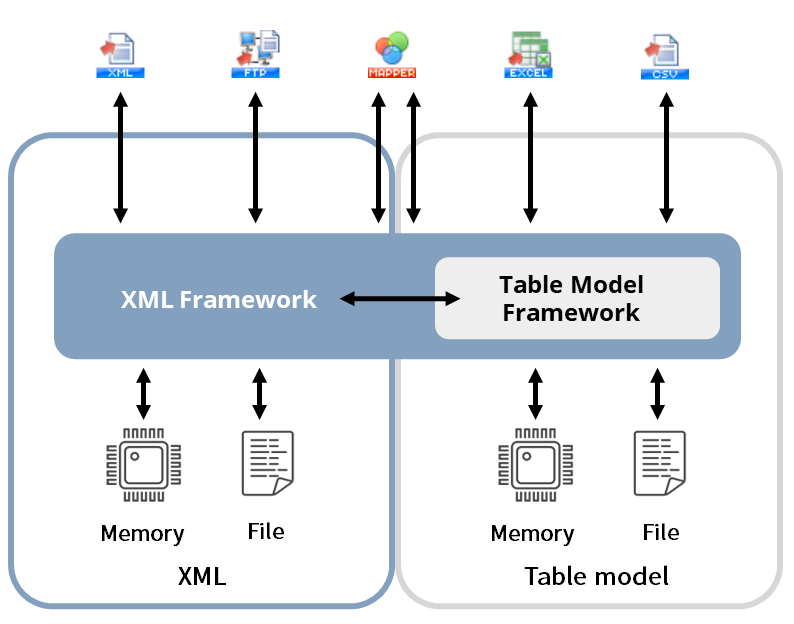
XML Framework
Overview of XML Framework
HULFT Square handles data between operation components exclusively with this XML Framework. Therefore, XML Framework can be said to be the core of data handling for HULFT Square.
Role of XML Framework
Data handling through XML Framework enables operation components to exchange data with each other transparently.
XML Framework has basically two roles.
-
Absorb differences between data saving formats
With HULFT Square, you can specify whether a component handles mass data or not for each operation component. Depending on whether mass data processing is enabled or disabled, different data saving formats are applied internally to the result data.
When mass data processing is disabled, the result data is saved in the memory. On the other hand, when mass data processing is enabled, the result data is saved in a file.
Whether the saving destination of the result data is the memory or a file, operation components view them as the same data format because XML Framework absorbs the difference between saving formats. Therefore, you can implement operation components regardless of the data saving format.
= Reference =For details about mass data, refer to Handling mass data.
-
Absorb differences between data models
Internal data models are available as the XML type that allows for flexible structural design and the table model type that is suitable for high-speed processing or mass data processing.
Although two data models exist internally, operation components view them as the same data model, because XML Framework absorbs the difference between data models.
= Reference =For details about the XML type and the table model type, refer to Data models .
XML Framework makes the connections between operation components flexible. Setting changes or status changes on a certain operation component don't affect other operation components.
For example, if you create an operation to write data from a database to a CSV file, at the beginning, the script runs with small data without enabling mass data processing. But now due to different demands, support for reading mass data is necessary. In such a case, you only have to enable the settings for mass data for the database connector read processing. You don't have to change the settings of the CSV connector for the writing destination. When the change from a CSV file to an XML document is on the writing destination, you only have to change from the CSV connector to the XML connector.
Data models
XML Framework uses two types of data models: the table model type and XML type.
Table model type
The table model type is a data model for high-speed data processing (read, convert, and write).
The table model type is suitable for handling data models that are expressible as two-dimensional arrays, such as CSV format data and database record/column information.
The table model type is quite compact because it doesn't generate information other than the actual data (in the case of a database, the data extracted from the database).
Also, the internal processing speed is quite fast because the speed to access data is almost the same as the speed to access arrays.
For details about components compatible with the table model type, refer to the data models section for each connector.
Schema
The table model type has a schema structure as shown below. The information is basically maintained for "row" and "column".
<table>
<row>
<column></column>
<column></column>
:
</row>
<row>
<column></column>
<column></column>
:
</row>
:
</table>
As shown above, the table model type has the same schema. Therefore, Mapper isn't necessary to be used to input and output data with the table model type if the values and the column order aren't converted. When Mapper isn't used, the order of the column that is processed is as the columns appear.
Relation with Mapper
When the table model type components are specified for the input and output schema of Mapper, an exclusive conversion engine for the table model type is used. The exclusive conversion engine for the table model type supports mass data handling, and the conversion speed is fast.
The exclusive conversion engine for the table model type only loops through row elements, with the exception of certain logics. You can't map values across row elements. In other words, you can't include the content of the first row in the second row.
Note that if a table model type component is specified for the input or output of Mapper, reading of the input or output schema isn't necessary.
XML type
The XML type is a data model that maintains XML strings as intermediate data.
Because the XML type has a flexible structural design, it is suitable when the structures vary depending on the processing.
For details about XML type-compatible operation components, refer to the data models section for each connector.
Schemas
The schema varies depending on the operation component or the action.
Some connectors, like the XML connector, have no schema, while others, like the FTP connector, have a fixed schema.
Relation with Mapper
When the XML type is specified for either the input or output side of Mapper, you can freely specify nodes for looping. This means that you can convert the structure as required.
The XML type has flexibility, but uses up a lot of memory because of DOM (Document Object Model) processing in Mapper.
Note that if an XML type component is specified for the input or output of Mapper, reading of the input and output schema is necessary, with the exception of certain components.
For details about loading the input and output schema, refer to Edit Schema.