XML Framework
XML Frameworkとは
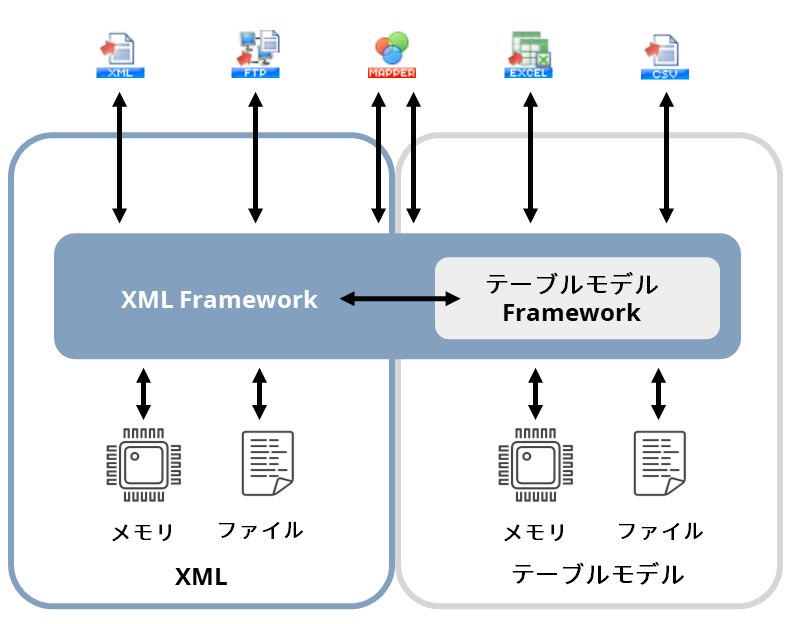
HULFT Squareでは、処理コンポーネント間でのデータの受け渡しをする際には、必ずこのXML Frameworkを介して処理を行います。そのためXML Frameworkは、HULFT Squareのデータハンドリングの心臓部にあたるといえます。
XML Frameworkの役割
XML Frameworkを経由してデータをやり取りすることにより、各処理コンポーネントはお互いにデータを透過的に扱えるようになります。
XML Frameworkには大きく2つの役割があります。
-
データの保存形式の差異を吸収する
HULFT Squareでは、処理コンポーネントごとに大容量データを扱うようにするかどうかの設定が可能です。大容量データ処理を有効にしなかった場合と有効にした場合とでは、結果データの内部的なデータ保存形式が異なります。
大容量データ処理を有効にしなかった場合には、結果データはメモリに保存され、大容量データ処理を有効にした場合には結果データはファイルに保存されます。
結果データの保存先がメモリであってもファイルであっても、XML Frameworkが保存形式の差異を吸収するため、処理コンポーネントからは単一のデータ形式に見えます。このため、処理コンポーネントの実装は保存形式に依存しません。
= 参照 =大容量データについては、「大容量データの対応」を参照してください。
-
データモデルの差異を吸収する
内部データモデルには、構造を柔軟に設計できるXML型と、高速処理や大容量データ処理に適応したテーブルモデル型があります。
内部的には2つのデータモデルが存在するものの、XML Frameworkがデータモデルの差異を吸収するため、処理コンポーネントからは単一のデータモデルに見えます。
= 参照 =XML型とテーブルモデル型については、「データモデル 」を参照してください。
XML Frameworkを経由することにより、処理コンポーネント同士はお互いに緩やかな結合となり、ある処理コンポーネントの設定や状態の変更が、ほかの処理コンポーネントに影響をおよぼさなくなります。
たとえば、データベースからCSVにデータを書き込む処理を作成した場合、当初はデータ量が少なく大容量データ処理を有効化せずに実行していたスクリプトが、要求の変更により大容量データの読み取りをサポートしなければならない状況になったとしても、データベースコネクター読み取り処理の大容量データの設定を有効にするだけです。 書き込み対象のCSVコネクターの設定を変更する必要はありません。また、CSVに書き出すのではなく、XML文書に書き出すように変更があった場合でも、CSVコネクターをXMLコネクターに変更するだけです。
データモデル
XML Frameworkで使用されているデータモデルは、テーブルモデル型とXML型があります。
テーブルモデル型
テーブルモデル型とは、データを高速に処理(読み取り、変換、および書き込み)するためのデータモデルです。
テーブルモデル型は、CSV形式のデータやデータベースのレコード/カラム情報など、二次元配列として表現できるデータモデルを扱う際に適しています。
テーブルモデル型は、実際のデータ(データベースの場合にはデータベースから抽出したデータ)以外の情報はほとんど生成されないため、非常にコンパクトなデータモデルとなっています。
また、内部では、配列にアクセスするのと同様のデータアクセス速度となるため、非常に高速に処理を行うことができます。
テーブルモデル型に対応しているコンポーネントについては、各コネクターのデータモデルの項を参照してください。
スキーマ
テーブルモデル型のスキーマ構造は以下のとおりです。基本的に「行」、「列」の情報を保持しています。
<table>
<row>
<column></column>
<column></column>
:
</row>
<row>
<column></column>
<column></column>
:
</row>
:
</table>
テーブルモデル型は上記のように同一のスキーマであるため、テーブルモデル型同士のデータを入出力する際に、値の変換やカラム順序の変換がない場合にはMapperは必要ありません。 Mapperを使用しない場合には、カラム順序は出現順序で処理されます。
Mapperとの関係
Mapperの入出力スキーマにテーブルモデル型のコンポーネントを指定した場合には、テーブルモデル型専用の変換エンジンに切り替えられます。テーブルモデル型専用の変換エンジンは大容量データに対応しており、非常に高速に変換処理が行われます。
テーブルモデル型専用変換エンジンは一部ロジックを除き、row要素(行)のループのみとなり、row要素(行)を超えての値のマッピングを行うことはできません。つまり、1行目の内容を2行目の内容に含めることはできません。
また、テーブルモデル型のコンポーネントをMapperの入力元または出力先とした場合、入出力スキーマの読み込みを行う必要はありません。
XML型
XML型とはデータを中間データとしてXML文字列で保持するデータモデルです。
XML型は構造を自由に設計できるため、処理によって構造が異なる場合に適しています。
XML型に対応している処理コンポーネントについては、各コネクターのデータモデルの項を参照してください。
スキーマ
処理コンポーネントや操作によって異なります。
XMLコネクターなどのように特にスキーマを持たないものや、FTPコネクターのように固定のスキーマを持つものなどがあります。
Mapperとの関係
XML型がMapperの入出力のどちらかに設定された場合には、繰り返しのノードを自由に指定できます。 これは、構造を自由に変換できることを意味します。
このようにXML型は非常に柔軟ではありますが、Mapper内部ではDOM(Document Object Model)形式で処理されるため、メモリ使用量が多くなります。
また、XML型のコンポーネントをMapperの入力元または出力先とした場合、一部コンポーネントを除き、入出力スキーマの読み込みを行う必要があります。
入出力スキーマの読み込みについては、「スキーマ編集」を参照してください。