![]()
![]()
 シンプルに構築できる上、効果も実感しやすいAI活用パターンのひとつ「需要予測」
シンプルに構築できる上、効果も実感しやすいAI活用パターンのひとつ「需要予測」
〜 呼量予測AIパターンの構築 〜


近年、急速に注目が集まっているAIだが、金融業界では業界、事業の特性上、いち早くAIを取り入れようと注目。金融は高いセキュリティ性はもちろん、リアルタイム性が求められるほか、銀行に関しては支店やスタッフの数が多いことから、AI活用が業務効率化、省人化につながると期待されていた。
しかし、新しい技術、概念を導入するため、非常に多くの壁もある。今回は、2023年2月に発刊した書籍『金融AI成功パターン』で第四章の執筆を担当したSBIホールディングス株式会社 社長室ビッグデータ担当の橋詰創一郎氏に、金融業界でのAI活用のひとつ「需要予測パターン」の構築について解説いただいた。
▼プロフィール
一般社団法人金融データ活用推進協会 企画出版委員会
SBIホールディングス株式会社 社長室ビッグデータ担当
橋詰創一郎氏
※役職や所属は取材時のものです。
SBIホールディングスに入社してすぐ需要予測のチームへ
まず自己紹介をいただけますか?
私は鍋倉(『金融AI成功パターン』第二章ターゲティングAIパターン解説記事)と同じSBIホールディングスの社長室ビッグデータ担当として、グループ内のビッグデータ活用を主導しています。SBIグループに入社したのは3年前で、初年度にはSBI損保の呼量予測のプロジェクトチームに参加しました。
呼量予測とは、コールセンターの入電量を予測するということです。お客様がコールセンターに電話をかけてオペレーターと繫がった”数”を時間ごと、曜日ごと、季節ごとなど、入電量を予測。オペレーターの適切な数、配置に役立ちます。
こうしたビッグデータやAIを使ったプロジェクトやAWSの分析基盤の立ち上げのほか、CoE(センターオブエクセレンス、部署横断型) 組織の構築、市民データサイエンティストの育成など、啓蒙活動も任されています。
今回は先ほど説明した「呼量予測」など、需要を予測するAIについて解説いたします。
金融業界が需要予測に期待していることは?

金融業界で需要予測AIはどのような効果を期待されているのですか?
金融機関では、コールセンターを設置していることや支店が多いという特徴があります。そのため、需要に合わせて人材やリソースを最適化することが求められています。この需要の予測は、担当者の経験と勘に頼ることが多く、属人的に行うと細かい粒度での予測ができないという問題が生じます。だからこそ、AIで需要予測を行います。
経験や勘は人によって変化してしまうものです。AIであれば需要をより正確に予測し、経験と勘に頼らなくても人材やリソースを最適に配置することが可能になると考えています。
具体的にAIを活用した需要予測の例はありますか?
今回はコールセンターの需要予測やATM需要予測をご紹介します。
まずはコールセンターの需要予測ですが、前述したようにコールセンターでは常に人員配置、要はシフト作成の業務が発生します。単純な例ですが、昼間10人配置して、夜間も同じ10人配置していたとします。常識的に考えると、昼間より夜間のほうが電話の量は減ることがわかりますので、不適切なシフトになりますよね。
「新しい金融サービスを発表したとき」、「提携や合併などを発表したとき」は通常より人員を多く配置する必要があります。こうした時間帯やニュースのほか、季節ごと、曜日ごとでも変化が出てきます。AIを使って過去の同じ条件を分析し、適切なシフトを見出すことが可能です。
人件費の削減に繫がると言うことですか?
適切なシフト作成もそうですが、そもそもの採用活動でも活用できると考えています。新たに金融サービスを発表した際は短期的にオペレーターの数を増やす必要がありますが、企業や事業の成長度に合わせて顧客が増えていくことがわかる状態なら、長期的なオペレーターを増やしていく、つまりは採用計画を行う必要が出てきます。その際に、「何人採用をすればいいのか」などに活用できますよね。
コールセンターを例に挙げたのは、需要予測の活用の幅がとても広く、スタートするためのデータの準備が非常にシンプルなので「始めやすい」ところもあります。

【動画スライド7から引用】*
『金融AI成功パターン』より抜粋。金融業界でのAI活用、需要予測例の一覧
*記事の文末に解説動画をご紹介しています。
需要予測AIパターンを構築する際に準備したデータ
具体的にコールセンターのAI需要予測の構築についてお話しいただけますか?
コールセンターの需要予測は「呼量」の予測を行うということです。呼量とはコールセンターにかかってくる単位時間当たりの電話の量を指します。そして「呼量予測」は、過去の呼量の傾向を学習し、将来の呼量を予測することを言います。
それでは具体的に見ていきましょう。
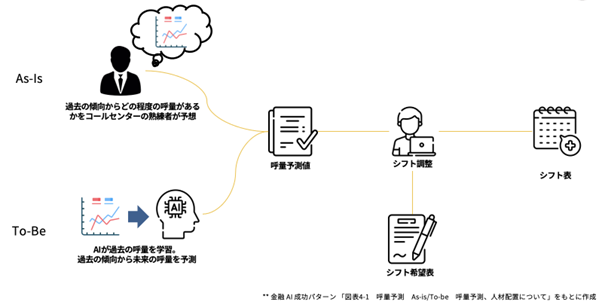
【動画スライド10から引用】*
オペレーターのシフト調整に利用したい場合
*記事の文末に解説動画をご紹介しています。
As-Is、つまり現在は熟練者が経験と勘で呼量を予測している状態。To-Be、目指すべき状態はAIが呼量を予測している状態です。そのあとのプロセスは実は同じ。シフト作成や採用活動を行う上で、基にするべきデータが”人”か”AI”かの違いというだけです。端的に言えば、「AIに置き換えていく」プロジェクトです。
データソースについて教えていただけますか?
それを話す上でまずは「得られるデータはどのようなものか?」を考えます。コールセンターの場合は電話がどの回線から何の用事で掛けられているかのデータが得られます。具体的に得られるデータを解説します。
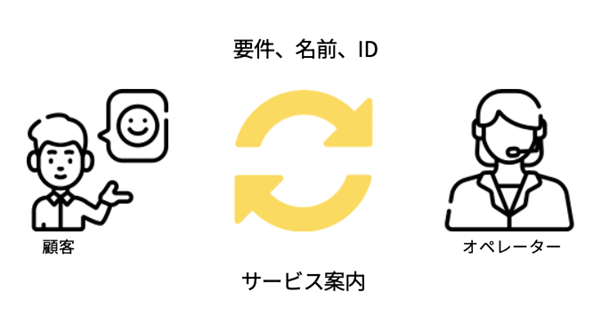
【動画スライド13から引用】*
コールセンターとそこから発生するデータ
*記事の文末に解説動画をご紹介しています。
顧客から電話がかかってきた、これを識別するためのIDが振られます。同じ顧客から別の問い合わせで電話がかかってきた場合は、当然別のIDが振られます。そしてコールのあった窓口、コールがあった日付、通話が繫がったか繫がらなかったか、通話の開始時間、応答していた時間、オペレーターが入力するメモなど。
主にこうしたデータがコールセンターでは記録されています。そのほか、音声記録などもありますよね。
そのデータだけで需要予測AIは構築できるのですか?
もちろんこれだけではありません。カレンダーのデータ、要は祝祭日などの基本データも必要です。上記だけだとGWなど大型連休がある月は「呼量が少ないから人員を減らそう」と誤った判断に繫がる恐れがあります。もちろんそんなことは起きませんが、AIが適切に判断できる要素は入れておくべきです。
上記以外では、マーケティング活動で得たデータ、契約者の数、アプリケーションの問い合わせ窓口であるならばアクティブユーザー数など、コールセンターに電話がかかってくる要因となりそうなデータも用意しておくといいでしょう。コールセンターに電話がかかってくる要因となるデータ=呼量予測の予測精度を上げるデータにつながります。
モデリングを行うためにデータソースを加工していく
データの準備ができたあと、次のアクションについて教えてください。
私は次の4手順で考えています。
1:モデル構築方法の決定
2:ターゲットデータの作成
3:特徴量データの作成
4:モデリング
まずモデルの構築方法の決定です。つまり予測の単位を決定する、具体的に言えば「いつ、なにを、どれくらい」予測するのかを決定します。呼量予測の場合は、特に予測期間の設定は重要です。
今回は、呼量予測の結果を「毎月20〜25日に出力する」ように設定します。その際に欲しい予測データは「翌々月に起きる呼量」。予測する幅は「一か月分」で、予測量は「1日あたりの呼量」。予測の種類は「呼量の合計」です。
そして特徴量、つまり予測データを得るための期間を選択する。今回は、前日までの呼量と、曜日、土曜日、日曜日、祝日、連休、3連休、月初、月末などの日付に関するデータを特徴量として使用します。
ターゲットの作成について教えていただけますか?
先ほど「スタートするためのデータの準備が非常にシンプル」とお話ししましたが、呼量予測の場合はデータの作成が容易なんです。先ほど予測量を「1日当たり」と決定したので、yyyymmmmdddd、つまりは日時を指定する。時間帯も知りたければ、hh:00:00、時間を指定すればいい。そして単位時間当たりの電話の数を呼量として集計していきます。
このように呼量予測ではデータソースは非常にシンプルです。
▶『金融AI成功パターン』第二章ターゲティングAIパターン解説記事
学習モデルを作成、特徴量をどう設定したのか?
データソースが揃ったので、AIの学習モデルについて教えていただけますか?
先ほどの呼量の特徴量を作成していきます。特徴量を作成する方法は多々ありますが、今回はラグ変数の紹介だけさせていただきます。
ラグ変数とは、目的変数を予測するための特徴量の一つで、目的変数となる呼量の過去のデータのことです。例えば3日前の呼量が100あったとして、2日前は30だった。1日前は再度90まで上がった場合、"今日”に当たる日はまた「下がる」と予測できますよね。1日区切りではなく、1週間、1月などの区切りでも考えられます。先ほども例に挙げましたが大型連休がある月は「ほかの月と比べて、呼量が少なくなる」と考えられますが、過去の傾向でも同様の結果が出ているならAIは「5月は呼量が少なくなる(であろう)」と予測してくれます。
下の図を見てください。
2022年7月2日、土曜日の入電数が1166だった場合、翌日の日曜、翌週の土曜も「このぐらいになるだろう」とAIが予測できます。また、平日から休日に変わる金曜と土曜も1日前、前週の同じ曜日の差もAIが学習することで誤差を減らせる可能性が高まります。
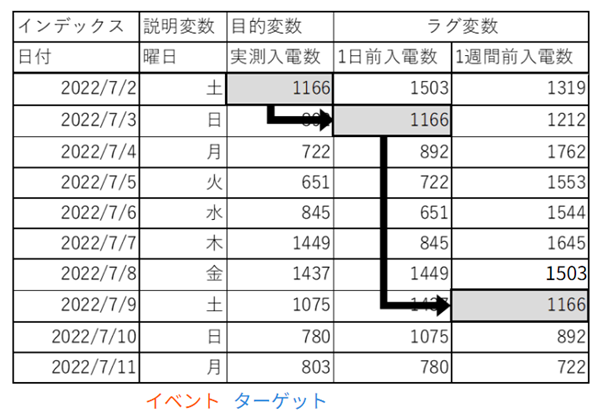
【動画スライド19から引用】*
特徴量データの作成 ラグ変数
*記事の文末に解説動画をご紹介しています。
モデリングについて教えていただけますか?
今回も鍋倉(『金融AI成功パターン』第二章ターゲティングAIパターン解説記事)と同様のAutoML(=Automated Machine Learning)を利用してAIを構築していきます。AutoMLはAIを利用した分析を行う際、こういったラグ変数の作成や数多く存在しているモデリング手法を試すことなどがデータサイエンスの工程を自動化できる技術。このAutoMLにこれまで設定、作成してきたデータソースを投入し、モデリングを行います。
AutoMLはこうした多くのAIモデルで実際にモデリングテストを行い、「もっとも高い精度が出る」と判断したAIモデルを選定、モデリングをしてくれます。時系列問題の場合は、自動的にターゲットに影響する特徴量、ラグ変数等が選定されます。
需要予測はインパクト、効果が実感しやすい
最後に検証について教えていただけますか?
AIの精度検証は、実際に施策を行って検証する実務検証と過去のデータで検証する机上検証があることは鍋倉(『金融AI成功パターン』第二章ターゲティングAIパターン解説記事)も説明しました。
今回の需要予測では、モデルを月次で作成しています。例えば5月の20-25日の間にモデルを作成し2か月後の7月の予測を出力するようにしています。5月に予測作業を行う際は5月のモデル、6月に行う際は6月のモデルを利用して実施しています。
モデルを選定する際の交差検証は、5月の予測モデルを作成する際は、5月の直近の4,3,2月でいくつかのアルゴリズムでの精度を確認、一番精度の良かったアルゴリズムを採用し、実際の予測は5月までのデータを使って予測モデルのトレーニングを行っていきます。そして、予測モデルを利用した実務検証で実際に適応し、実務で活用しているKPI、今回は放棄呼量を確認していきます。
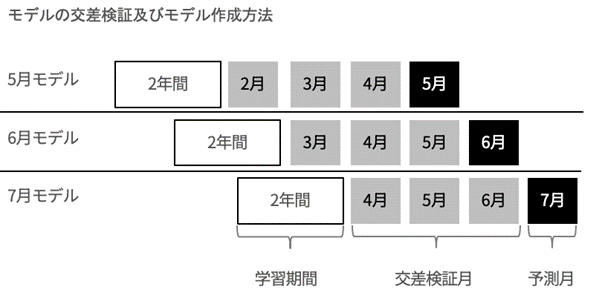
【動画スライド22から引用】*
机上検証
*記事の文末に解説動画をご紹介しています。
今回は需要予測について「呼量予測」を例に挙げて解説していきました。呼量予測は「属人性を排した人員配置」「シフト最適化による放棄呼(=電話が繫がる前に切られてしまう電話)の削減」に期待できます。またそれに伴って作業自動化による工数削減、ナレッジの蓄積など多くのビジネスインパクトがあります。
「学習モデルの監視、精査」について解説しませんでしたが、AIは時間が経つほど精度が低くなっていくことがあります。データや予測精度について定期的なモニタリングが必要になります。AIを活用しよう、取り入れてみよう、しかし構築し稼動することがゴールではありません。AIが上手く機能してからスタートになりますので、ぜひ多くのアイデア、気付きからそれぞれのゴールを見つけ出していって欲しいです。また、気付きや課題感はぜひ共有いただけたら嬉しいです。
金融データ活用推進協会 著
『金融AI成功パターン』
大好評 発売中!

◆金融データ活用推進協会 企画出版 書籍『金融AI成功パターン』”第四章 需要予測パターン”◆
セゾンテクノロジー公式youtubeチャンネルにて、
第四章の執筆を担当したSBIホールディングス株式会社 橋詰創一郎様の解説動画をご紹介しています。
併せてご覧ください。
※2024年4月 セゾン情報システムズは『セゾンテクノロジー』へ社名変更いたしました。
動画中は撮影時の社名を使用しています

