Parallel Stream Processing
Overview of Parallel Stream Processing
Parallel Stream Processing (hereinafter referred to as PSP) is a mechanism for high-speed processing of large amounts of data while reducing memory consumption.
PSP has the following features:
-
Memory consumption reduction
Instead of keeping all the input data in the memory, the data is processed in each processing, read > convert > write, in 1,000 data sets at a time.
Therefore, a large amount of data can be processed without the need for a large amount of memory.
-
Ultra large capacity data processing
In theory, there is no data capacity limit because the input data is processed without being stored to memory.
-
Performance improvement
When data is processed in the order of read > convert > write, CPU resources can't be used effectively.
Because each processing for read, convert, and write is distributed according to the multithread using PSP, even if a single processing is waiting for an I/O, processing such as convert can be performed in parallel with other threads.
Parallel Stream Processing architecture
PSP operates with the following architecture. Read, convert, and write processing are performed at the same time with different threads on a per data block basis.

The component that generates result data (read and convert processing in the above figure) is designed to hold two blocks (for example, a 1,000-line block) of result data internally.
When components that generate result data detect blocks where data is writable (state in which data is consumed), write processing is performed. If blocks where data is writable can't be detected (state in which data isn't consumed), the processing is put on standby.
The component that uses the result data (convert and write processing in the above figure) reads the data and starts the processing when blocks where data is readable (state in which data generation is completed) are detected in the result data of the input source component. If blocks where data is readable can't be detected (state in which data generation isn't completed), the processing is put on standby.
Processing flow
This section describes the processing flow for each processing step with a simple sample of read > convert > write.
Data A, Data B, and Data C of each step are shown as a single block of data to be read.
Step 1: Before processing
-
Data A: The data hasn't been read from the file.
-
Data B: The data hasn't been read from the file.
-
Data C: The data hasn't been read from the file.

Step 2: Read Data A
-
Data A: The data is read from the file in the read processing and is then written to the block of the read component.
-
Data B: The data hasn't been read from the file.
-
Data C: The data hasn't been read from the file.

Step 3: Read Data B and convert Data A
-
Data A: The data is converted in the convert processing and is then written to the block of the convert component.
-
Data B: The data is read from the file in the read processing and is then written to the block of the read component.
-
Data C: The data hasn't been read from the file.

All the processing is performed in parallel.
Step 4: Read Data C, and convert Data B and write Data A
-
Data A: The data is actually written to the DB in the write processing. In addition, the convert processing is completed, so the data is deleted from the block of the read processing.
-
Data B: The data is converted in the convert processing and is then written to the block of the convert component.
-
Data C: Because the read component block is empty, the data is read from the file in the read processing and is then written to the block of the read component.

All the processing is performed in parallel.
Step 5: Convert Data C and write Data B
-
Data A: Data A is completed up to the write processing.
-
Data B: The data is actually written to the DB in the write processing. In addition, the convert processing is completed, so the data is deleted from the block of the read processing.
-
Data C: The data is converted in the convert processing and is then written to the block of the convert component.

All the processing is performed in parallel.
Step 6: Write Data C
-
Data A: Data A is completed up to the write processing.
-
Data B: Data B is completed up to the write processing.
-
Data C: The data is actually written to the DB in the write processing. In addition, the convert processing is completed, so a deletion is performed from the block of the read processing.

All the processing is performed in parallel.
In this way, you can process ultra large amounts of data at high speed because the data is divided into blocks and each block is processed in parallel.
How to use Parallel Stream Processing
The Smart Compiler automatically detects the contents of the script and applies Parallel Streaming Processing.
Therefore, you can basically create scripts without being aware of parallel streaming.
For details, refer to Smart Compiler.
Parallel Stream Processing and threads
In PSP, multiple threads work together to perform processing.
In PSP, besides the script thread, threads are generated for the number of components that generate result data (in other words, components that are an input source for the subsequent components). The write components that don't generate result data operate in the same thread as the script.
For example, in a read > convert > write script, the number of generated threads is 3.
In a read > convert > convert > write script, the number of generated threads is 4.
Specification limitations
-
If a transaction is started, the component that is executed in PSP belongs to that transaction.
-
If a transaction isn't started, the component that is executed in PSP starts an exclusive transaction.
Because of that, if multiple components that use the same connection resource exist and if any of them are executed in PSP, separate connections are used.
-
In PSP, the result data can't be specified for an input source for multiple components.
-
With Variable Mapper, mapping the input document to variables is also regarded as specifying the result data as an input source.
-
-
Errors
-
In PSP, errors that occur in the read and convert components aren't processed as errors if a component that takes the convert component as the input source doesn't exist.
For example, even if an error occurs in the read component to which PSP is applied, the script is successful and an error message isn't output to the log.
-
-
Files that are processing targets between the read component and write component that perform processing with PSP can't be operated.
-
In PSP, some component variables can't be used.
= Reference =For details, refer to the help of each operation.
-
In PSP, when a component that creates result data is executed, threads are created.
-
Block sizes can't be changed.
-
Although schemas can be set with Mapper for the data flow from an argument or the data flow between Mappers, if the schemas are changed to a type other than table model type, they can't be operated as a PSP compatible Mapper.
In other words, memory must be secured to handle large amounts of data. When applying PSP, don't change Mapper schemas to those other than the table model type (XML type.)
= Reference =For information about the table model type and XML type, refer to Data models .
Notes
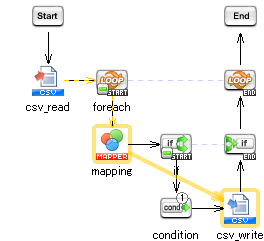
When placing Conditional Branch components in a PSP data flow
When PSP result data isn't used by Conditional Branch components, performance degrades.
You can prevent the degradation of performance by disabling PSP data flow.
The following script reads a CSV file line by line, and if those lines meet certain conditions, writes them to the CSV file. If PSP data flow is enabled between mapping and writing to the CSV file, performance degrades if the conditions aren't met.