![]()
![]()
 数値では摑めない気付きをテキスト、定性情報から摑む!
数値では摑めない気付きをテキスト、定性情報から摑む!
〜 テキスト分類AIの特徴 〜


AIの活用範囲は広く、あらゆるビジネス、サービスで利用されている。昨今、テキスト生成をするAIが一般も含めて注目を集めているが、数字と異なり、テキストの判別、判断、そして自動で生成をすることはAIには難しい作業に当たる。
AIの活用、成功パターンを紹介している本連載。第四回となる今回は、外資系ITベンダーでデータの分析、活用及び、機械学習の導入に至るまでデータ利活用の研究、支援を行ってきた三井住友信託銀行の鈴木みゆき氏にテキストにおけるAI成功事例についてお話をうかがった。
▼プロフィール
一般社団法人金融データ活用推進協会 企画出版委員会
三井住友信託銀行 デジタル企画部 兼
Trust Base株式会社 データサイエンスセンター
鈴木みゆき氏
※役職や所属は取材時のものです。
金融業界が持つ制約に対し、子会社で新技術を積極的に導入、ノウハウを蓄積
まずは鈴木さんの自己紹介をいただけますか。
前職、前々職と外資系ITベンダーにて、データやAIのコンサルタントとして活動してきました。企業に対して、データの連携や蓄積、そして機械学習の提案、導入業務など、データ活用を長らく支援してきました。2年前に三井住友信託銀行及びTrust Baseに入社し、三井住友トラストグループの業務ユーザーとともに先行事例を通じてデータ利活用の設計、導入、いわゆるDX化を主導しています。
三井住友信託銀行はどのような業務を行っていますか?
信託銀行は、みなさんがイメージする預金、貸し出し、為替業務などの銀行業務のほか、企業年金や確定拠出年金、証券代行(株式会社の株主管理業務、株主総会の業務)などの業務があります。そのほか、相続関連の業務を行っています。特に三井住友信託銀行は不動産など資産運用、管理の業務など、個人法人問わず“資産”に関する業務を幅広く手掛けているなど、対応できる範囲が広いことから「総合力」で評価いただいています。
鈴木さんが兼務しているTrust Baseはどのような会社ですか?
Trust Baseは三井住友信託銀行も含む三井住友トラストグループのDXを推進、牽引している会社です。銀行というビジネスでは、信用や信頼が重要となるため、他業種と比べて規約や規制が数多く存在します。そのため、システム開発の自由度、分析手法など先進的な技術を試す機会にも制約がかかりやすいです。例えば、ChatGPTなど世の中が注目している技術、サービスはまずTrust Baseで導入。銀行業務に取り入れるためのノウハウを蓄積するなど、グループ内の情報戦略子会社としての役割をになっています。
今回は、銀行業務とは切り離せない書類群、文書のAI処理について解説いたします。
定性情報だからこその強みと弱み、数字を絡めるなど応用も可能
金融業界も脱印鑑など、ペーパーレス化が進んでいると聞いていますが、実際はどうなのでしょうか?
文書の電子化は進んではいますが、やはり契約業務が多いこともありまだまだ文書、テキスト文化は根強いです。ただし、テキスト自体の電子化は進んでおり、契約書などの定型テキストはもちろん、顧客アンケートなどの非定型テキストもOCR技術を利用して電子化されています。こうして電子化されたデータをこれまで通り、従業員が目を通しているままでは業務効率化、属人性の排除ができないため、AIに期待が寄せられています。
下図は金融業界において、発生する主なテキストデータです。

【動画スライド7から引用】*
テキスト分類AIの利用領域(金融業界)
*記事の文末に解説動画をご紹介しています。
フリーテキストを分析する際、「統一」と「解釈」の2つの方向性があります。「統一」は第3章、堀江さん(解説記事リンク)が語った「住所の表記」のように文字の揺らぎをなくす方向で進めます。例えば「Trust Base」と「トラストベース」は、人が見れば同じ会社名を指していることがわかりますが、AIにかけた場合は別の会社名と認識される可能性があります。ですので「Trust Base」で統一します。「解釈」では、自然言語処理技術を利用し、要約、タグ付けなどを行うことで属人的であるフリーテキストの解釈を標準化します。
次の表はフリーテキストをAIでテキスト分類する際に、主に利用される4パターンを表しています。表を見てわかるように、データソースが単一か複数か、分析をする前に目的を定めるのか定めないのかで分析の種類が変わります。
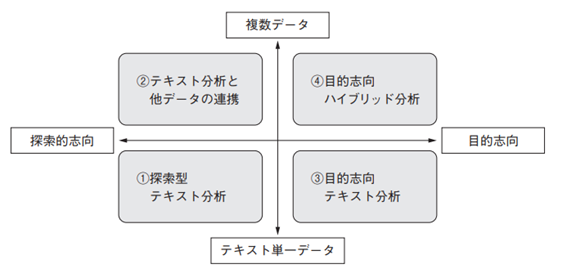
【動画スライド8-11(書籍P176、図表7-1)から引用】*
テキスト分類AIの4パターン
*記事の文末に解説動画をご紹介しています。
テキスト分類AIを利用する際、まず「何のためにテキスト分類AIを利用するのか?」を考えます。例えば、顧客アンケートなど、人が1つ1つ目を通して「ここに興味を持っている」など抽出する業務を自動化したい場合は、探索型テキスト分析で考えていきます。この場合、主な目的は業務効率化と属人的判断の排除になります。
テキストは善くも悪くも「曖昧さ」があります。数字だけでは把握できない気付きを得やすいものの、「顧客は確実にこれを求めている!」とはテキストデータだけでは言い切れない面もあります。上記の表で「複数データ」側にある、テキスト分析と他データの連携や目的思考ハイブリッド分析は、テキストと顧客データや数字を組み合わせてより目的や気付きを明確にすることができます。
テキスト分類の場合、データソースに特徴はありますか?
数字の場合と異なり、テキスト分類では「誰が書いたものか」「誰起点であるか」が重要になります。銀行業務で発生するフリーテキストでは顧客が直接記載するアンケートなどの「顧客起点フリーテキスト」、コンタクトセンターなど顧客との接点で発生する「顧客起点音声デジタル化」、顧客と対面した行員、担当者が記載する「銀行員起点フリーテキスト」があります。
顧客起点のフリーテキスト、音声デジタル化データはCS向上の観点でとても重要なデータソースになります。
銀行員起点フリーテキストはどのようなケースに役立ちますか?
銀行員起点は日誌や提案書などが該当します。これらは銀行員、営業マン視点で書かれていることから、顧客の考えが抽出できるとは言い切れません。ただし、ライフステージの変化、顧客が何に興味を持っていたか、関心を寄せていたかなど、“専門家”たちがヒアリングした情報から拾うことができます。
あともう一点、テキスト分類ならではのポイントですが、法人か個人かで変化する言いまわしへの配慮も必要です。アンケートで言えば、個人顧客は「サービスが悪い」と明確に書かれることが多いですが、法人顧客の場合は取引先という認識もあるためか「サポートは良いが、サービス面はもう少し配慮して欲しい」と間接的な言いまわしで記載されることが増えます。このような差を認識しながら、テキスト分類を行っていきます。

テキスト分類では「誰の視点のデータなのか?」が重要
データソースはどのように加工していきますか?
まず「CS向上に関する分析」を行う場合は、前述したデータソースで言えば「顧客起点フリーテキスト」、顧客が書いたアンケートのデータを基にして感情分析を実施します。
CS向上を目的に、苦情の予知、分析を行うこともあります。その場合、コンタクトセンターのオペレーターが記載した「コンタクト履歴」をデータソースにする場合もありますが、オペレーターが記載したテキストに感情分析を行うとオペレーターの感情を抽出してしまうこともあるため、予め目的を設定する「目的志向テキスト分析」など、工夫が必要です。
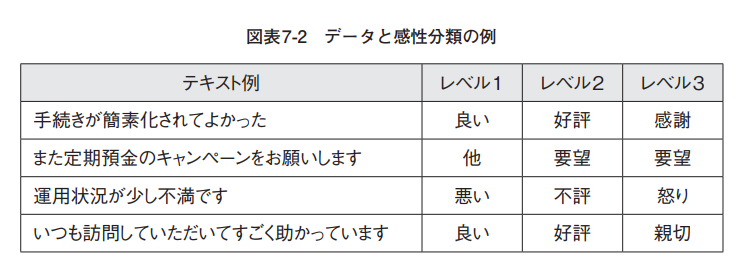
【動画スライド18から引用】*
データと感性分類の例
*記事の文末に解説動画をご紹介しています。
当社が採用している感情分析では、感情のレベルが3段階で出力されます。レベル1では「良い」コメントか「悪い」コメントなのか。レベル3では81種類の感情に細かく分類されます。この際、感情分析に不要となる「いつもありがとうございます」「お世話になります」などの挨拶文は、除外されるよう設定しています。
銀行員起点フリーテキストをデータソースにする場合はいかがですか?
先ほど挙げたコンタクト履歴を利用して、「営業機会の創出分析」を行うことも可能です。この場合、頻出単語の推移や二値分類を用いて分析していきます。営業機会、つまりは顧客のライフステージの変化や関心事の抽出から、効果的な提案に繋げていきます。また、単純にAIによる分析を行うだけではなく、営業推進を行っている業務ユーザーとともに分析結果を検討するなど、連携を行っていくことも重要です。
分析結果は「業務ユーザーがすでに知っている、わかっているか?」に着目する
検証について教えていただけますか?
テキスト分類は特に既知の情報の取り扱いが重要です。既知の情報、つまりは分析結果を営業担当に還元したとき、「これはすでに知っている」「これはわかっています」と思われてしまうこと。「AIを使ってもこの程度なのか」と価値を理解してもらえなくなってしまいます。
そのため、既知か目新しい情報かを切りわけることを重視します。机上検証では、精度を向上するため、既知と推測できる結果も含みますが、実務検証では既知の情報は除外して、営業担当など業務ユーザーに展開し、フィードバックをもらい調整を図っていきます。
テキスト分類は定性情報を分析するためか、他のAI成功パターンとは違った視点、アプローチになる印象です。
そうかもしれません。もう一点、テキスト分類ならでは、「運用」についても注意していただきたいです。CS向上に関する分析では、「人の目で見落としていた苦情をAIによってどれだけ拾えたか」「認識していなかったが、対応が必要だった苦情をどれだけ拾えたか」によって、精度が高くなったと判断することができます。
営業機会の創出分析では、営業担当が顧客へ提案する機会、クロスセルやアップセルの増加により精度が高くなったと判断できます。双方とも、定性情報の分析だからこそ、精度を高めるためにどのような指標を設けるべきか、どうPDCAサイクルを回すかを検討していくと良いでしょう。
金融データ活用推進協会 著
『金融AI成功パターン』
大好評 発売中!

◆金融データ活用推進協会 企画出版 書籍『金融AI成功パターン』”第七章 テキスト分類AI(自然言語処理)パターン”◆
セゾンテクノロジー公式youtubeチャンネルにて、
第七章の執筆を担当した三井住友信託銀行 鈴木みゆき様の解説動画をご紹介しています。
併せてご覧ください。
※2024年4月 セゾン情報システムズは『セゾンテクノロジー』へ社名変更いたしました。
動画中は撮影時の社名を使用しています

