Explore HULFT Square
HULFT Square is a platform to collaborate with various systems and services, and integrates data that is stored on them securely and easily.
HULFT Square also enables you to not only replace your old on-premises infrastructure with cloud infrastructure, but also centralize the data integration processes distributed on multiple on-premises and cloud environments. Centralization simplifies data management and data integration operations, and facilitates the utilization and visualization of data to gain business insight.
Collaboration
HULFT Square can collaborate with a wide range of systems and services as well as the existing core systems that reside on-premise and in the cloud environments.
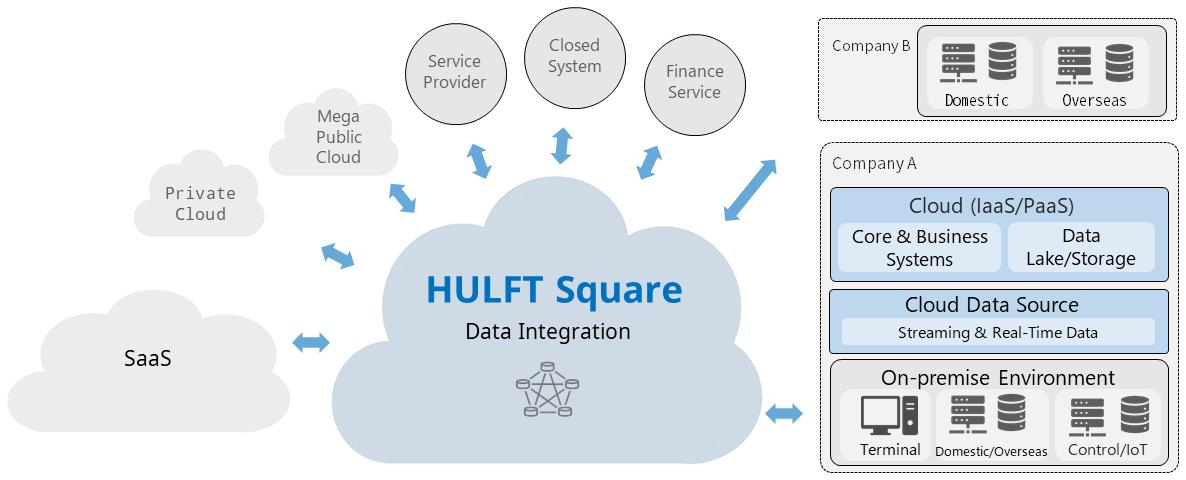
Figure 1.1 Collaboration overview
With the collaboration features, HULFT Square can help to satisfy the following requirements:
-
Analyze customer needs with internal customer data to improve sales.
-
Use Google BigQuery to quickly obtain insight for business strategy.
-
Accumulate data on the cloud without modifying in-house systems or developing an original system on the cloud.
HULFT Square enables you to collect data on the cloud storage without modifying existing on-premise systems. Collaboration with Google BigQuery can also be implemented without creating any additional systems.
Centralization
HULFT Square stores and manages all the data on the cloud.
For example, the management data related to the elements shown in the following figure is stored in HULFT Square:
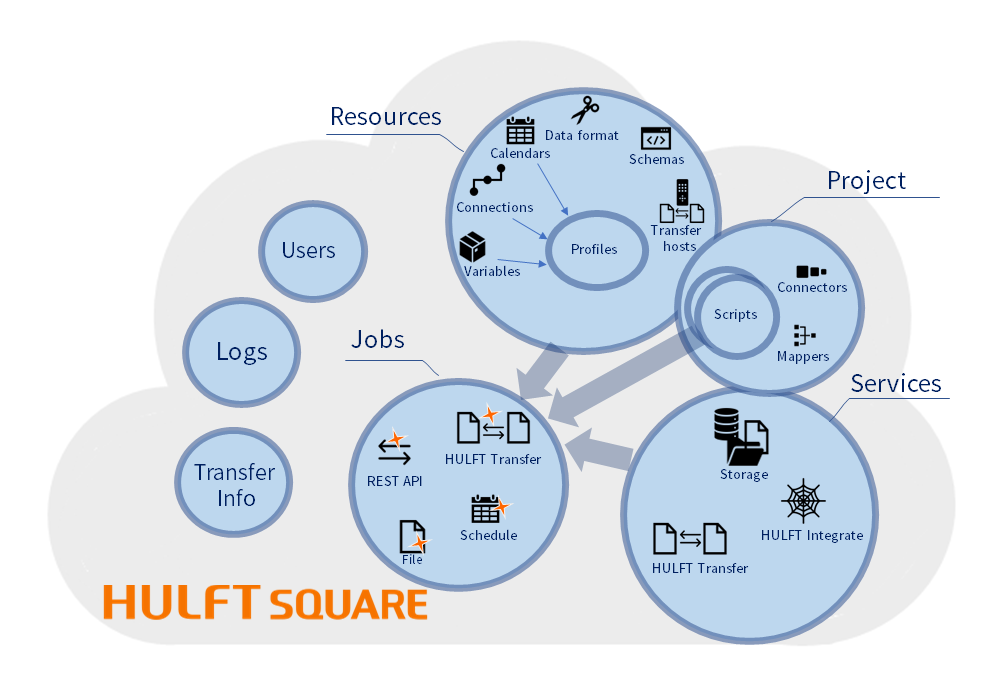
Figure 1.2 Centralization overview
Connection
When HULFT Square and other systems and services are connected, you need to define how the data is integrated.
In HULFT Square, various elements are used to define the data integration between HULFT Square and the target systems and services.
Among them, connectors are important elements used to create integration flows.
The following categories and types of connectors are provided by HULFT Square:
-
Database
DB2, MySQL, Oracle, PostgreSQL, SQL Server, JDBC, Snowflake
-
File
CSV, Excel, Excel(POI), XML, Fixed-Length, Variable-Length, File Operation, Filesystem
-
Application
Dynamics 365 for Customer Engagement, Salesforce (deprecated), SAP OData
-
Network
FTP, REST, Mail
-
Cloud
Amazon Athena, Amazon Aurora (for MySQL, PostgreSQL), Amazon DynamoDB, Amazon EC2, Amazon RDS (for My SQL, Oracle, PostgreSQL, SQL Server), Amazon RedShift, Amazon S3, Amazon SQS, AWS Lambda, Azure SQL Database, Azure BLOB Storage, Azure Cosmos DB, Azure HDInsight, Azure Queue Storage, Gmail, Google BigQuery, Google Cloud Storage, Google Drive, Google Sheets, Kintone, BOX, Slack, Salesforce, SharePoint
-
Cryptography
PGP
-
HULFT
Request Issuance
You can use these connectors when creating scripts to define integration flows.
For the basic tasks and flow to perform data integration, refer to Basic tasks.
For the concepts you need to understand when defining data integrations, refer to Explore Data Integration.
Data integration
When defining a data integration, you need to create an integration flow using Designer.
Extract and load data
To define a data integration flow, create a project and scripts, and then place the input and output components of the required connectors on the script canvas of Designer. Next, configure the settings of the components according to the input and output data specifications. No coding is required.
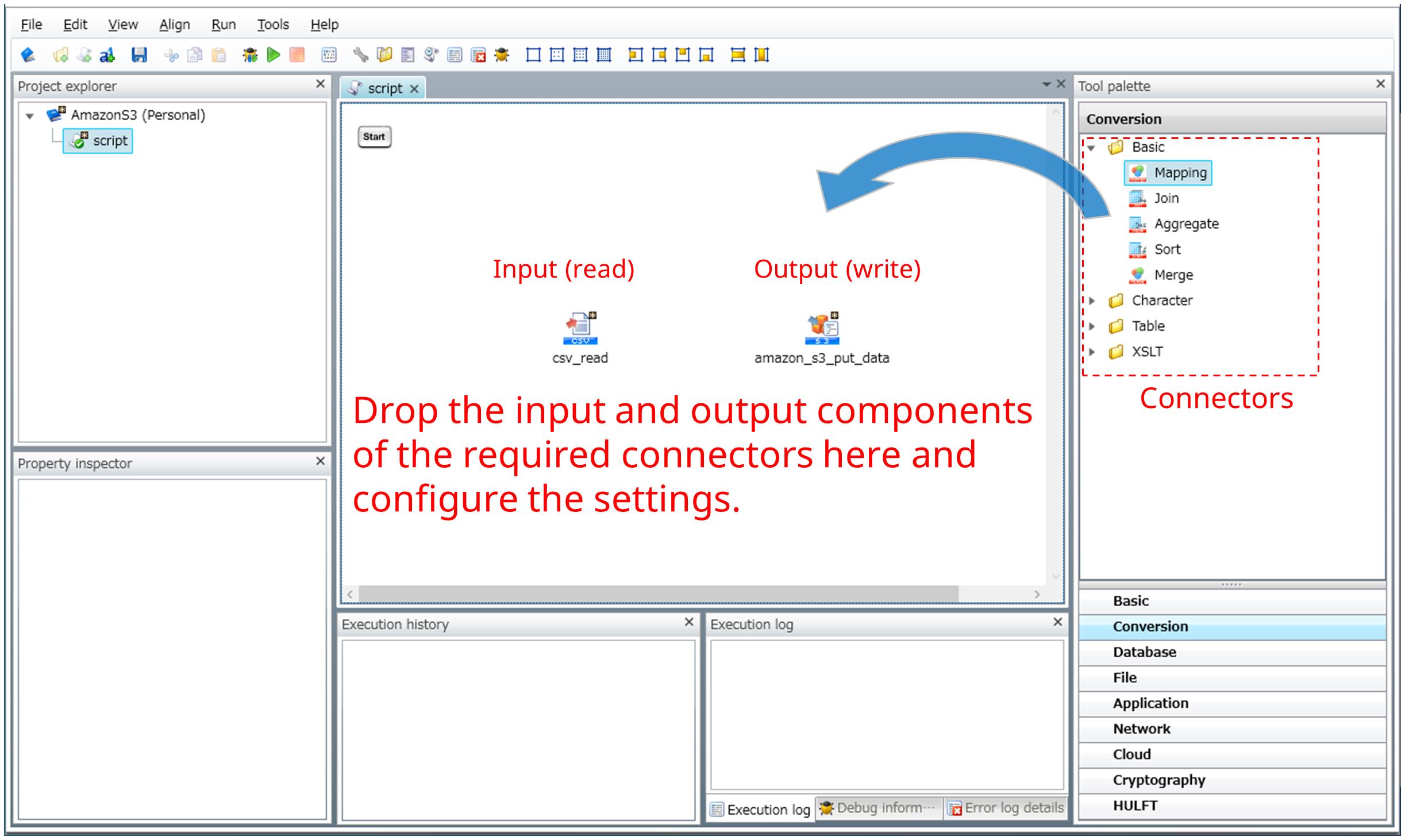
Figure 1.3 Defining the input and output components
Transform
In most cases, the input data needs to be cleansed and transformed into the required output data format or schema. In HULFT Square, you can specify data mapping or merging, or assign values using the converters. Place a converter in the script canvas and configure the settings as shown below.
Figure 1.4 Defining a converter
Data transformations between the input data and output data are defined in the Mapper editor as shown below:
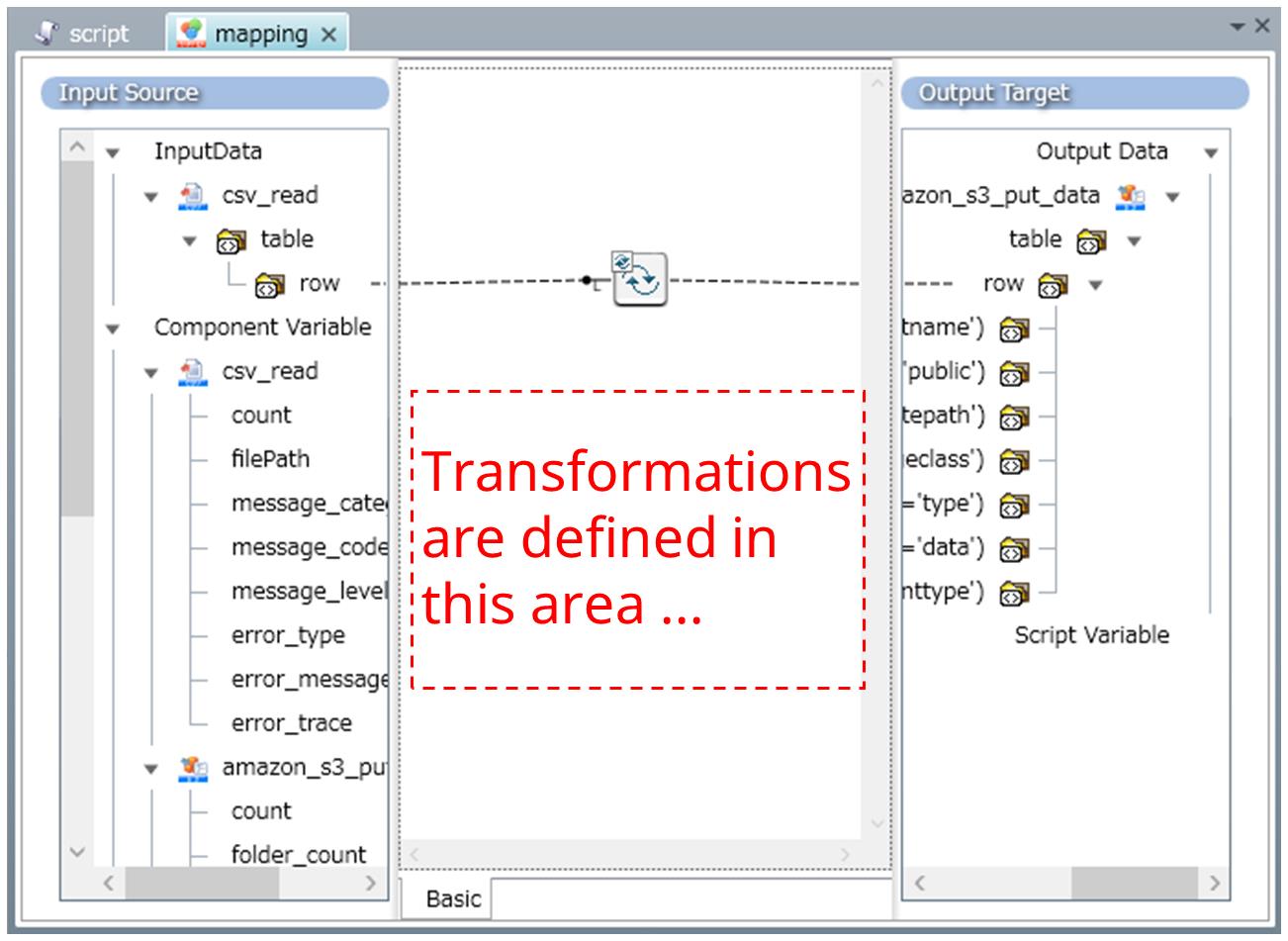
Figure 1.5 Defining a map
Other than the connectors and converters, you can add script components to specify conditional branches or error handling processes for more complicated integration flows.
For details of the connectors and Mappers, refer to Connector top page and Mapper.
For the basic tasks and flow to perform data integration, refer to Try HULFT Square.
For the concepts you need to understand when defining data integrations, refer to Explore Data Integration.
In HULFT Square, you can share settings with other users or groups using workspaces.
When you use HULFT Square with multiple people, workspaces make things more convenient.
You can create and use workspaces for different purposes and teams in order to work more efficiently.
To share settings, use workspaces in the following functions:
-
Storage
-
HULFT INTEGRATE (Projects, Connections, Data Formats, Variables, Schemas, Calendars)
-
API Projects
-
JOBS (File Event Jobs, REST API Jobs, Schedule Jobs, HULFT Transfer Jobs)
Select a workspace from the workspace dropdown list at the top of the page for each function.
Figure 1.6 Dropdown list to switch workspaces
For the workspace creation method, refer to Create a workspace to work together.
For more details about how to use workspaces to share settings, refer to Share settings with team members.
Monitoring
The monitoring function of HULFT Square realizes centralized monitoring and management of service statuses and various events.
The types of information that can be monitored with the monitoring function are as shown below:
-
Dashboard
Information about the content of your contract is displayed, such as storage usage and total amount of transferred data.
-
Applications
Applications are logged when applications are executed.
-
Services
Services are logged when scripts that perform data integration or data transfer are executed.
-
Jobs
Jobs (file event jobs, scheduled jobs, and HULFT Transfer jobs) are logged when they are executed.
-
Logs
In addition to access to REST API jobs and detailed records of storage operations, setting changes made by users and login history are logged.
By checking the logs, you can understand the whole status of running services.