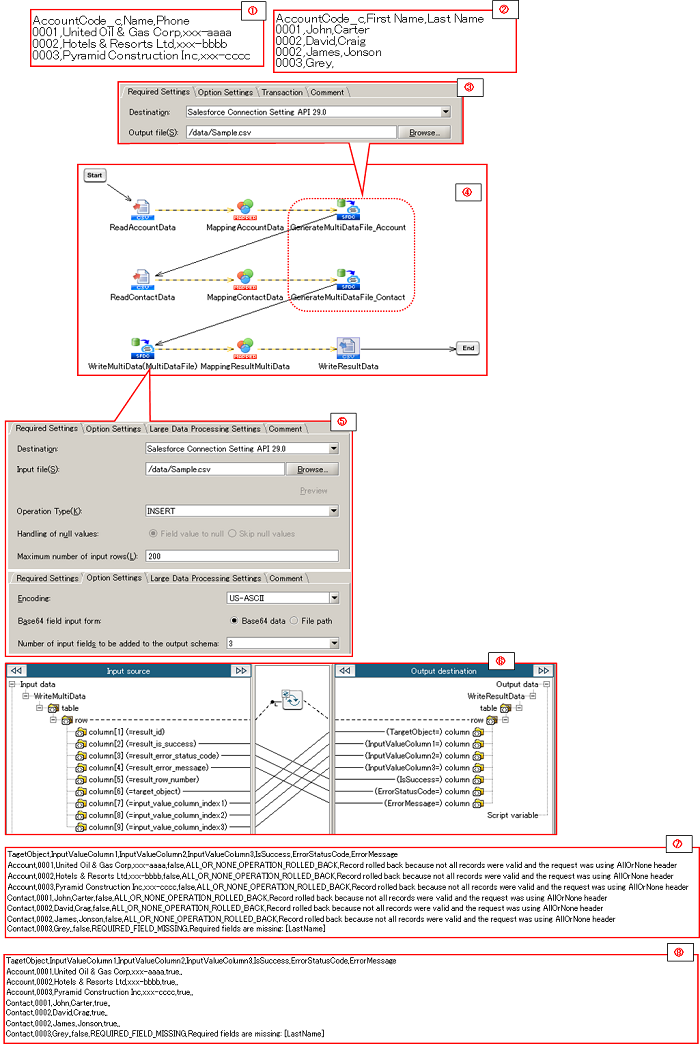
| Item name |
Required/Optional |
Use of Variables |
Description |
Supplement |
| Destination |
Required |
Not Available |
Select Global Resources.
- [Add...]:
Add new global resource.
- [Edit...]:
Global resource settings can be edited by [Edit Resource list].
|
- A global resource on API 23.0 or later versions can be specified.
|
| Input file |
Required |
Available |
Input the file path of the CSV format file created by [Generate Multi Data File] process.
By pressing the [Browse] button, an file chooser will be activated and a file can be chosen. |
|
| Operation Type |
Required |
Not Available |
Select the job operation type.
- [INSERT]:(default)
Insert data using the create service.
- [UPDATE]:
Update data using the update service.
- [DELETE]:
Delete data using the delete service.
|
- Upsert is not supported due to the API specification.
|
| Handling of null values |
Required |
Not Available |
Select, in the case that the input data is null for the update target field, either to overwrite the field by null or to skip it.
- [Field value to null]:(default)
If the input data is null, the update target field is overwritten by null.
- [Skip null values]:
If the input data is null, the update of the target field is skipped and it remains the same.
If the input data is not null, the update target field is overwritten by the input data.
|
- This is effective when [UPDATE] is selected in [Operation Type].
|
| Maximum number of input rows |
Required |
Available |
Specify the maximum number of data rows in the input file.
If the rows exceed the maximum number, an error occurs.
|
- The default value is "200".
- A number of 1 or greater, up to 200, can be set. An error occurs if any number outside of this range is set.
|
| Item name |
Required/Optional |
Use of Variables |
Description |
Supplement |
| Encoding |
Required |
Available |
Select or input the character encoding of the file to be read.
When input, you can specify encode supported in Java SE Runtime Environment.
 Refer to "Supported Encodings"(http://docs.oracle.com/javase/7/docs/technotes/guides/intl/encoding.doc.html) for details. Refer to "Supported Encodings"(http://docs.oracle.com/javase/7/docs/technotes/guides/intl/encoding.doc.html) for details.
|
|
| Base64 field input form |
Required |
Not Available |
Specify the input data type of items in Base 64 data type.
- [Base64 data]:(default)
Base64 Data is inserted.
- [File path]:
File path is inserted.
|
|
| Number of input data fields to be added to the output schema |
Required |
Not Available |
Select the number of input data items to be added to output schema.
- [0]:(default)
The input data schema is not displayed.
- [1-30]:
The selected number of schemata are added.
|
- If the number of 1 or more is selected, the selected number of schemata named [input_value_column_index(n)] are displayed in the output schema.
The values of the input data items are set in the order of rows from the beginning. If the number of items is less than the selected value, the remaining schema will be set by null.
- Please refer to Schema about the schema to be added.
|
| Element Name |
Column Name(Label/API) |
Description |
Supplement |
| row |
- |
Repeats as many times as the number of data rows exist in the input file. |
|
| column |
result_id |
Salesforce ID is output. |
|
| result_is_success |
Success Flag is output.
- [true]:Successfully processed
- [false]:Process failed. Please check the [result_error_status_code] as well as [result_error_message].
|
|
| result_error_status_code |
The status code, returned by the Salesforce API, is output. |
|
| result_error_message |
The message returned by the Salesforce API is output. |
|
| result_row_number |
Number is output based on the placement of the node within the data given to the input schema. |
|
| target_object |
The updating target object API name of this record is output. |
|
| input_value_column_index(n) |
The values of the input data items are set in the order of rows from the beginning. If the number of items is less than the selected value, the remaining schema will be set by null.
The schemata of the numbers specified by [Number of input data fields to be added to the output schema] are added.
|
|
| Component Variable Name |
Description |
Supplement |
| record_count |
The number of data read is stored. |
- The default value is null.
|
| success_count |
The number of data that was successful in the updating processing is stored. |
- The default value is null.
|
| error_count |
The number of data that was unsuccessful in the updating processing is stored. |
- The default value is null.
|
| server_url |
The end point URL after Login is stored. |
- The default value is null.
|
| session_id |
The session Id is stored. |
- The default value is null.
|
| message_category |
In the case that an error occurs, the category of the message code corresponding to the error is stored. |
- The default value is null.
|
| message_code |
In the case that an error occurs, the code of the message code corresponding to the error is stored. |
- The default value is null.
|
| message_level |
In the case that an error occurs, the importance of the message code corresponding to the error is stored. |
- The default value is null.
|
| operation_api_exception_code |
The ExceptionCode of the occured error, in a case of API error, is stored. |
- The default value is null.
- For any error other than an API Error, the value is not stored.
 The content to be stored may change according to the version of DataSpider Servista. The content to be stored may change according to the version of DataSpider Servista.
|
| operation_error_message |
If an error occurs, the error message of the occured error is stored. |
- The default value is null.
- The content to be stored may change according to the version of DataSpider Servista.
|
| operation_error_trace |
When an error occurs, the trace information of the occured error is stored. |
- The default value is null.
- The content to be stored may change according to the version of DataSpider Servista.
|
| Row Name |
ID |
Description |
Number of Columns |
Position |
| Table Row |
* |
Specify one object API name. |
1 Column. (excludes the ID column) |
Output to either the beginning of the file or after the existing [Data Row]. |
| Schema Row |
** |
Define a comma-delimited list of Schema API names to write.
Define in the following format when updating a read attribute by external ID.
"Reference Field Name:Relationship Name:Related Object Name:Foreign Key Field Name" |
Write fields of the target schema. (excludes the ID column) |
Output after the [Table Row]. |
| Data Row |
(empty) |
Specify the data of the records to be written as a comma delimitated string.
Please ensure the order of the columns to be output matches the field order specified in the [Schema Row].
|
Write fields of the target schema. (excludes the ID column) |
Output after the [Schema Row].
Continue to output Data Rows when representing more than one record.
|
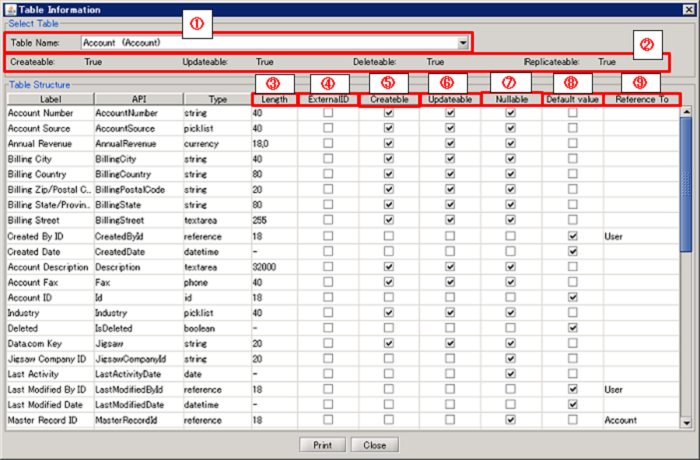
| Number in the Image |
Name |
Description |
Supplement |
| (1) |
Table Name |
Select the table whose structure to be shown. |
|
| (2) |
Table Information |
Display the available operations on the selected table. |
|
| (3) |
Length |
Display the Number of Digit of item |
|
| (4) |
External ID |
Display whether or not the object item is set as an external ID. |
|
| (5) |
Createble |
Display whether or not it can be set a value when adding data. |
|
| (6) |
Updatable |
Display whether or not it can be set a value when updating data. |
|
| (7) |
Nullable |
Display whether or not it can be set NULL when adding or updating data. |
|
| (8) |
Default value |
Display whether or not Salesforce automatically set a default value when adding data. |
|
| (9) |
Reference To |
Display the referring object name if the item is in reference relationship or master-servant relationship. |
|
| Exception Name |
Reason |
Resolution |
ResourceNotFoundException
Resource Definition is Not Found. Name:[] |
[Destination] is not specified. |
Specify [Destination]. |
ResourceNotFoundException
Resource Definition is Not Found. Name:[<Global Resource Name>] |
The resource definition selected in [Destination] cannot be found. |
Verify the global resource specified in [Destination] |
| java.net.UnknownHostException |
This exception occurs when the PROXY server specified in the global resource cannot be found. |
Verify the condition of the PROXY server. Or verify [Proxy Host] of the global resource specified in the [Destination]. |
- API 23.0 or earlier
org.apache.commons.httpclient.HttpConnection$ConnectionTimeoutException
- API 26.0 or later
java.net.SocketTimeoutException
connect timed out
|
A time-out has occurred while connecting to Salesforce. |
Verify the network condition and Salesforce server condition. Or check [Connection timeout(sec)] of the global resource specified in the [Destination]. |
- API 23.0 or earlier
org.apache.commons.httpclient.HttpRecoverableException
java.net.SocketTimeoutException: Read timed out
- API 26.0 or later
java.net.SocketTimeoutException
Read timed out
|
A time-out has occurred while waiting for a responce from the server after connecting to Salesforce. |
Verify the network condition and Salesforce server condition. Or check [Timeout(sec)] of the global resource specified in the [Destination]. |
| jp.co.headsol.salesforce.adapter.exception.SalesforceAdapterIllegalArgumentException |
Invalid value is set for the property of Salesforce adapter. |
Check the error message, and verify the settings. |
| com.sforce.soap.partner.fault.LoginFault |
Login to Salesforce has failed. |
Check the ExceptionCode or error message, and refer to the information about this type of error in Salesforce-related documents etc. |
| com.sforce.soap.partner.fault.UnexpectedErrorFault |
An unexpected error has occured while processing to Salesforce. |
Check the ExceptionCode or error message, and refer to the information about this type of error in Salesforce-related documents etc. |