MATCH_REG関数
関数
MATCH_REG{PATTERN, MATCH_STRING,NOMATCH_STRING}
マッピングされた文字列がPATTERNに指定した条件に合致する場合、文字列をMATCH_STRINGに指定した値に変換します。合致しなかった場合は、文字列をNOMATCH_STRINGに指定した値に変換します。この関数を使用することで、値の妥当性を判定できます。
引数には正規表現を使用できます。正規表現で使用できる代表的なメタ文字については、「表A.11 REPLACE_REG関数で使用可能な正規表現」を参照してください。ただし、MATCH_REG関数では後方参照は行えません。
-
入力データのコード種がEBCDIC系またはJISの場合は、UTF-8に変換して置換を行うため、外字は使用できません。
一旦UTF-8に置換する動作は、PATTERN(検索する文字列)に合致しない場合やPATTERN(検索する文字列)に16進表記を使用した場合も同様です。また、機種依存文字を含む場合、動作を保証しません。
-
入力データのコード種の違いにおける動作仕様については、「入力データのコード種の違いにおける動作仕様」を参照してください。
パラメータ
PATTERN
一致条件を指定します(省略不可)。
MATCH_STRING
マッピングされた文字列がPATTERNに指定した条件に合致した場合に変換する文字列を指定します(省略不可)。
NOMATCH_STRING
マッピングされた文字列がPATTERNに指定した条件に合致しなかった場合に変換する文字列を指定します(省略不可)。
使用例
「あ」が含まれている文字列は「○」に、含まれていない文字列は「×」に変換します。
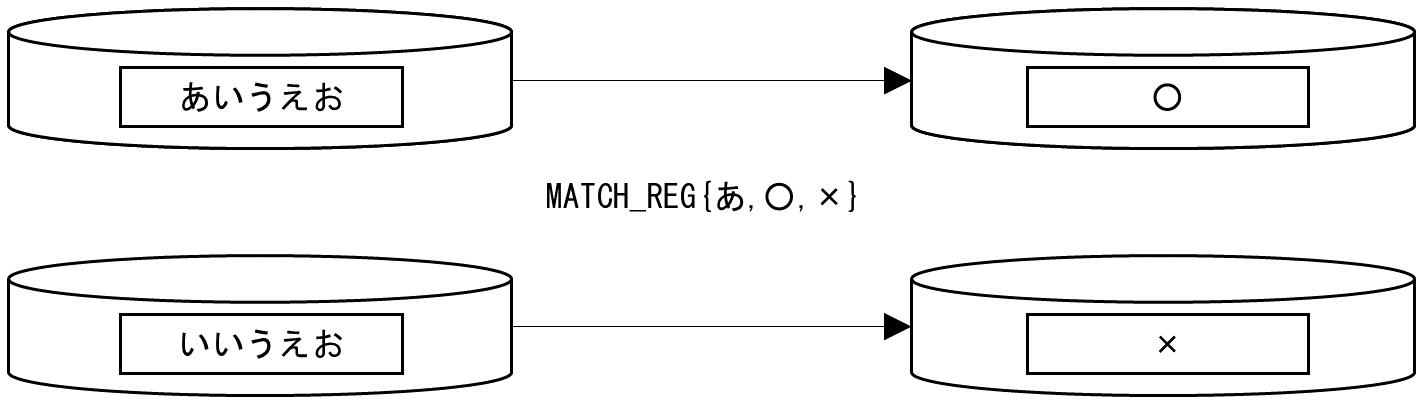
図A.21 使用例(MATCH_REG関数)
引数に正規表現を使用した場合の使用例については、「MATCH_REGの使用例」を参照してください。
入力データのコード種がEBCDIC系またはJISの場合
下記のケースを例に説明します。下記のデータはすべて16進数表現です。
|
入力設定の漢字コード種 |
JEF |
|
入力設定のEBCDICセット |
EBCDICカナ |
|
出力設定の漢字コード種 |
JEF |
|
出力設定のEBCDICセット |
EBCDICカナ |
|
入力データ |
40 20 40 9C 01 20 10 9C |
|
入力データの項目タイプ |
X(キャラクタ) |
|
関数 |
MATCH_REG{\x20\x10\x20,ABC,UNMATCH} |
1) 入力文字列はMATCH_REG実施前に、UTF-8に変換されます。

図A.22 UTF-8に変換
「0x40(スペース)」および「0x9C(UTF-8に変換出来ないコード)」が「0x20」に変換されます。
2) UTF-8で変換されたデータに対してMATCH_REGを実施します。

図A.23 MATCH_REGを実施
「20 10 20」に合致するので「41 42 43(UTF-8の文字列”ABC”)」に変換されます。
3) MATCH_REGの結果データを出力設定にしたがってJEF/EBCDICセットに変換します。

図A.24 出力設定にしたがってJEF/EBCDICセットに変換
「41 42 43(UTF-8の文字列”ABC”)」が「C1 C2 C3(EBCDICの文字列”ABC”)」に変換されます。
入力データのコード種がSHIFT-JIS、EUC、UTF-16、UTF-8の場合
下記のケースを例に説明します。下記のデータはすべて16進数表現です。
|
入力設定の漢字コード種 |
EUC |
|
出力設定の漢字コード種 |
SHIFT-JIS |
|
入力データ |
40 20 40 9C 01 20 10 9C |
|
入力データの項目タイプ |
M(可変長文字) |
|
関数 |
MATCH_REG{\x20\x10\x9C,あいう,UNMATCH} |
1) 入力データに対してMATCH_REGを実施します。

図A.25 MATCH_REGを実施
「20 10 9C」に合致するので「E3 81 82 E3 81 84 E3 81 86(UTF-8の文字列”あいう”)」に変換されます。
2) MATCH_REGで変換したUTF-8のデータを出力設定にしたがってSHIFT-JISに変換します。

図A.26 出力設定にしたがってSHIFT-JISに変換
「E3 81 82 E3 81 84 E3 81 86(UTF-8の文字列”あいう”)」が「82 A0 82 A2 82 A4(SHIFT-JISの文字列”あいう”)」に変換されます。