〈開発者ブログ 連載〉Vol.5_0
~ データの可視化・分析について ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか

Analtyticsから見たAWS re:Invent(2022年度編)
データ分析・可視化に関する記事の第5回目になりますが、今回は少し趣の違う内容でお届けしようと思います。
2022年の11/27~12/2にラスベガスで開催されたAWSのre:Inventに参加してきました。

現地の熱狂のレポートだったり楽しかったという話でもかなりの長文を書き連ねることはできますが、
それでは重要タスク推進リーダーの仕事にはなりませんので私の専門性に沿った話をしようと思います。
私は"Analyticsから見たre:Invent"というテーマを設定し参加をしました。
今回の記事ではこの内容についてレポートしたいと思います。
余談ですが、なぜいま季節外れの記事を公開しているかというと、前回の記事をどうしても早く書きたかったためです。
前回の記事:データの品質について考える
こちらは本当に大事なことを書いているつもりですので、一度さらりと読み捨てた方もぜひ何度も読んでほしいです。
Activity Summary

何を見てこの記事を書いているのかというのを理解してもらうために、まず参加セッションのサマリーを示します。
私は5日間で計12個のセッションに参加しました。
Analyticsをテーマにおいているため、トラック別に見るとAnalyticsやその周辺の技術要素に関するセッションが多くなっています。
これらのセッションを受けた結果として、以下の2つの観点から私の所感を述べていきます。
- 1.Scope of “Analytics”
- 2.A Zero ETL future…
※このレポートの骨子は現地で作ったのでアルファベット多めでうるさいですが、ハイだったんだなと温かく見てください。
Scope of Analytics
まず一番に感じたのは、Analyticsの指す範囲が日本と異なるということです。
どちらも明確な定義あるわけではないので体感としての話になりますが、大きくずれていないのではと思っています。
現地でこれらの単語を聞くことはありませんでしたが、SoR, SoE, SoIという概念を使うと説明しやすいので、これらを使って説明します。
- SoR:System of Records … 会計システムや人事・受発注の基幹システムなど記録するためのシステム
- SoE:System of Engagement … CRMやSFAなどユーザーとのつながりを重視したシステム
- SoE:System of Insight … BIなど洞察を得るためのシステム
日本におけるAnalytics
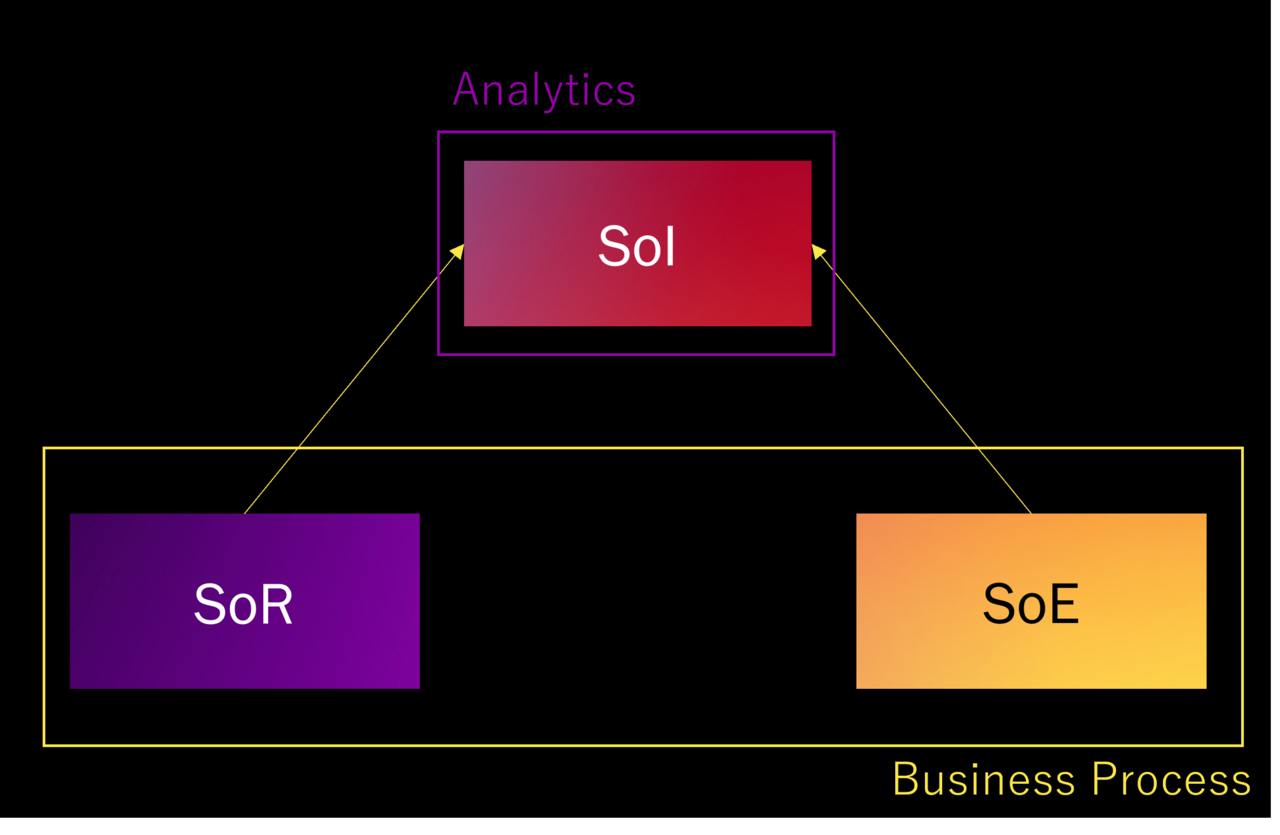
日本におけるAnalyticsを図示してみました。
まず、基本的に業務プロセスを形成するのはSoRとSoEの仕組みです。
SoIはそれらの情報を統合して分析の基盤となりますが、このSoI上で分析を行うことを日本ではAnalyticsと呼んでいます。
分析で何かが得られた場合、そこから業務プロセスへのフィードバックは施策という形で手動で行われます。
つまり、システム領域で見るとSoI=Analyticsです。そしてAnalyticsは業務プロセスに対して外付けの概念になります。
USにおけるAnalytics
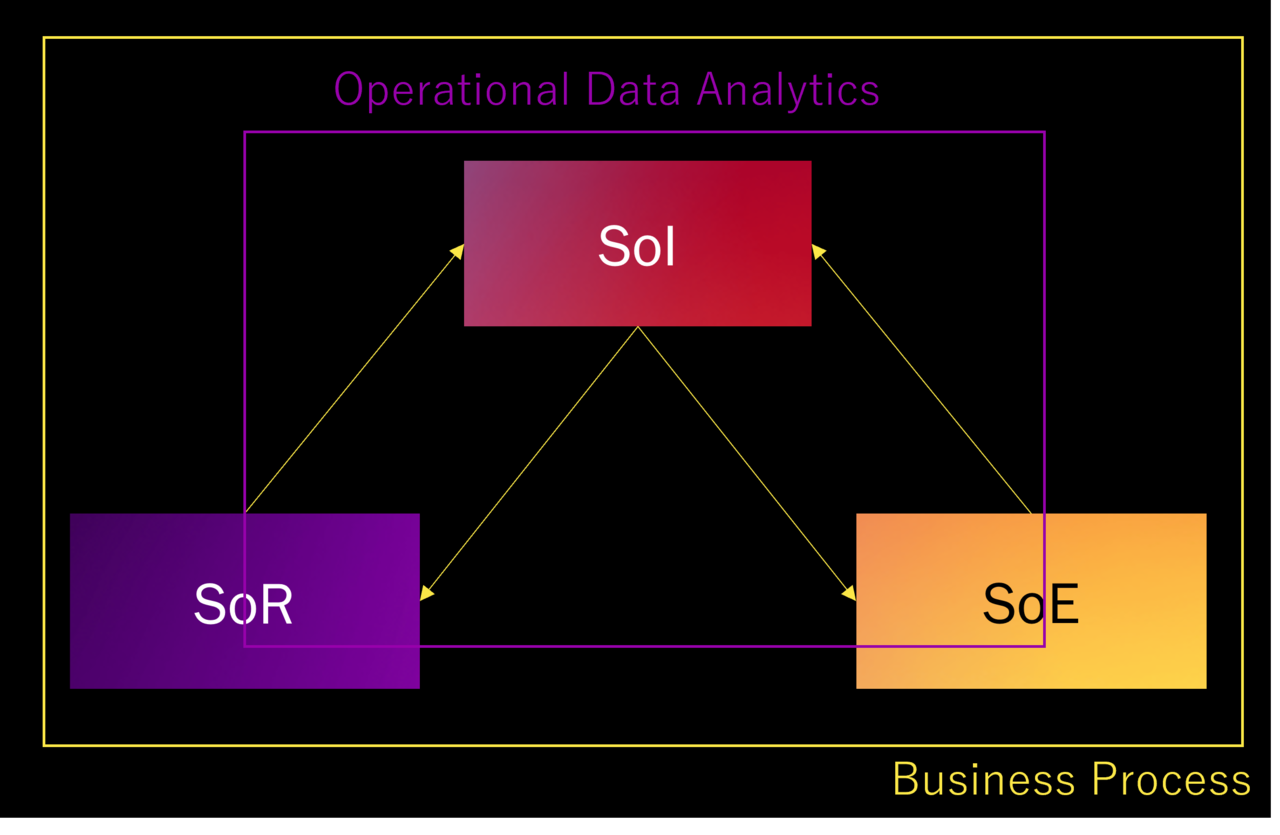
次に現地で理解したUSにおけるAnalyticsのイメージです。
まず、一番の違いは、SoIからSoR, SoEへの戻りの矢印がある点です。
これはSoIで得られた結果をSoRやSoEにフィードバックするプロセスが自動化されているという意味です。
これをOperational Data Analyticsと呼んでおり、これがすなわちAnalyticsにあたります。
SoI, SoR, SoEをまたぐData ProcessingもOperational Data Analyticsの範囲に含まれます。
業務プロセスとの関係で言うと、Analyticsは業務プロセスの中に包含されているイメージになります。
なお、この内容はあくまでイメージで、実際は日本でも「USにおけるAnalytics」を実現している例は局所的に見ればあります。
たとえば小売業における需要予測型の自動発注や、製造業におけるFAの異常検知などですね。
ただ、残念ながらこれらも多くの場合は「自動発注システムを導入する」という意識なので、こういった概念に落とし込めているかというとそうではないかと思います。
所感
今後日本においてもSoR, SoEへの戻りの矢印のユースケースの創出・提案がポイントになってくると考えます。
日本の現状ではDWHに蓄積するためにはじめてクラウドに乗ってくるデータというのが多数あります。
DWHにしか揃っていないデータがあることで、今後DWHを核にしたシステムが増えていく予兆は国内企業からも感じられます。
どういうデータを業務プロセス側にフィードバックできるかという点は私たちのお客様とも話しながら考えていきたいと思っています。
また、戻りの矢印の出所を考えたときに、矢印の基点がBIだけだと戻せる情報に限りが出てきます。
基点がどこかと考えたときにAI,MLの重要性が高まっていくことは間違いないでしょう。
A Zero ETL future…
2日目のKey Noteの中で私たちにとって衝撃的なメッセージがありました。

雑に要約すると「ETL Pipelineは開発者にとって痛みを伴うものだ、だからETLのない未来を作る」という話です。
これはAnalytics文脈の話であるので、それを念頭に置く必要があります。
Zero ETLに関わる発表を個人的な視点から抜粋すると以下になります。
- 1.Data Ingestionに関するもの
- Amazon Aurora zero-ETL integration with Amazon Redshift | 11/29 Keynote
- Informatica Data Loader for Amazon Redshift | 11/28 Keynote
- Amazon Redshift now supports auto-copy from Amazon S3 | 11/30 Keynote
- 2.Data Preparation, Data Transformationに関するもの
- Amazon Redshift integration for Apache Spark | 11/29 Keynote
- Amazon Athena for Apache Spark | 11/30 Keynote
- 3.その他
- Amazon Data Zone | 11/29 Keynote
Data Ingestionとは
「Data Ingestionに関するもの」とかさらっと書いていますが、そもそもData Ingestionとは何かということに触れます。
広く知れ渡っている概念のどの辺の話に関連するかというと、ETLにおけるL、つまりデータのロードに関連する話です。
まず、ETLではなくELTだということはかなり前から言われていることです。
これは順序の話で、TransformしてからLoadするのではなく、LoadしてからTransformしようという考え方ですね。
データを取り込む側が形を定義するのではなく、使う側が欲しい形で抽出すればよいという"schema on read"という考え方とあわせて理解する必要があります。
この説明に時間の概念とか責任分解点の概念を加えると、DWHのようなデータストアにデータを取り込む人はとりあえずありのまま入れておく、データサイエンティストなどデータを使う人が欲しいタイミングで欲しい形にTransformしながら読み込むという話になります。
そもそもDWHにデータをそのまま入れるだけであれば、設定だけで勝手に取り込んでほしいですよね。
こうして生まれたのがData Ingesitonです。(たぶん)
一番イメージしやすいのは、SnowflakeのSnowpipeです。
S3やBlob StorageなどのオブジェクトストレージのイベントなどをきっかけにDWH内にデータをロードしてくれます。
実際は定義があいまいな概念なので、Azure SynapseのPolybaseのようなデータ仮想化の仕組みや、Apache Kafkaのようなストリーミング処理の仕組みもData Ingesitonとすることがあります。
Data Ingestionで戦わない
Data Ingestionという概念が登場した経緯からすると、この領域でETLが勝負する必要はないかなと思います。
先ほど紹介したZero ETL Futureに関連するサービスではData Ingestionに関するものがいくつかありましたが、
これは既定路線であり新しい脅威ではないと思っています。
現時点でのData Ingestionはあくまで単一のクラウド内での話が主であり、じゃあS3までどうやってデータを持っていくんだとかマルチクラウドの場合はとか少し外に目を向ければそこがETLの主戦場になってきます。
特に日本の場合はソースとなるデータはまだオンプレミスが大多数を占めますよね。
そういう観点でZero ETL Future...というメッセージを見ると、この発表に脅威を感じているのは私たちのようなETLのメーカーではなくSnowflakeやTreasure DataのようなAWSをラップして前を走っていたプラットフォーマーではないかと思います。(先行してData Ingestionの仕組みを実装していたので)
アーキテクチャの話(興味がない人は飛ばしてください)
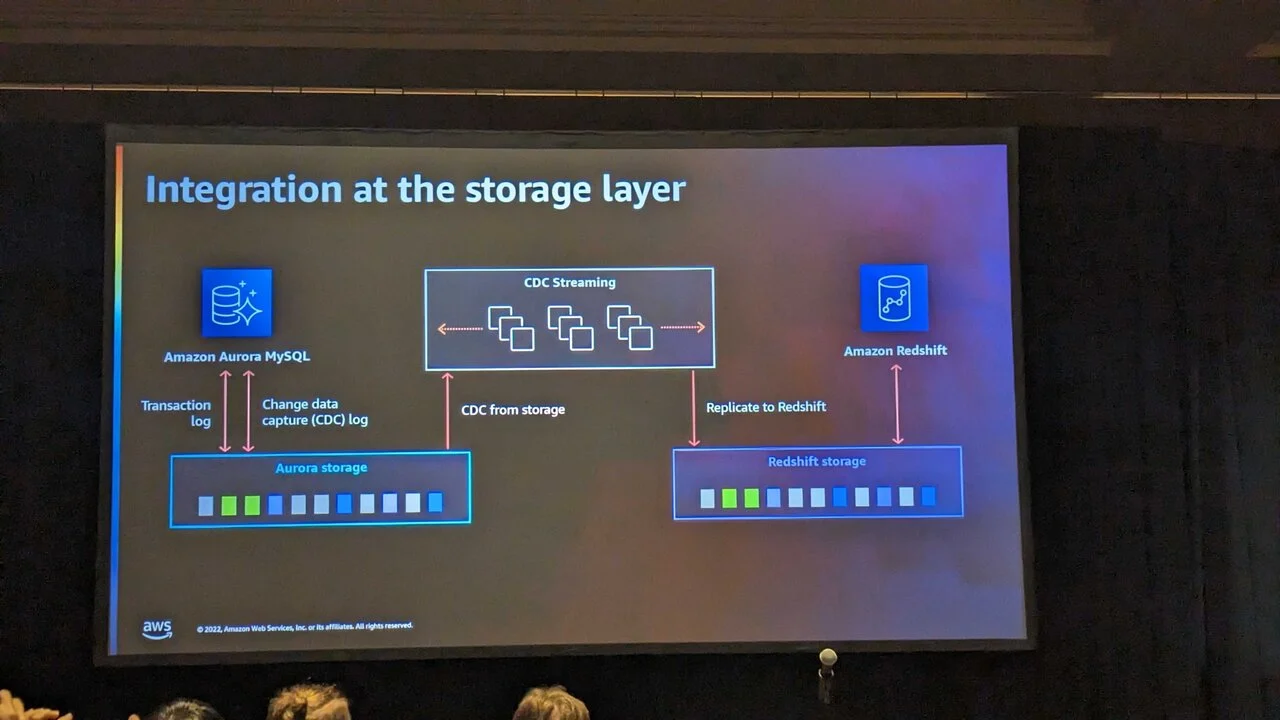
アーキテクチャ的に見ると、Amazon Aurora zero-ETL integration with Amazon RedshiftにおいてはAuroraのTransaction logを使用してLog-Based のChange Data Capture(CDC)を元にストレージのレイヤーで同期します。
CDCとは何かというと、データの差分を抽出するための仕組みです。
Amazon Aurora zero-ETL integration with Amazon Redshiftを端的に言うと、「AuroraをRedshiftに自動的に同期します、同期の方式は差分連携です」ということを言っています。
CDCには色々な方式があって、最もよく使われる方式はAudit Columnsというタイムスタンプを使った方式です。
そして現在最も高速な仕組みは、Log-BasedのCDCで、これはいわゆるREDOログを元に差分を連携します。
Amazon Aurora zero-ETL integration with Amazon RedshiftはLog-Basedを採用した上に転送もストレージレイヤです。
これは先行して実装されているサードパーティのData Ingestionの機能に比べて圧倒的に最適化されています。
サードパーティからするといままで先を走っていたと思っていたら、一気に抜きさられた気分ではないかと思います。
所感
ETLのキーワードはやはり越境だとあらためて認識しました。
いったんクラウドに乗るとすべて繋がってしまうという世界観になってしまうので、
- オンプレ-クラウド/クラウド間の越境
- SoIからSoR,SoE戻す矢印(領域の越境)
このあたりがポイントになってきます。
また、従来通りPreparationやTransformationも勝負どころになってきますが、ここと真っ向で対立するのがAmazon Redshift integration for Apache Sparkになってくるかなと思います。
(既にクラウドETLはJupyter NotebookやDatabricksなどのSpark上で実行するNotebookと組み合わせることが定番になっていますが、それがZero ETLになっていくという文脈になります。)
ただしSparkは高速ですがOut of Memoryとの戦いにもなりますし、そもそもSQLが書けない人もいることを踏まえるとこの領域はETLとZero ETLが共存していくのではないかなと予想しています。
(共存したらZeroじゃないじゃんというのは置いておいて)
私個人は、Zero ETL Future...というメッセージは「おしゃれな打ち出し方だなぁ」くらいの気持ちで受け取っています。
終わりに
最後に少しだけイベント自体の話をしようかと思います。
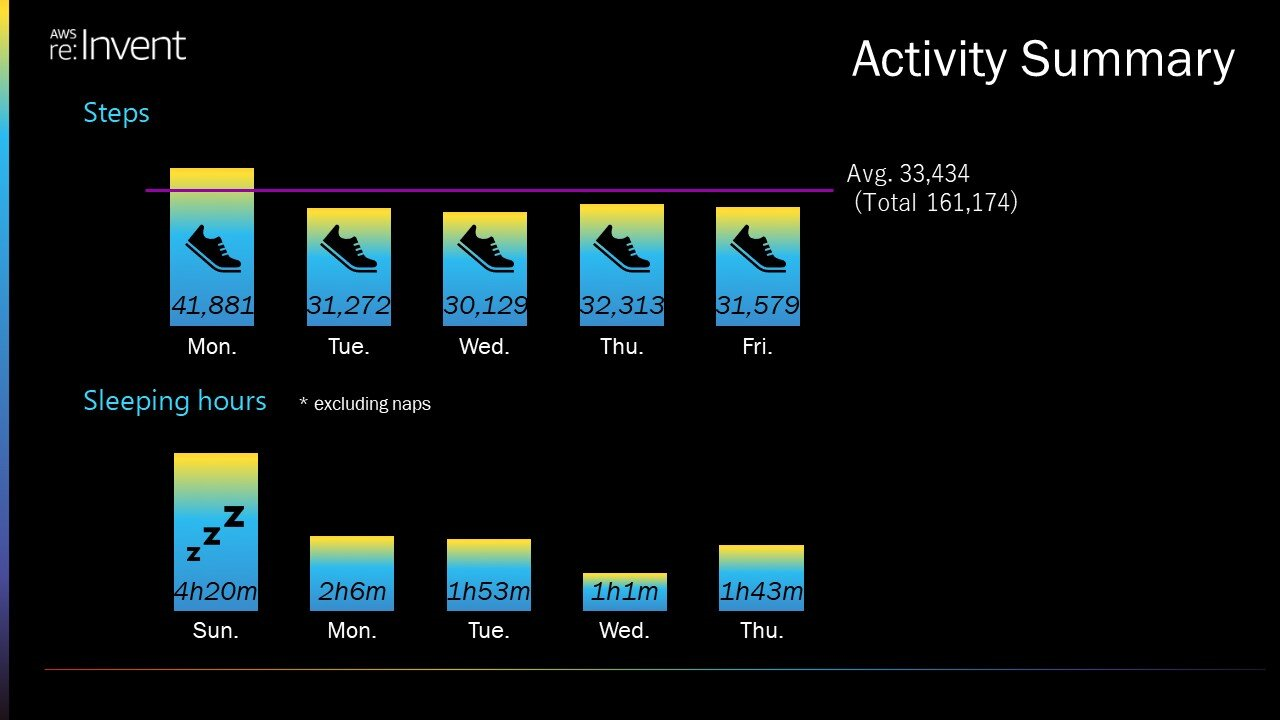
これは現地での歩数と睡眠時間をあらわした絵になりますが、よく歩き、全然寝ていないという日々を過ごしました。
周囲のメンバーに変迷惑をかけましたが、日常の業務を離れ技術に向き合う5日間は大変刺激的な日々でした。
あらためてこういった機会をいただいたことに感謝するとともに、多くのみなさんにも同じ興奮を味わってほしいなと願っています。

これはAWS re:Invent 5KでFrank Sinatraドライブというメインストリートを5km走ったときに見た景色です。
このときに一緒に走った男性はUnited Airlineで働いている非エンジニア職の方でした。
片言での会話でしたが「テクノロジーの理解は誰でも必要で、エンジニアかどうかは関係ない」みたいなことを言っていました。
現時点の技術力がどうかとかはあまり関係はなく、この男性の言っている通りだと私も思います。
機会があればぜひ行きたいという人がひとりでも増えるといいなと思いこのエピソードを書きました。
最後まで読んでいただきありがとうございました。
執筆者プロフィール

高坂 亮多
- ・2007年 新卒で株式会社セゾンテクノロジーに入社。
- ・所属:DI本部DP統括部 DP開発1部 副部長 および DP開発1課 課長 兼務
- (所属は掲載時のものです)
- ・好きなこと:登山やキャンプなど アウトドアアクティビティ
- ~ BI基盤(分析基盤)におけるアーキテクトとして日々業務にあたっています ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか