DataSpiderServista mandates the conversion of every data to a XML format compliant to its own internal XML Framework, when data is exchanged between components.XML Framework is at the heart of data handling subsystem.
The role of XML Framework
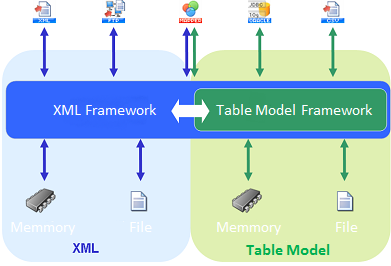
As every data is converted and exchanged between components in a single common data protocol via XML Framework, each processor component is able to handle every data uniformly.
There are largely two kinds of functions which XML Framework provides.
Absorbing the differences in persisting format of data
Each processor component becomes capable of handling Mass data when configured in its settings.The internal persisting format of the resulting data of a process differs depending on whether this option is enabled or not.
If the large volume data processing feature is not enabled, the resulting data of a process is stored in memory whereas if this capability is enabled, it is persisted to a file.
Regardless of the physical location to which the result data is stored, whether it is memory or a file, the data is uniformly handled by processor components, because the XML Framework absorbs the differences in the persisting format of the resulting data.
Absorbing the differences in the data model
There are two internal data model types. The XML type which provides flexibility in managing data structure and the Table model type that is suitable for rapid processing and handling in a large volume.
Although these two data model types do exist internally, the differences are absorbed by XML Framework, allowing the processor components handle these different model types uniformly as a single data model.
Each component effectively becomes decoupled from the others by the interposition of the XML Framework.
Let's assume that there is a process which retrieves data from a database and exports it to a CSV file. This process was performing without having its large data handing capability enabled as there only small amount of data needed to be processed at the beginning. However, the requirements for this process changed and it now needs to handle a large amount of data, but how? All what it takes to meet this requirement is to enable the large volume handling capability in the properties settings of the database adapter used; There is no adjustment needed in the CSV adapter settings. If it is required to write the data out in a XML document format instead of CSV, all what needs to be done is to swap the CSV adapter with an XML adapter.
Two data model types used in the XML Framework are the table model type and the XML type.
Table model type
The table model type is a data model suitable for rapid data processing(read/convert/write)
The table model type is suitable for data models which includes CSV, database records consist of row and column, or any other tabular data which can be expressed as 2-Dimensional arrays.
The table model type is a data structure comprised mostly of the actual data. It produces minimum excessive data for its data structure, therefore it is very compact.It supports very high speed data access that is as fast as accessing arrays.
See Data Model section in the document provided for each adapter, for further details.
If two table model type components are connected together without the use of a mapper, the columns of a table model are processed in the same order as they appear in each data source.
A mapper needs to be interposed between two table model type components, if and only if transformation of values become necessary when they are sent from one component to the other, or if the columns of a table model data need to be reordered before they are consumed by others.
The relationships with Mapper
When a table model type components are specified for both input and output of an interposing mapper, a table model dedicated data transformer is loaded dynamically and there is no need to load schemas for both input and output ends.The dedicated transformer allows handling of a large amount data at very high speed.
On the down side however, data is processed individually by each row in its model, therefore an operation such as combining the data found in the previous rows with the data in the current row being handled is not possible.
Also, no schema need to be loaded in Mapper, as long as both input source and the output destination are table model type components.
XML type
XML type retains data in its own intermediate string format that conform to the definitions of the XML.
XML type provides flexibility in its structural design and is suitable for processing various kinds of heterogeneous data structures together.
To find out which adapters are XML type compatible, please refer to the Data Model section in the document available for each adapter.
Schema applied to the input and the output data source is component and operation dependent.
The Salesforce adapter for instance, automatically obtains the input and the output data schemas declared for each function that it performs, whereas the FTP adapter uses its own fixed schema for all of its operation. Last but not least, the XML adapter does not require any schema at all.
The relationships with Mapper
When an XML type component is specified as either input or output of the data source connected to a mapper, it becomes possible to select nodes by a variety of criteria, navigating its XML structure as appropriate in a loop operation.
It also suggests that the data structures can be altered freely as needed.
Although XML type is very flexible in this manner, its hierarchical structure is represented using DOM(Document Object Model) model internally and allocation of a large heap space becomes inevitable when a large amount of data needs to be processed.
Refer to "Property Reference" for the method of changing the heap size of DataSpiderServer how to change the heap size is for more information please.
Except for some XML type components, when it is connected to a mapper, Edit Schema at the whichever end that is specified becomes necessary.
A normal process loads all of the data to be handled in its memory space. In the case of large data handling however, the usage of memory is optimized by loading only minimum necessary data for its current operation and storing the reset of data in files. This mechanism actualizes the handling of large data that consumes as little memory as possible.
When a large volume of data needs to be handled by an adapter, in most case for its read operation, this feature can be used by enabling [Enable mass data processing] in the script or adapter settings.
All of the table model type adapters and some XML type adapters with the [Data processing method] tab found in their settings, are capable of processing large volume of data.
When large data handling is performed by a processor component, whether it is a table model or XML type, or if it is a mapper, only the minimum necessary data for each operation performed is loaded into memory and the result of processing is stored in the files local to DataSpiderServer.
If it is an XML type data, the maximum amount can be as big as the fixed buffer size specified for each adapter and can also be as small as 1 XML node in the XML document to be processed.
If it is a table model type data, the minimum data loaded into memory in one read operation is data consisting a row in a tabular structure. When the read operation completes, data is disposed from the memory space and is written to a file. When the read operation completes, data is disposed from the memory space and is written to a file.
An adequate amount of disk space is therefore needed to store the above discussed resulting data. The disk space consumed for this purposed is freed up after the script execution using the resulting data finished.
Allocation of a large heap space becomes inevitable when a large volume of data needs to be processed.
(Event If the components of the input source is performing large volume data processing, if the component that receives its resulting data does not support large volume data processing, the resulting data will take up all memory space needed.)
Refer to "Property Reference" for the method of changing the heap size of DataSpiderServer how to change the heap size is for more information please.
DataSpider Servista has functions corresponding to mass data processing other than mass data processing. For details, please refer to "Mass Data Correspondence".
 See Data Model section in the document provided for each adapter, for further details.
See Data Model section in the document provided for each adapter, for further details.
 Allocation of a large heap space becomes inevitable when a large volume of data needs to be processed.
Allocation of a large heap space becomes inevitable when a large volume of data needs to be processed.
 DataSpider Servista has functions corresponding to mass data processing other than mass data processing. For details, please refer to "Mass Data Correspondence".
DataSpider Servista has functions corresponding to mass data processing other than mass data processing. For details, please refer to "Mass Data Correspondence".