventでは俯瞰で見ると驚くような発表はありませんでした。
どちらかというと予定調和的な、予想できる範囲の発表が多かったとも言えます。
でもそれはネガティブな意味ではなく、生成AIの登場後、世界がいったんどちらの方向に向かうかが定まり、確実にそちらに向けて動いているということでもあります。
そんなことを実感したre:Inventでした。
以上で終わりです、最後まで読んでいただきありがとうございました。
執筆者プロフィール

高坂 亮多
- ・2007年 新卒で株式会社セゾンテクノロジーに入社。
- ・所属:DI本部DP統括部 DP開発1部 副部長 および DP開発1課 課長 兼務
- (所属は掲載時のものです)
- ・好きなこと:登山やキャンプなど アウトドアアクティビティ
- ~ BI基盤(分析基盤)におけるアーキテクトとして日々業務にあたっています ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか