〈開発者ブログ 連載〉Vol.6
~ データの可視化・分析について ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか

データ利活用におけるデータガバナンス
データ分析・可視化に関する記事の6回目になります。
2023年2月14日に開催されたSnowflakeのイベントSNOWDAY JAPANの基調講演を聴講してきました。
その中で匿名化やガバナンスといったキーワードが挙げられており、思うところがあったので記事にしました。
こういうのは衝動で一気に書かないとお蔵入りしますので、読みづらいところもあるかもしれませんがご容赦ください。
DXの成熟とガバナンス
企業のDXの成熟度が低いうちは、スピード感・早期の成功事例の創出が重要なポイントになります。
別に大きな成功でなくて構いませんが、事業部門を巻き込んだ成功体験であることが大事かなと思います。
一方で成熟度が高まってくるとともに重要になってくるのがガバナンスです。
成熟度が高まっているということは取り組みが全社規模にスケールしているということですからこれは当然の話かなと思います。
ガバナンスはどうしてもスピード感とトレードオフになりがちですから、これから成熟度をあげていこうという企業にとっては悩みの種です。
ガバナンスのための最低限の枠組みを私たちで用意することで「スピードを落とすことなく成功事例の創出ができる(だけで後で困らない)サービス」について最近は検討しています。
ガバナンス関連では、データの品質について考えるという記事を以前に書きました。
これは品質を保つという観点でのガバナンスですね。
今回はデータの取扱い(セキュリティ)の観点でのガバナンスについて触れたいと思います。
参考にしたのは経済産業省と総務省が策定したDX時代における企業のプライバシーガバナンスガイドブックです。
ファイブセーフモデルによる データガバナンスのフレームワーク
ファイブセーフモデルは、イギリスの統計局(ONS)において、機密情報を利用した研究を規律するために2003年から運用されてきたフレームワークで、現在はEU全域で、統計の個票データ活用時の安全対策ルールとして広く採用されています。
内容については以下です。抜粋しているというよりは、ほぼこの表に集約されています。
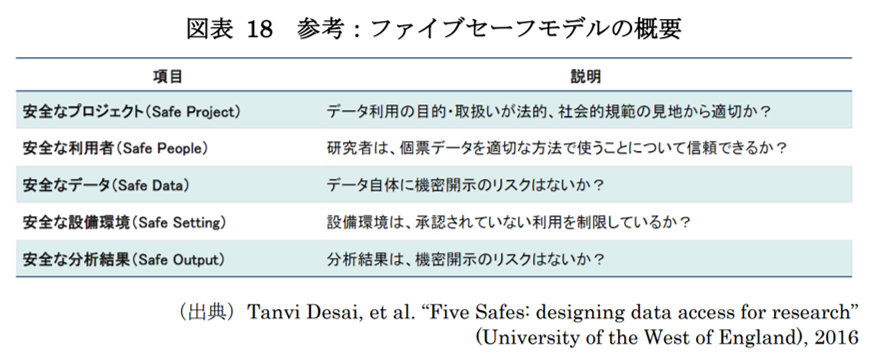
※参考:総務省/経済産業省「DX 時代における企業のプライバシーガバナンスガイドブック」
これをデータ分析基盤/データ活用基盤/社内データ基盤に適用すると以下のイメージになります。
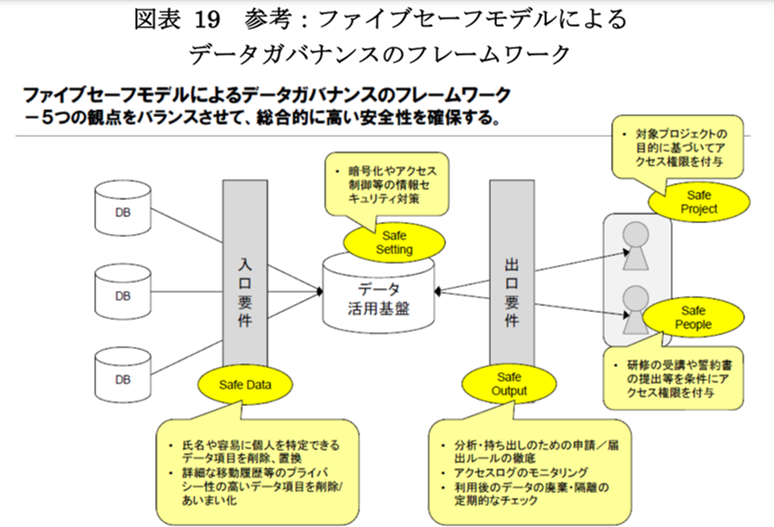
※参考:総務省/経済産業省「DX 時代における企業のプライバシーガバナンスガイドブック」
まずは入口要件と出口要件、そして基盤で担保する要件に分けて考えることが重要です。
たとえばSnowflakeの匿名化の話に戻すと、匿名化を入口要件に対応させようとしているのか、出口要件に対応させようとしているかで論点が変わってきます。(後述します)
これはデータ分析基盤に限った話ではなく、たとえばHULFT SQUARE上で何かのサービスを実現しようとする場合もヒントになる考え方かなと思います。
入口要件については、 データの種類に応じて定義するものになります。
そもそも分析基盤に蓄積していいものか、蓄積するとしてどこまで加工するか(匿名化する、除去するなど)というのが論点になります。
法的要件や企業の方針、システムの位置づけへの適合性をもとに判断することになります。
個人情報はこう、とか、業務トランザクションはこう、とか決めていくイメージですね。
入口要件で匿名化が必要な場合は、基盤自体に匿名化の機能を持たせてしまっては実現ができないケースもありますから(個人情報はクラウドに出してはダメなど)、外付けのような形でエコシステム化するアプローチも視野に入ってきます。
出口要件については、基本的にはプロジェクト(利用目的・用途)と人(利用者)に応じて定義します。
たとえば、BI表示用であればどう、だとか、社内のこのロールは、グループ企業社員は、という形で定義していきます。
従って出口要件で匿名化する場合は、きめ細かく設定が必要な場合もあります。
出口要件での匿名化は基盤内にインクルードされるケースが多いです。DWHにおける動的データマスキングなどもこれに該当します。
基盤自体は入口要件/出口要件への適合性の他に、アクセス制御やセキュリティ(アクセス元の制限)、証跡のモニタリングに関する機能が必要となります。
だいたいまとめると以下のような形かなと思います。

このような枠組みで整理することで、データの取り扱いに関するルールの制定やワークフローの整備にも繋げることができます。
繰り返しになりますが、この考え方はデータ分析基盤以外にも適用できるものだと思います。
データにまつわるサービスを具現化する際の整理の一助にもなるかなと思って書いていますので、ぜひそういった機会があればこの記事を思い出していただければ幸いです。
今回の記事は以上になります。
最後まで読んでいただきありがとうございました。
執筆者プロフィール

高坂 亮多
- ・2007年 新卒で株式会社セゾンテクノロジーに入社。
- ・所属:DI本部DP統括部 DP開発1部 副部長 および DP開発1課 課長 兼務
- (所属は掲載時のものです)
- ・好きなこと:登山やキャンプなど アウトドアアクティビティ
- ~ BI基盤(分析基盤)におけるアーキテクトとして日々業務にあたっています ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか