〈開発者ブログ 連載〉Vol.10
~ データの可視化・分析について ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか

データを取り巻く言葉や概念を理解するために
データ分析・可視化に関する記事の10回目です。
今回はデータ周辺の潮流を追うための前提となる知識について書いていきます。
なので詳しい人向けの説明ではないはずなのですが、そう見えない長文になってしまいました。
読者を選ぶとは自覚していますが、読んでおいて損はない、、はず。。。
"コンピュートとストレージの分離"とデータ形式の標準化
データを扱うための重要な概念に"コンピュートとストレージの分離"があります。
まずはアーキテクチャの面での説明をします。
ここ10年くらいで大規模データの処理性能は飛躍的に伸びましたが、理由はいくつか挙げられます。
- データ圧縮技術と分散配置によるI/O性能の向上
- 分散配置されたデータを統合するN/Wパフォーマンスの向上
- I/Oに代わりボトルネックとなったCPUを解消するための分散処理
分散処理においては、データをどう分割して各コンピューティングクラスターに渡すが重要になってきます。
単一のデータを処理するわけではなく、データの結合なども発生するので、これは複雑な問題です。
分散しての格納効率(読み出し効率)と処理効率とは全然別の話だということですね。
仮にデータを60領域に分散格納した場合、コンピューティングクラスターも60ノードに固定されてしまったら都合が悪そうです。切り離したくなってきますね。
こうしてストレージ領域とコンピューティングクラスターは分離されるようになりました。
この分離により、ストレージとコンピューティングを別々にスケーリングすることが可能になりました。
データを永続化するために、コンピューティングリソースを常時立ち上げておく必要もありません。
SnowflakeやBig Queryが誕生時点で明確にRedshiftやSynapseより優れていたのはこの点です。
ビジネス観点でのメリット
コンピュートとストレージの分離"はアーキテクチャのみならず、ビジネス観点から見ても重要です。
現実世界を見たときに、保有データというのは全社の共有アセットですが、データ分析のためのリソースはどうでしょうか。
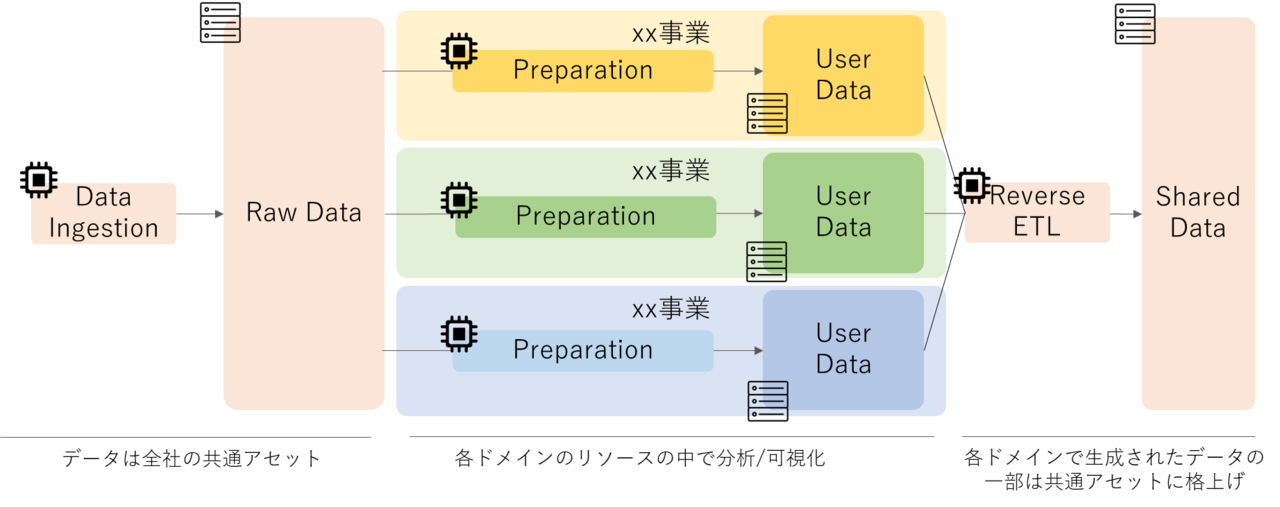
ある事業ドメインに関する分析をするために必要な処理コストはその事業ドメインで負担すべきという意見もあって然るべきかと思います(何が正しいかは成熟度によっても異なります)。
仮にそれを実現しようとなった場合、コンピュートとストレージが分離されている必要がありますね。
ストレージ領域は全社コストで、コンピュートはそれぞれの事業ドメインのコストとする設計が実現可能になります。
分析者(開発者)にとってのメリット
他にもコンピュートとストレージの分離によって出来るようになったことがあります。
それが、同一のデータに対して複数のエンジンを使い分けるという点です。
たとえばCDPであるTreasure DataのPlazma DBでは、同一のデータに対してクエリ発行時にクエリエンジン(Hive or Presto)を選択することが出来ます。
「クエリ発行時にエンジンをORACLEにするかSQL Serverにするか選択できるようなもの」と説明するとその凄さが理解できる方もいるのではないでしょうか。
エンジンを使い分ける理由は得意分野(アドホックとバッチ)が違うためで、分析者は選択肢が増えた形になります。
これが実現できた要因には、コンピュートとストレージが分離されたという点と、分離されたことによってデータ形式の標準化が進んだという点も挙げられます。
Open Table FormatsとData Lakeの進化
このデータ形式の標準化は、Open Table Formatsという形でいくつかの取り組みが進んでいます。
代表的なものは以下の3つで、すべてオープンソースのプロジェクトになっています。
- Delta Lake
 (Databricksによって開発がスタート)
(Databricksによって開発がスタート) - Apache Iceberg(Netflixによって開発がスタート)
- Apache Hudi (Uberによって開発がスタート)
説明の流れでデータ形式の標準化から話ましたが、これらには従来のData LakeにはないACID特性が付与されています。
この特徴により、従来DWHが担っていた役割もData Lakeだけで実現ができる(DWHなんて要らない)ということでLakehouseと名乗ったりTransactional Data Lakeと名乗ったりしています。
本質はDWHのストレージレイヤーが分離されてオープンな仕様になったというのが正しい理解に近いかなと思います。
今後Lakehouseという言葉や、Data Lakeの拡張という概念はみなさんも目にする機会が確実に出てきます。
セマンティックレイヤー
次にセマンティックレイヤーについて解説します。
セマンティックレイヤーというのはセマンティックデータモデルを実装するためのレイヤーです。
要はデータの物理的な配置とアプリケーションの間に論理的な層を設けてデータの意味付けをしましょうということで、これは手法としてはリレーショナルデータベースしかなかった時代からよく使われています。
たとえば、受注情報を第3正規形に正規化すると、一般的に受注ヘダーと受注明細にテーブル構造として分離されます。
これを予め結合したVIEW(受注VIEW)を用意して、受注情報という意味付けをすることは昔からよく見る実装です。
このケースのVIEWも広義のセマンティックレイヤーになります。
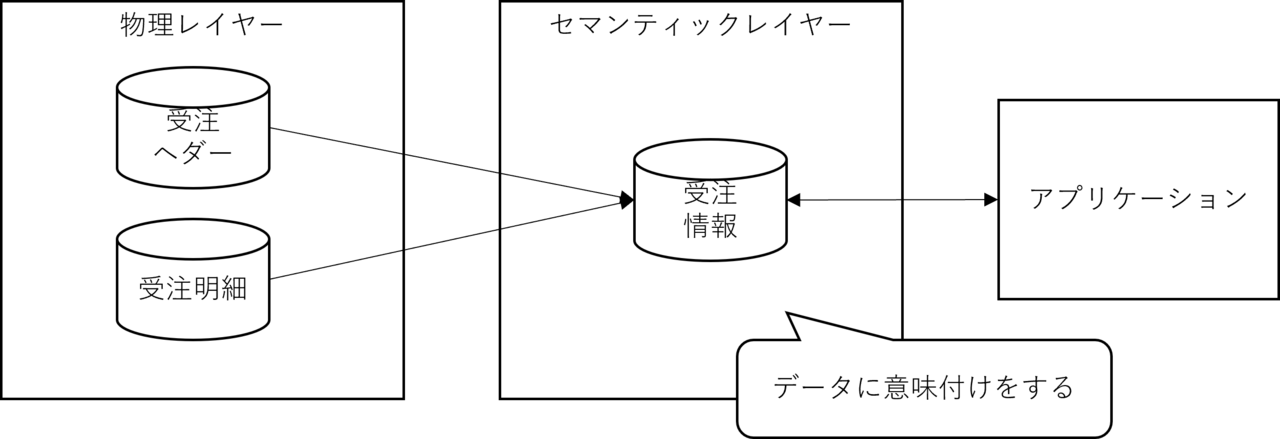
セマンティックレイヤーの主目的はその名の通りデータの意味付けになりますが、副次的にもメリットがあります。
ソースデータとアプリケーションが疎結合になることで、変更に対して強くなるという点です。
実際にはセマンティックレイヤーというよりは、論理的なレイヤーを設けることによるメリットです。
ソースデータとアプリケーションの間に論理的なレイヤーを設けるといいことがあると覚えてください。
特にBIはインプットデータの差し替えが日常的に発生しますので、この観点から見ても有用です。
TableauなどBI製品の多くにはセマンティックレイヤーを実現する機能が搭載されています。
そう、BI製品にこの機能は実装されているのです。
せっかくソースデータとアプリケーションを疎結合にしたのに、実態はアプリケーション製品と密結合になっています。
BI製品を切り替えたらセマンティックレイヤーは全て作り直しになります。
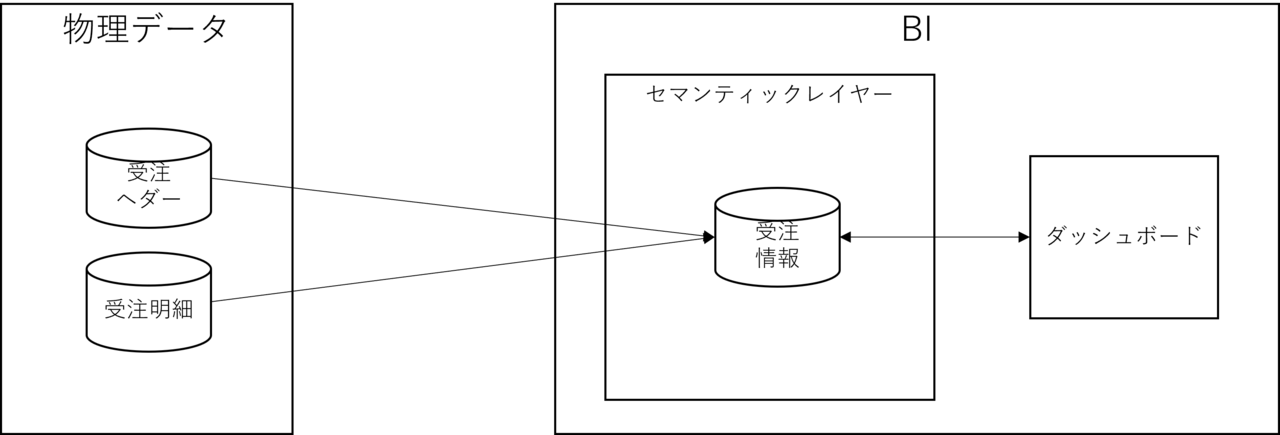
この密結合の状態を解消するためには、セマンティックレイヤー(論理レイヤー)をBIの枠から出す必要があります。
※つまり、一つ前の絵の状態に戻します。
さらに疎にするために、格納場所(ストレージ)の分離も含めると次のような絵になります。
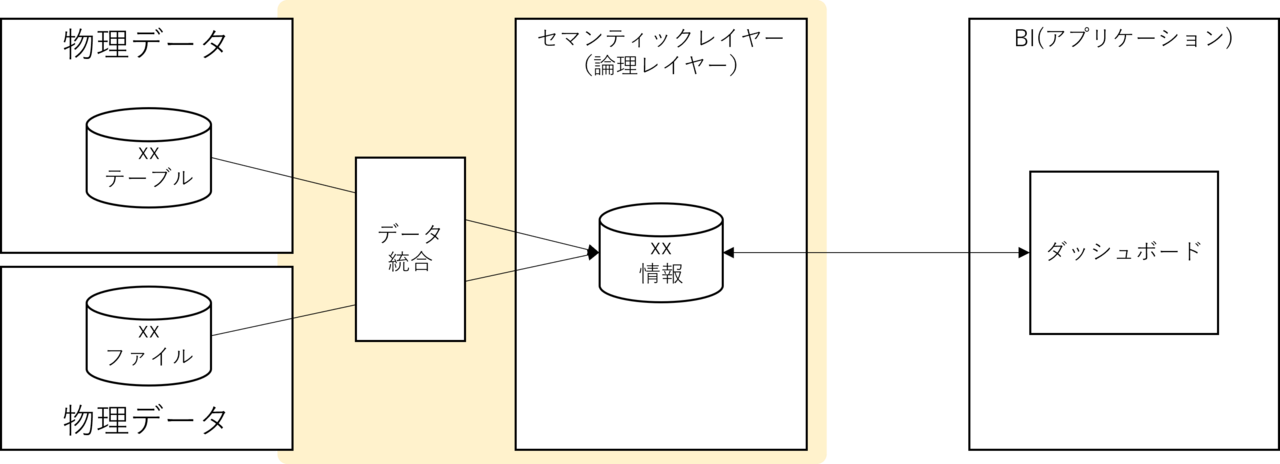
そして、この絵の黄色い部分を実現するための製品/サービスというのは既に存在します。
それがデータ仮想化のサービスや製品です。
データ仮想化製品/サービスは本当に素晴らしいのか
世の中には「ETLなんて要らない!」と声高に叫んでいる人たちが居て、そのひとつがデータ仮想化勢です。
データ仮想化製品/サービスは、この論理レイヤーを物理的にデータを持たずに実現すると謳っています。
ここまで記事を読んでいる方は、論理レイヤーのメリットが理解できたと思います。
一方で、論理レイヤーを物理データを持たずに実現するとなると違和感を持つ方もいるのではないかと思います。
RDBでVIEWを多用しすぎたために、パフォーマンスの問題に直面した経験のある人は多いですね。
実体を持たないデータには常にこの問題が付きまといます。
ましてはデータ仮想化の場合は、ネットワークをまたぎますのでネットワークへの負荷も考慮しなくてはなりません。
入口要件/出口要件には対応できるでしょうか。
リネージュを含めたメタデータの付与ができずにデータの品質は担保できるでしょうか。
一番の問題は信頼できる唯一の情報源 (Single Source of Truth; SSOT)の確保です。
これはデータ分析の観点でみると、DWHとその周辺のETLを含めたエコシステムで実現されています。
前提を持って見てみる
冒頭にあげたData Fabricについてもっとも中立的な定義はガートナーの定義です。
ガートナーの定義ではData Fabricではデータ仮想化が重要だと言っています。
ここで言っているデータ仮想化とは概念の話で、要はセマンティックレイヤーを設けよう、メタデータもフル活用してセマンティックモデルの完成度を高めようということです。
これをデータ仮想化勢が、データ仮想化製品/サービスがないと実現できないような説明にトーンを変化させています。
セマンティックレイヤーでデータの意味付けをすることや、ソースデータとアプリケーションの疎結合は重要です。
ただ、それは論理レイヤーの実現に物理データを使うか使わないかは本来関係ありません。
疎結合にするのは、ソースデータとアプリケーションであり、BIツールのセマンティックレイヤーの機能もデータを実体として保持するケースの方が多いです。
論理レイヤーのデータを物理的に保持する、というのはデータマートを作ると言っているのと非常に近いです。
多くの場合データマートの実装でも十分に用を成すのではないでしょうか。
データを取り巻く言葉や概念の本質を見るためには、コンテキストの理解が必要だと思い、今回の記事を書きました。
相変わらず長文になってしまいましたが、この記事が誰かの役に立てば幸いです。
最後まで読んでいただきありがとうございました。
執筆者プロフィール

高坂 亮多
- ・2007年 新卒で当社に入社。
- ・所属:DI本部DP統括部 DP開発1部 副部長 および DP開発1課 課長 兼務
- (所属は掲載時のものです)
- ・好きなこと:登山やキャンプなど アウトドアアクティビティ
- ~ BI基盤(分析基盤)におけるアーキテクトとして日々業務にあたっています ~
開発者ブログ 一覧
- Vol.01 データの可視化は○○○○
- Vol.02 その分析に○○は含まれるか - メジャー編 -
- Vol.03 その分析に○○は含まれるか② - ディメンション編 -
- Vol.04 データの品質について考える
- Vol.05 "Analytics"から見たAWS re:Invent
- Vol.06 データ利活用におけるデータガバナンス
- Vol.07 データを分類する
- Vol.08 データレイヤーと内製化
- Vol.09 データプラットフォームとDX推進
- Vol.10 データを取り巻く言葉や概念を理解するために
- Vol.11 データを取り巻く言葉や概念 - Modern Data Stack -
- Vol.12 Single Source of Truth
- Vol.13 わくわくを忘れずに
- Vol.14 2時間検証:データ人材の不足は生成AIのエンパワーで補えるのか