REPLACE_REG関数
関数
REPLACE_REG{PATTERN,REPLACEMENT}
関数の処理対象となるデータ内に引数PATTERNで指定した値があった場合、引数PATTERNで指定した文字列を引数REPLACEMENTで指定した文字列に置換して値を返します。引数には正規表現を使用できます。また、引数PATTERNと引数REPLACEMENTに配列を使用も可能ですが、両者の配列の数が異なる場合は実行時にエラーとなります。
-
入力データのコード種がEBCDIC系またはJISの場合は、UTF-8に変換して置換を行うため、外字は使用できません。
一旦UTF-8に置換する動作は、PATTERN(検索する文字列)に合致しない場合やPATTERN(検索する文字列)に16進表記を使用した場合も同様です。また、機種依存文字を含む場合、動作を保証しません。
-
入力データのコード種が "SHIFT-JIS"、"EUC"、"UTF-16"、"UTF-8"のいずれかで、出力データのコード種がEBCDIC系またはJISの場合、動作を保証しません。このケースについてはSAISON_REPLACE_HEXをご利用ください。
-
入力データのコード種の違いにおける動作仕様については、「入力データのコード種の違いにおける動作仕様」を参照してください。
パラメータ
PATTERN
検索する文字列を指定します(省略不可)。
REPLACEMENT
置換する文字列を指定します(省略不可)。
16進数での文字列の指定はできません。
REPLACE_REG関数は、正規表現を用いてパターンマッチした文字列の置換を行います。
正規表現とは文字列のパターンを表現するための方式です。たとえば、"ABCD"、"Abcd"、"AAAA"、"AXYZ"の4つの文字列があった場合、すべて「最初の文字が"A"で始まる4文字の文字列」というパターンに当てはまります。これを正規表現を用いて表現すると「^A...」と記述できます。
正規表現で使用できる代表的なメタ文字は以下のとおりです。メタ文字とは正規表現の中で特別な意味をもつ文字のことです。
|
要素 |
表記 |
内容 |
使用例 |
|
|---|---|---|---|---|
|
基本要素 |
\退避修飾 |
正規表現記号の有効および無効の制御 |
\\ |
"\"にマッチする。 |
|
| |
選択肢 |
a|b |
"a"または"b"とマッチする。 |
|
|
(…) |
式集合(グループ) |
(abc)+ |
"abcabcabc"などにマッチする。 |
|
|
[文字集合] |
文字クラス |
[TN]ext |
"Text"や"Next"にマッチする。 |
|
|
文字 |
\t |
タブ |
a\tb |
"aタブb"にマッチする。 |
|
\n |
改行 |
abc\n |
"abc改行"にマッチする。 |
|
|
\r |
復帰 |
abc\r |
"abc改行"にマッチする。 |
|
|
\xnn |
16進表記での文字指定 nn:16進表記 |
a\x20b |
"a半角スペースb"にマッチする。 |
|
|
文字種 |
. |
任意 |
a...b |
"a"で始まって"b"で終わる長さ5バイトの任意の文字列にマッチする。 |
|
\w |
単語構成文字 |
a\wb |
"a_b"や"a1b"などにマッチする。 [a-zA-Z_0-9] と同様。" |
|
|
\s |
空白文字 |
a\sb |
"a改行b"や"aタブb"などにマッチする。 |
|
|
\S |
非空白文字 |
a\Sb |
"acb"や"adb"などにマッチする。 |
|
|
\d |
10進文字 |
\d\d |
"12"や"34"などの"0"~"9"を使用した2桁の文字にマッチする。 |
|
|
\D |
非10進文字 |
\D\D |
"AB"や"XX"などの"0"~"9"以外を使用した2桁の文字にマッチする。 |
|
|
\h |
16進文字 |
\h\h |
"1A"や"B9"などの"0"~"9"、"A"~"F"を使用した2桁の文字にマッチする。 |
|
|
\H |
非16進文字 |
\H\H |
"GH"や"XX"などの"0"~"9"、"A"~"F"以外を使用した2桁の文字にマッチする。 |
|
|
量指定子 |
? |
1回または0回 |
abc? |
"ab"または"abc"にマッチする。 |
|
* |
0回以上 |
abc* |
"ab"、"abc"、"abccc"、"zab"、"zabc"などにマッチする。 |
|
|
+ |
1回以上 |
abc+ |
"abc"や"abccc"などにマッチするが"ab"にはマッチしない。 |
|
|
{n,m} |
n,m:数字 n回以上m回以下 |
abc{2,3} |
"abcc"や"abccc"にマッチする。 |
|
|
{n,} |
n:数字 n回以上 |
abc{2,} |
"abcc"、"abccc"、"abcccccc"にマッチする。 |
|
|
{,n} |
n:数字 0回以上n回以下 |
abc{,2} |
"ab"、"abc"、"abcc"にマッチする。 |
|
|
{n} |
n:数字 n回 |
abc{2} |
"abcc"にマッチする。 |
|
|
錨 |
^ |
行頭 |
^a |
"a"で始まる文字列にマッチする。 |
|
$ |
行末 |
a$ |
"a"で終わる文字列にマッチする。 |
|
|
\b |
単語境界 |
\babc\b |
"abc"にはマッチするが"abcd"にはマッチしない。 |
|
|
文字集合 |
^… |
否定 |
[^a] |
"a"以外の文字にマッチする。 |
|
x-y |
範囲 |
[a-z] |
英小文字にマッチする。 |
|
|
後方参照 |
\n |
置換文字列で使用 n:数字 |
a(.*?)b |
\1にて"a"と"b"の間にある任意の文字列を参照する。 |
|
$n |
a(.*?)b |
$1にて"a"と"b"の間にある任意の文字列を参照する。 |
||
-
関数の予約記号を引数として使用する場合の注意点
関数の予約記号「,(カンマ)」「{(始めの中かっこ)」「}(終わりの中かっこ)」「/(スラッシュ)」を引数として使用する場合は、「\(円)」でエスケープしてください。
ただし、以下に示す場合には、「,(カンマ)」「{(始めの中かっこ)」「}(終わりの中かっこ)」を使用するときでもエスケープしないでください。エスケープすると、データ加工が正常に実行されません(なお、「/(スラッシュ)」にはエスケープが必要です)。
-
引数に「$DSTRXX」を指定して、値を動的文字列で指定する場合
-
-
「\s」で改行コードを置き換えする場合の注意点
入力データがCSVの場合には、「改行を項目の一部として扱う」を有効にし、囲み文字を使用してください。
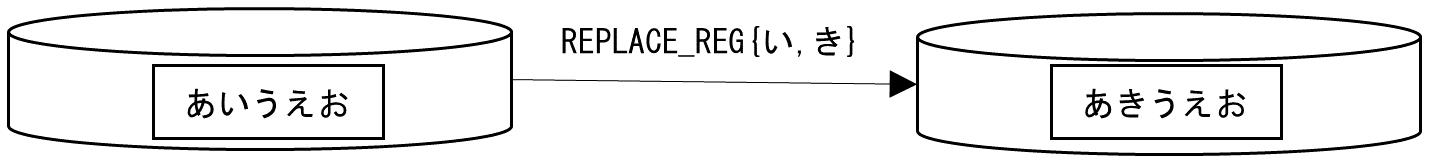
入力データのコード種がEBCDIC系またはJISの場合
下記のケースを例に説明します。下記のデータはすべて16進数表現です。
|
入力設定の漢字コード種 |
JEF |
|
入力設定のEBCDICセット |
EBCDICカナ |
|
出力設定の漢字コード種 |
JEF |
|
出力設定のEBCDICセット |
EBCDICカナ |
|
入力データ |
40 20 40 9C 01 20 10 9C |
|
入力データの項目タイプ |
X(キャラクタ) |
|
関数 |
REPLACE_REG{\x20\x10\x20,ABC} |
1) 入力文字列はREPLACE_REG実施前に、UTF-8に変換されます。

図A.29 UTF-8に変換
「0x40(スペース)」および「0x9C(UTF-8に変換出来ないコード)」が「0x20」に変換されます。
2) UTF-8で変換されたデータに対してREPLACE_REGを実施します。

図A.30 REPLACE_REGを実施
「20 10 20」が「41 42 43(UTF-8の文字列”ABC”)」に変換されます。
3) REPLACE_REGの対象データすべてを出力設定にしたがってJEF/EBCDICセットに変換します。

図A.31 出力設定にしたがってJEF/EBCDICセットに変換
「41 42 43(UTF-8の文字列”ABC”)」が「C1 C2 C3(EBCDICの文字列”ABC”)」に変換されます。
入力データの0x20はUTF-8ではスペースとなるため、3)のEBCDIC変換時に0x40に変換されます。
0x9Cのように、UTF-8に変換出来ないデータはREPLACE_REGで変換する前の値を保持出来ません。
入力データのコード種がEBCDIC系またはJISの場合に、変換前の値を保持して変換処理を実施したい場合は共通コンポーネントSAISON_REPLACE_HEXをご利用ください。
入力データのコード種がSHIFT-JIS、EUC、UTF-16、UTF-8の場合
下記のケースを例に説明します。下記のデータはすべて16進数表現です。
|
入力設定の漢字コード種 |
EUC |
|
出力設定の漢字コード種 |
SHIFT-JIS |
|
入力データ |
40 20 40 9C 01 20 10 9C |
|
入力データの項目タイプ |
M(可変長文字) |
|
関数 |
REPLACE_REG{\x20\x10\x9C,あいう} |
1) 入力データに対してREPLACE_REGを実施します。
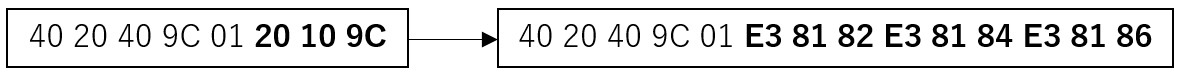
図A.32 REPLACE_REGを実施
「20 10 9C」が「E3 81 82 E3 81 84 E3 81 86(UTF-8の文字列”あいう”)」に変換されます。置き換え文字以外については変換対象外となります。
2) REPLACE_REGで変換したUTF-8のデータを出力設定にしたがってSHIFT-JISに変換します。

図A.33 出力設定にしたがってSHIFT-JISに変換
「E3 81 82 E3 81 84 E3 81 86(UTF-8の文字列”あいう”)」が「82 A0 82 A2 82 A4(SHIFT-JISの文字列”あいう”)」に変換されます。
置き換え文字以外は出力設定の漢字コード種の設定にしたがって変換されます。