![]()
![]()
 銀行のコアとなる与信業務を定量的に判断、評価できる応用力のあるAI
銀行のコアとなる与信業務を定量的に判断、評価できる応用力のあるAI
〜 審査AI開発のコツ 〜


銀行のみならずあらゆる業界で重要になる「与信」「審査」。長らくベテランの経験と勘が生きる部分だったが、AIの登場によりより高い精度の判断や知見の共有に期待が持てるようになった。
AIの活用、成功パターンを紹介している本連載。第五回となる今回は、メガバンクのひとつであるみずほ銀行のテクノロジー部分を支えるみずほ第一フィナンシャルテクノロジーのエンジニア、山根智之氏に「審査AI」の開発の着眼点やコツについてお話をうかがった。
▼プロフィール
一般社団法人金融データ活用推進協会 企画出版委員会
みずほ第一フィナンシャルテクノロジー株式会社
データアナリティクス技術開発部
シニアフィナンシャルエンジニア
山根智之氏
※役職や所属は取材時のものです。
与信審査にかかる工数の削減を狙える審査AI
最初に山根さんについて自己紹介いただけますか。
理系の大学、大学院にて数理最適化、機械学習を専攻し、2016年に卒業、みずほ銀行に入行しました。入行後は信用リスク管理業務に従事した後、2020年より現職でもあるみずほ第一フィナンシャルテクノロジーに出向しました。主な業務としては、法人個人向けの与信にかかる審査AIの開発、運用フロー構築に携わっています。また、ChatGPTをはじめとした自然言語処理技術を金融分野へ応用する研究開発などを行っています。
みずほ第一フィナンシャルテクノロジーについて教えていただけますか?
みずほ第一フィナンシャルテクノロジーは、1998年に設立されたみずほ銀行、第一生命、損害保険ジャパンの3社を親会社として持つユニークな会社です。「サイエンスとインサイトで未来を照らす」というミッションを掲げ、テクノロジーの進歩に対応してデータサイエンスなどの新たな分野での技術も積極的に取り入れてきました。
設立から金融工学をベースに、数理技術やデータサイエンス分野で専門性を磨いてきました。また、大学院修了者が約7割、うち博士課程修了者も2割弱在籍しているほか、多様なバックグラウンドを持つ20〜30代のメンバーが集まっており、みずほグループ、引いては金融業界の知と技術を結集し、業界を牽引していく活気のある組織だと自負しております。
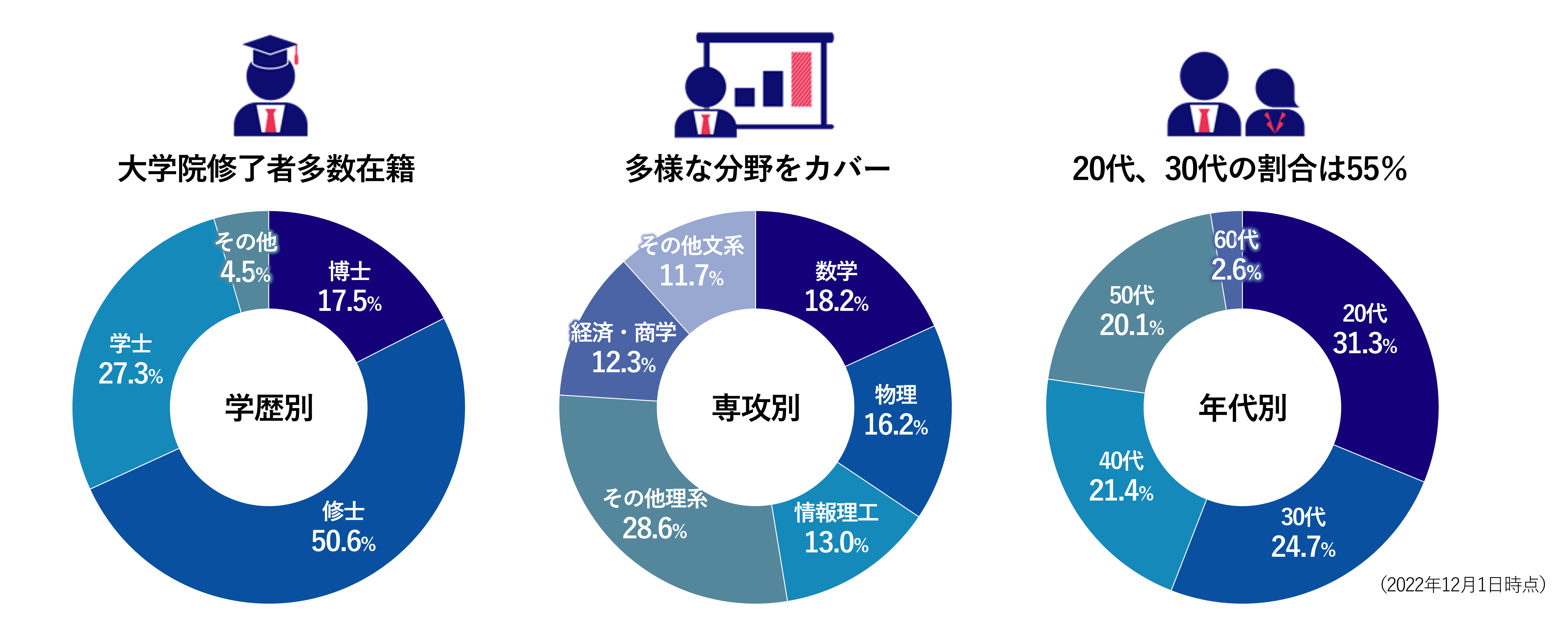
【動画スライド4から引用】*
みずほ第一フィナンシャルテクノロジーの社員について
*記事の文末に解説動画をご紹介しています。
今回は、弊社で開発、運用しております審査AIについてご説明いたします。
審査AIとはどのようなものですか?
まずは、「銀行与信」について説明いたします。銀行与信とはつまり、「お客様から預金を預かり、企業へ貸し出す」ことを言います。企業に融資した際の貸出金利と、お客様からお預かりした預金にお返しする預金金利の差分により銀行は収益を得ております。
貸し出す先を見極め(=審査)、適切な企業へ資金提供をすることは、銀行の利益追求だけでなく、お客様の預金の保全、経済活動活性化の上で重要な行為です。しかし、審査対象先が多くなると、審査ノウハウを持った行員の人手が足りなくなります。そこで、機械学習モデル・AIにより、審査フローの一部または全部を代替する必要性が生まれました。
審査業務をAIによって自動化する「審査AI」には、このような審査業務にかかる工数の削減だけでなく、人間による融資判断の際のサポート、審査ノウハウの共有なども期待出来ます。
審査AIには、どのようなデータが必要になりますか?
AIが判断する材料としては、過去の融資額、月返済額、延滞有無などの「過去融資情報」、預金残高、送金金額などの「口座情報」、口座開設日、資産規模などの「企業の情報」が挙げられます。それらを入力することで、機械学習・統計学の手法により、貸倒れの確率を推定する回帰モデルを構築するアプローチが主流です。
貸倒れの確率について詳しくお話しいただけますか?
貸倒れの確率とは、「貸出先から返済が滞る=デフォルト(債務不履行)」が生じる確率を指します。デフォルト率、またはその英訳(Probability of Default)を略したPDとも呼ばれ、銀行にとって重要な指標です(以下、本文章内ではPDと呼びます)。審査AIは前述した判断材料からこのPDを推定し、融資の諾否判定や金利提示に活用します。
審査AIに入力する判断材料と、その結果を下記の図にまとめました。
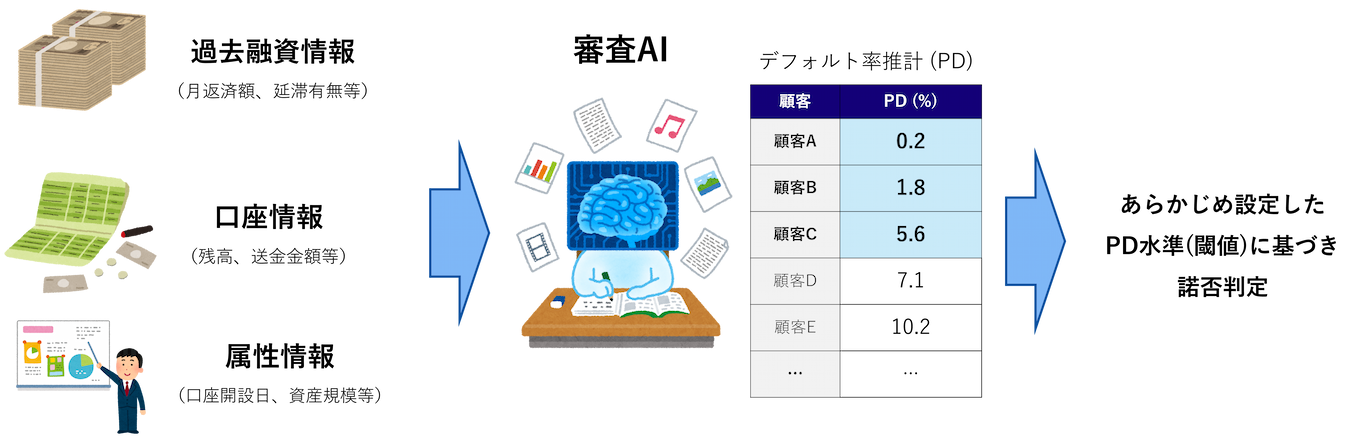
【動画スライド9から引用】*
審査AIに必要なデータと目指す結果
*記事の文末に解説動画をご紹介しています。
上記は、諾否判定のPDしきい値を6%と置いた場合の例です。PDが6%を超える場合は融資を否決し、6%以下の水色の箇所は応諾します。(上図中央)この諾否判定は、これまではベテランの銀行マンが、上図左にある過去融資情報や口座情報などのデータに加え、面談記録などの定性情報も含めて判断していました。審査AIを活用することで、こうしたデータから債務者の信用状態を定量化し、より精度の高い与信判断、効率的な審査運営の実現が期待できます。

入力するデータは大きく3つに分けられる
審査AIのモデルを構築するデータをより詳しくうかがいたいです。
今回のケースでは、大きく「過去融資情報」「口座情報」「属性情報」の3つのデータを想定しています。まず、すべてのデータについて、顧客を特定するためのCIF番号、データの年月を示す基準月、基準日の項目が含まれていることが前提となるため、事前に確認、整型を行ってください。
「過去融資情報」は、延滞履歴、融資履歴に分かれます。

【動画スライド11から引用】*
「過去融資情報」の説明
*記事の文末に解説動画をご紹介しています。
延滞履歴は、各基準月における各顧客の延滞状況についての情報です。これは学習の元となる教師データ、つまりはデフォルトフラグ作成の基になる他、これ自体をPDの推定材料(特徴量)として利用することが多いです。そして、融資履歴は過去に実行された融資の実行金額、実行日、資金使途、現在の貸出残高などの情報が含まれます。

【動画スライド12から引用】*
「口座情報」の説明
*記事の文末に解説動画をご紹介しています。
次に、「口座情報」に関連するデータです。こちらは入出金、口座残高に分かれます。入出金はトランザクションベースの明細のため、月次/年次のサマリー情報として加工します。口座残高は、円貨/外貨、普通/定期などそれぞれの残高情報となります。分析や加工の前に、残高の集計定義は期末時点残高か期中平均残高かを必ず確認しましょう。

【動画スライド13から引用】*
利用データ種類
*記事の文末に解説動画をご紹介しています。
最後に「属性情報」のデータです。先の2つは個人法人ともに発生するデータでしたが、こちらは個人法人それぞれに異なる情報となることが多いです。流動性預金や固定資産、自己資本など、勘定科目は法人特有ですが、個人の場合は住所や投信購入有無などが相当します。
オプショナルなデータとして、代表的なものにオルタナティブデータがあります。これは事業会社との連携などによって得られる情報で、近年特に活用が期待されているデータです。利用する場合、前述のデータ群とCIFによる同一顧客の紐づけができるか、データのカバレッジは十分かなどに注意してください。
データを加工していく流れ
これらのデータをどのように加工していきますか?
データ加工は次のような流れで行います。

【動画スライド15から引用】*
データ加工ステップ
*記事の文末に解説動画をご紹介しています。
最初にモデル構築用サンプルを抽出します。審査AIを開発する際は、審査AIを利用する融資商品も新しく設計することが多いため、その商品による過去融資実績が存在しないことがあります。その場合は銀行の過去取引から、審査AIを利用する融資商品にできるだけ近い取引を選び、モデル構築用サンプルとして抽出する作業を行います。
資金使途、貸出期間、実行金額などを元に抽出していくことが多いですが、関係者間の認識相違による出戻りを防ぐため、商品所管部やリスク所管部と早い段階で会話をしながら抽出の方針を決めていくと良いでしょう。
サンプルデータの取得期間はどのような視点で決めていきますか?
当たり前ですが「どこを利用したいか」から決めていきます。まずは、特徴量の観測期間(残高や入出金などの情報を融資発生の基準日から過去何ヶ月分まで考慮するか)を定義します。特徴量の観測期間は長いほうが多くの情報を取り込めますが、単純平均では直近情報の重要性が薄れてしまいますので、実際のAIの精度を見ながら決定・調整していくことが重要です。
次に、デフォルト観測期間(融資実行後、何ヶ月以内にデフォルト条件を満たせばその貸出をデフォルトと判断するか)を定義します。通常は1年を基準とすることが多いですが、AIを適用する融資が5年などの長期貸出を想定する場合には、合わせて観測期間を延長することもあります。また、デフォルトフラグの付与も行います。各月のデフォルト条件を定義し、定義したデフォルト観測期間内でデフォルト条件を満たすか否かをフラグデータで表現します。デフォルト条件は、行内の定義を参照する他、商品毎の定義があればそれを利用することが多いです。
対象となるサンプルの指定はいかがですか?やはり、債務者を対象にするのでしょうか?
データの量や場合によります。融資の諾否判定を行うので、理想は1債務者を1サンプルとすることですが、データ量が少ない場合は、審査AIの精度が下がる可能性があります。データ量や商品特性によっては、債務者の1貸出を1サンプルとすることもあります。
トランザクションデータに当たる入出金データも状況によって調整が必要です。期間平均・標準偏差、カウントなど様々な加工が考えられますが、AIの精度を見ながら、必要に応じて再加工、調整を検討してください。
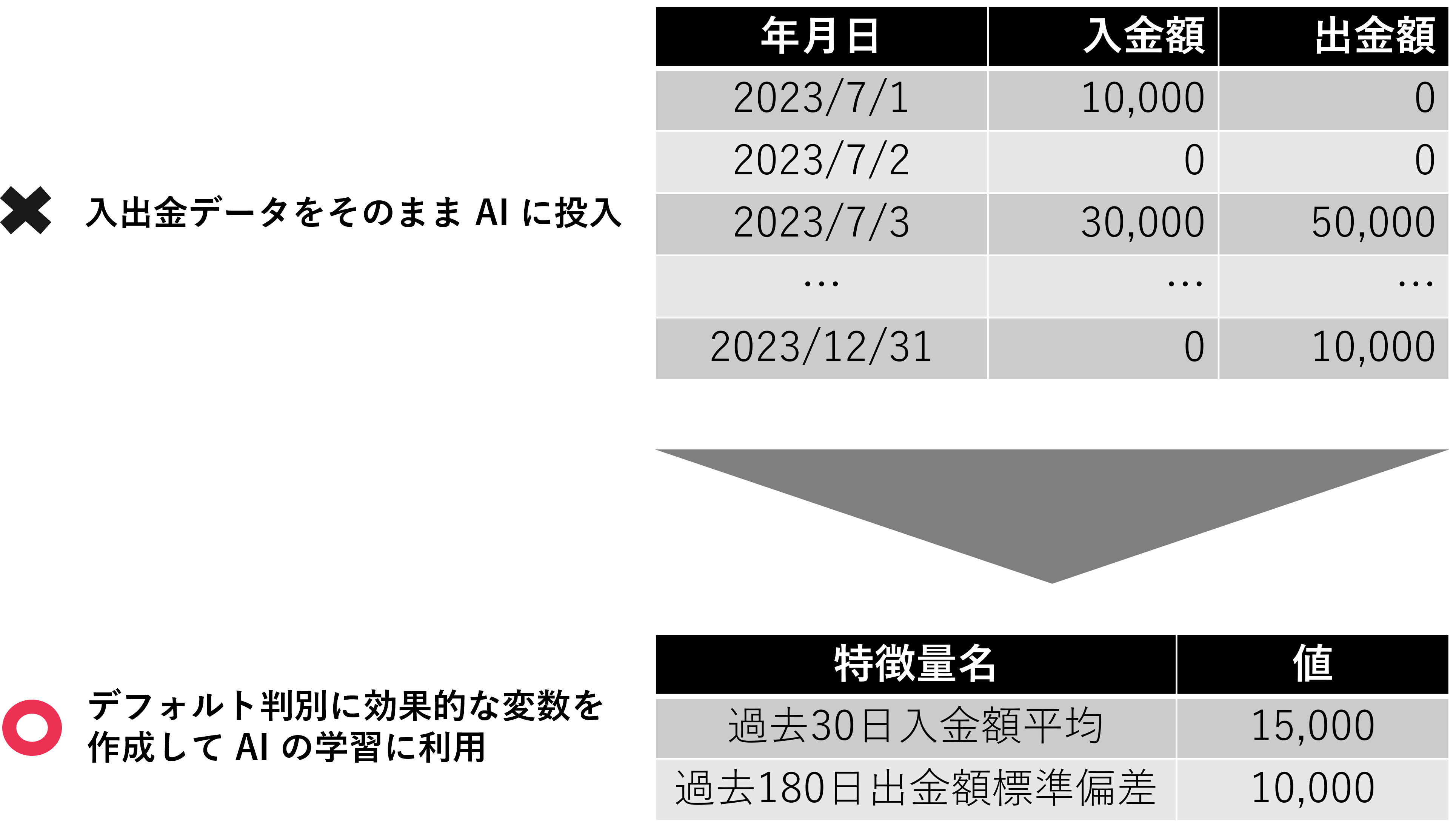
【動画スライド17から引用】*
入出金データ(トランザクションデータ)の基本的な考えかた
*記事の文末に解説動画をご紹介しています。
データの分割について、ランダム分割、時系列分割などを選択します。ランダム分割の場合、層化抽出k-Fold(Stratified k-Fold)などにより、学習データと検証データそれぞれのPD水準が等しくなるようにしてください。また、後述する過学習を防ぐため、学習と検証データそれぞれに同一の債務者、貸出が現れないようにしてください。

【動画スライド18から引用】*
テータの分割方法と注意点
*記事の文末に解説動画をご紹介しています。
最後に、特徴量の加工を行います。多くの場合は、BIツールを用いて、データを様々な角度、軸から分析し、どのような変数がPDに影響するかを探索しながら行います。数字を基にして機械的に行える部分ではありますが、財務変数と信用力の相関関係を分析する際は、適宜ドメイン知識を用いながら結果を解釈していく必要があります。例として、債務償還年数(有利子負債÷営業利益)について考えます。一般的に債務償還年数の値は信用力と負の相関があります(小さいほど信用力が高くなります)が、分母となる営業利益がマイナス(営業赤字)になった時、有利子負債がプラスの場合は債務償還年数もマイナスとなり、営業黒字先の債務償還年数(通常はプラスの値)より小さい値を取ることになるため、結果的に信用力は大きいと解釈されてしまいます。基礎分析の結果からインプリケーションを得る際は、このような財務指標の意味合いを常に考慮しながら実施しましょう。
運用しながら調整をしていくことが肝要
精度の検証について解説いただけますか。
精度検証では、一般的な機械学習モデルの評価でよく利用されるAUCの他、信用リスク管理ではAR値がよく利用されます。AR値は大まかに言えば、「予測PDの高い順にサンプルを並べた際、最初の方にデフォルトサンプルがどの程度集中するか」を評価する値です。このAR値が1に近いほど、AIはデフォルトを正しく検出出来るといえます。
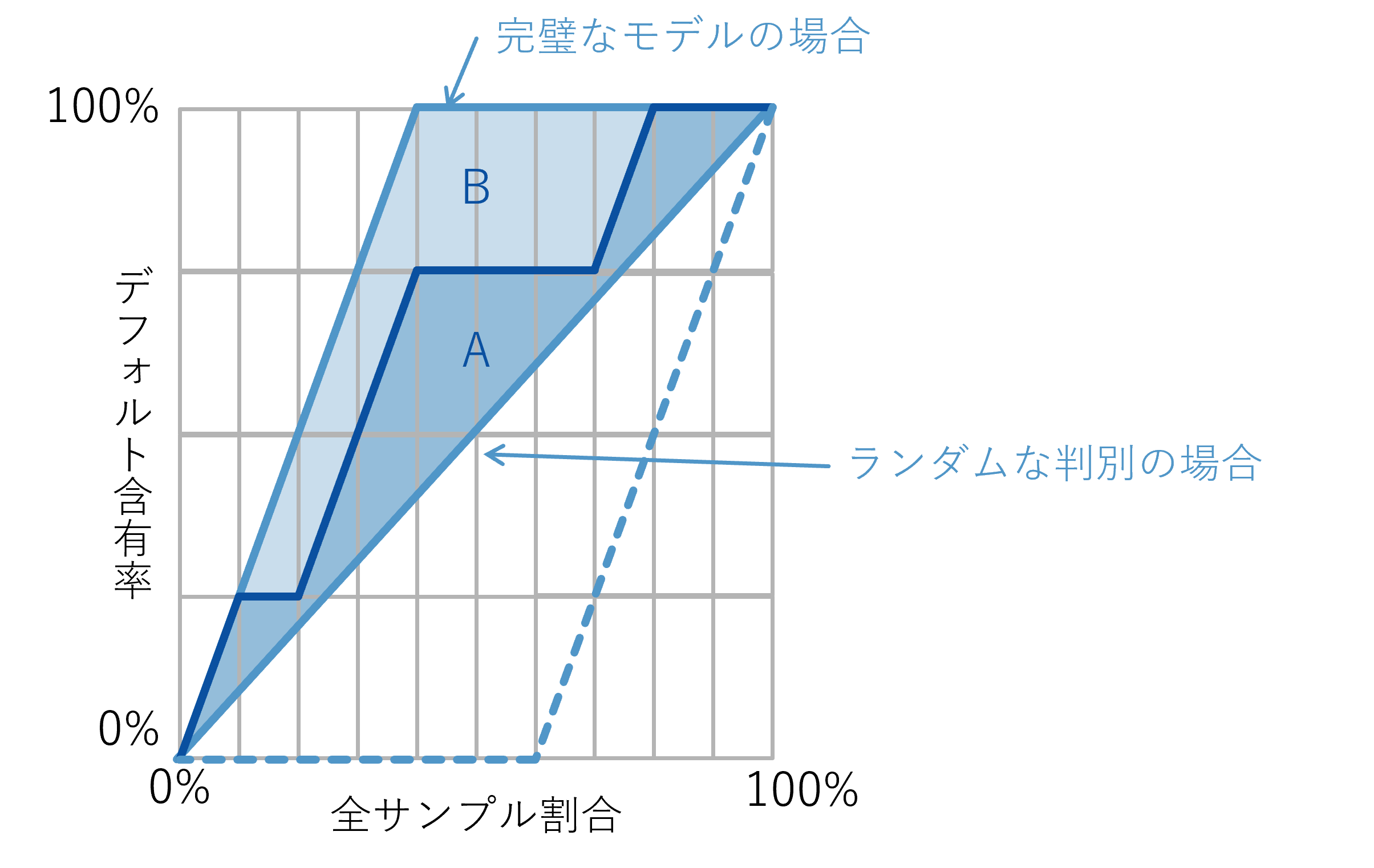
【動画スライド20から引用】*
サンプルをPD降順に並べた場合のデフォルトサンプル含有率
*記事の文末に解説動画をご紹介しています。
1点、AR値は各々のしきい値におけるAIの性能を平均的に評価しておりますが、実際のPD水準はしきい値により左右されるということに注意してください。しきい値は融資商品の許諾率をどの程度に設定したいかというリスク選好により決まる一方、AR値は「許諾先を増やした際にどれだけ効率的に非デフォルト先を取り込めるか」を定量化しています。モデルを構築する際はAR値をできるだけ高めることを目標としつつ、しきい値の水準は「その融資商品でどの程度リスクテイクをしていくか」の目線で、関係各所と共同で設定していくことが重要です。
運用をしていく上での注意点についてお話しいただけますか。
運用に関しての注意点は、「構築、動かして終わりではない」に尽きます。運用時の状況をモニタリングし、特徴量の微調整やモデルの吟味を続けていくことで、精度を維持、向上させることができます。
こうした要調整の部分を見つけ出すためにも、モニタリングは重要です。モニタリングは一般的な機械学習モデルと同様の観点で実施しますが、デフォルト観測期間が長いことや、A/Bテストの実施が難しいことから、審査AIは実績値が集まりづらいことがあります。このような場合、推計PDや特徴量の分布が前月比から変化がないかの確認など、教師無しでのモニタリングを行うことがあります。
審査AIによって得られた予測PDは、最初に挙げたように融資諾否判定や融資条件設定を行う際に利用されます。この予測されたPDに貸出金利のマッピング表を適用することで、機械的に金利を割り当てることなども可能です。
ありがとうございます。最後に審査AIを開発、運用していく上でのtipsなどをお話しいただけますか。
審査AIは、複雑なAIの利用が「精度を高める」とは限りません。審査AIに限らず、「過学習」については注意してください。過学習の例として、受験で合格するために過去問題を解くことを考えます。問題の傾向を摑むため、複数の過去問題を解くことは有効ですが、一字一句、答えまで丸暗記してしまっては、未知の問題への適応力はかえって低下してしまいます。このような、「過去の結果に適応しすぎて、むしろ未知の問題への適応力を失ってしまう状況」を、機械学習の世界では「過学習」と呼びます。「事前の精度が高い」ことで検証を終わりにせず、実運用での検証結果のフィードバックなどを行い、継続的な精度検証・モデル選択を行ってください。
最後に、審査AI開発プロジェクト運営についても2点コメントいたします。まず1つ目、今回照会した審査AIの開発には、融資商品所管部、リスク所管部、コンプライアンス所管部などのステークホルダーが複数存在しています。各々の観点がAI開発の要件に影響する可能性がありますので、ステークホルダーへの進捗報告は細かく行い、出戻りのリスクを減らしていくことが重要です。
2つ目、審査AI開発においては、データの収集や加工作業が作業の大部分を占めております。このような基礎的なデータ処理が、全体工数の7割にまで達する例も往々にしてあり、開発するAIの精度がプロジェクトの終盤まで見積もれないこともあります。そのため、集計や加工のような基礎作業を十分に行えるよう、スケジュールは余裕を持って組むこと、高度な特徴量加工は優先順位を下げ、モデルのプロトタイプを先に構築して、精度の見積算出を早めることなどが必要です。
金融データ活用推進協会 著『金融AI成功パターン』
大好評 発売中!

「FDUA 金融データ活用推進協会タイアップ企画」動画
◆金融データ活用推進協会 企画出版 書籍『金融AI成功パターン』”第6章 審査AIパターン◆
セゾンテクノロジー公式youtubeチャンネルにて、第六章の執筆を担当したみずほ第一フィナンシャルテクノロジー株式会社 山根智之様の解説動画をご紹介しています。
併せてご覧ください。


