〈開発者ブログ 連載〉Vol.14
~ データの可視化・分析について ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか

2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか
データ分析・可視化に関する記事の14回目です。
以前、"Analytics"から見たAWS re:Invent という記事の中で以下のような趣旨の記述をしました。
という記事の中で以下のような趣旨の記述をしました。
DataQualityなどは日本ではデータ人材の不足により実現が難しい状況になっている。
一方で、パワー不足が原因であれば生成AIのエンパワーによって状況を変えることが出来る可能性がある。
で、それって本当ですかね?
そういえば何も検証してないじゃんと思い少しだけテストしてみました。
2時間くらいで検証して記事まで書いたのでクオリティの低さはお許しください。
Data Qualityってなんだっけ
データに対して閾値を設定し、そこから外れたらアラートを出す、という仕組みがData Qualityのツール/サービスとして提供されています。
これらも活用しながらデータの品質を確保していくためのプロセスがData Qualityです。
何を見るか、については私の過去記事を見てほしいですが、主に以下の5つです。
- Freshness
- Distribution
- Volume
- Schema
- Lineage
Volumeとかはわかりやすいです。
毎日これくらいのデータが発生するはず、というものに対して発生数が不足していれば何か異常がおきてそうですよね。
ポイントは、しきい値の定義と、アラート発生時の判断です。
特にアラート発生時の判断については人が介在するので手間がかかりそうですね。
ということで、Volumeを対象に簡単にテストしてみます。
Volumeの観点から品質を見る
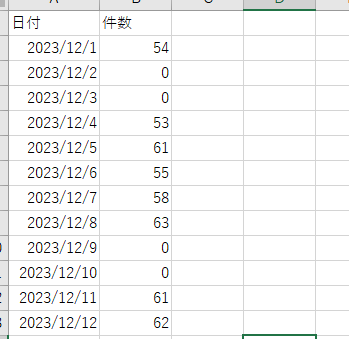
画像は切っていますが、実際は1か月分
これはあるSlackチャンネルの日付別の投稿件数です(スレッドを含む)。
勤怠連絡をするチャンネルなので、平日はそれなりの件数の投稿があり、休日は当然ですがほぼ0です。
※投稿をPythonで取得してDataframe化して集計したものです。
これをベースのデータとして、ある日の発生データに異常がないかを生成AIに聞いてみようと思います。
生成AIは当社のSlack botを利用します。
なお、異常値検知は本来は生成AIではなくて従来型のMLの得意分野です。
従来型のMLで異常値を検出できることはわかっているのですが、LLMでの判断の精度を見てみようと思いました。
プロンプトはいったん以下で試しました。
2時間検証なので最初に頭に浮かんだプロンプトです。
- 以下の#データは#過去の履歴と照らし合わせて異常値ですか?
- #データ
{チェックしたい日のデータ} - #過去の履歴
{過去1か月分のデータ}
プロンプト
まずは、1/17のデータを検証します(57件)。これは実データです。

回答は以下です。
週末とかも加味していてなかなかいい感じです。

ということで、休日も聞いてみます。1/14日曜日は0件です。人が見れば異常値でないとわかりますね。
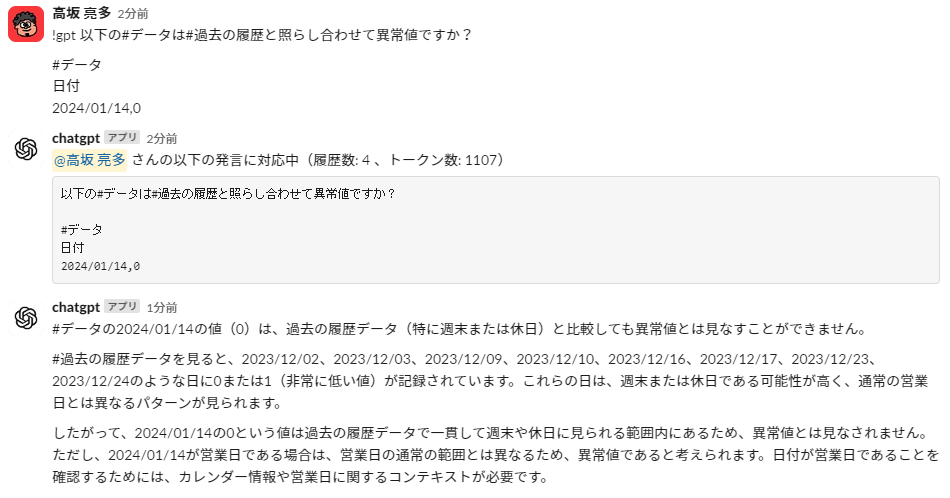
これも結構いい感じです。
次に架空の異常値を渡してみます。1/18が5件という架空のデータです。
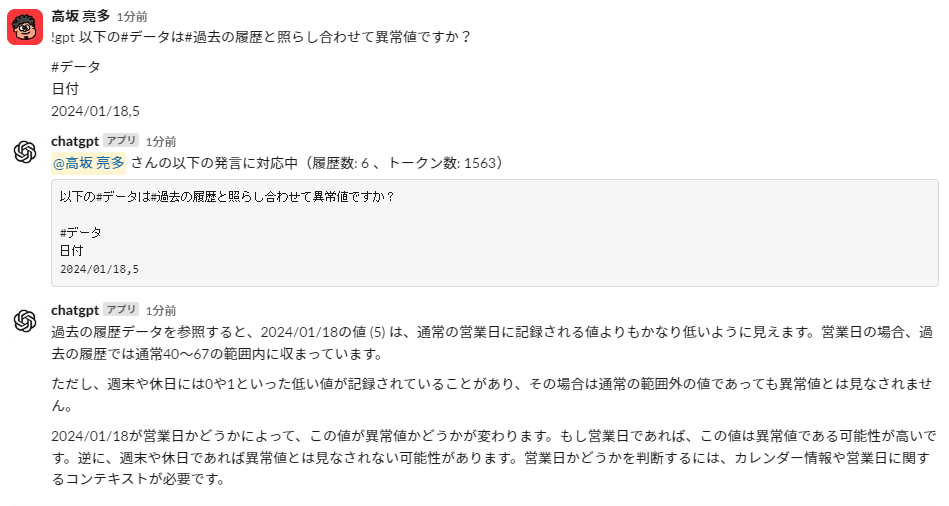
色々言ってはいますが、正しい判断が出来ていそうです。
色々の部分も正しい指摘ではありますね。
Volumeの部分は作りこめば使えそうな気がします。
Distributionの観点から品質を見る
次にDistributionも見てみましょう。データの分布を見るものですね。
日付ごとの投稿ユーザーの分布を見てみます。
プロンプトは先ほどと一緒で、データの中身を日付/ユーザーごとの集計値に変えただけです。

、、、日付/ユーザーごとに渡すと量が多すぎるようです。
テストするだけなので、件数を絞ってやってみます。

考え方も含めてなかなか良さそうな感じです。
これはもうちょっと作り込みたくなりますね。
まとめ
ということで、簡単にですがテストしてみたところもう少し検証を進めてもいいかなという感触を得ました。
生成AIではない従来型MLと組み合わせることでそれなりのものが出来そうな気がします。
記事を読むと異常の検出を生成AIに任せたみたいに見えてしまいますが、検出後の判断を見てみたいというのが趣旨になります。
実際のツールでは検出と、その異常データの疑いがあるデータの特定までしてくれるので、補うべき部分は判断です。
もうちょっと良いものを作ってから記事にする選択肢もありましたが、いったん勢いのままに出すことで誰かの何かのヒントになればと思いました。
以上です、最後までお読みいただきありがとうございました。
執筆者プロフィール

高坂 亮多
- ・2007年 新卒で当社に入社。
- ・所属:DI本部DP統括部 DP開発1部 副部長 および DP開発1課 課長 兼務
- (所属は掲載時のものです)
- ・好きなこと:登山やキャンプなど アウトドアアクティビティ
- ~ BI基盤(分析基盤)におけるアーキテクトとして日々業務にあたっています ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか