Single byte codes in HULFT
There are two types of single byte codes that HULFT uses (character codes in ASCII and character codes in EBCDIC).
During file transfer involving conversion between different code sets, HULFT carries out conversion of single byte codes between the code sets.
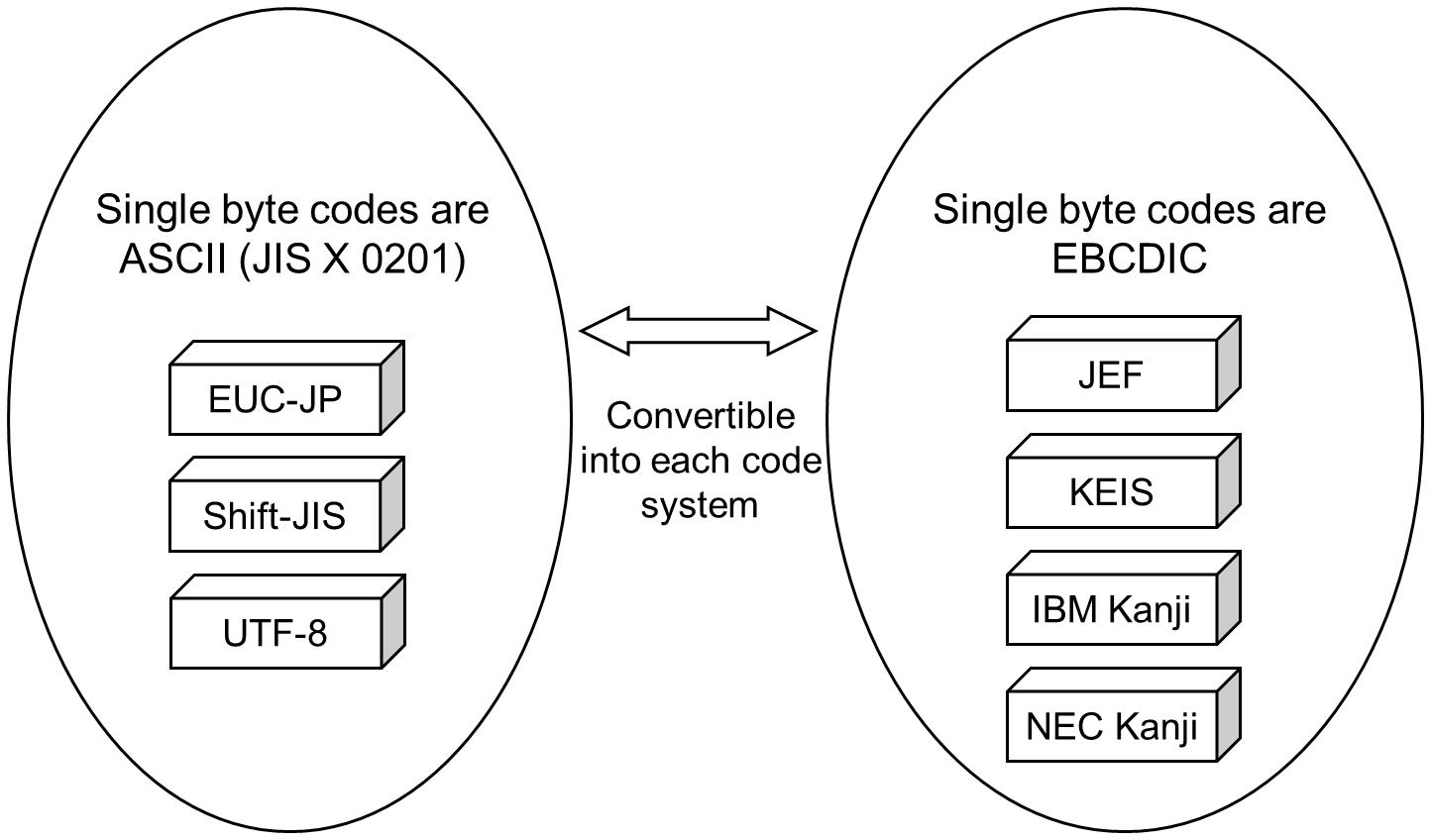
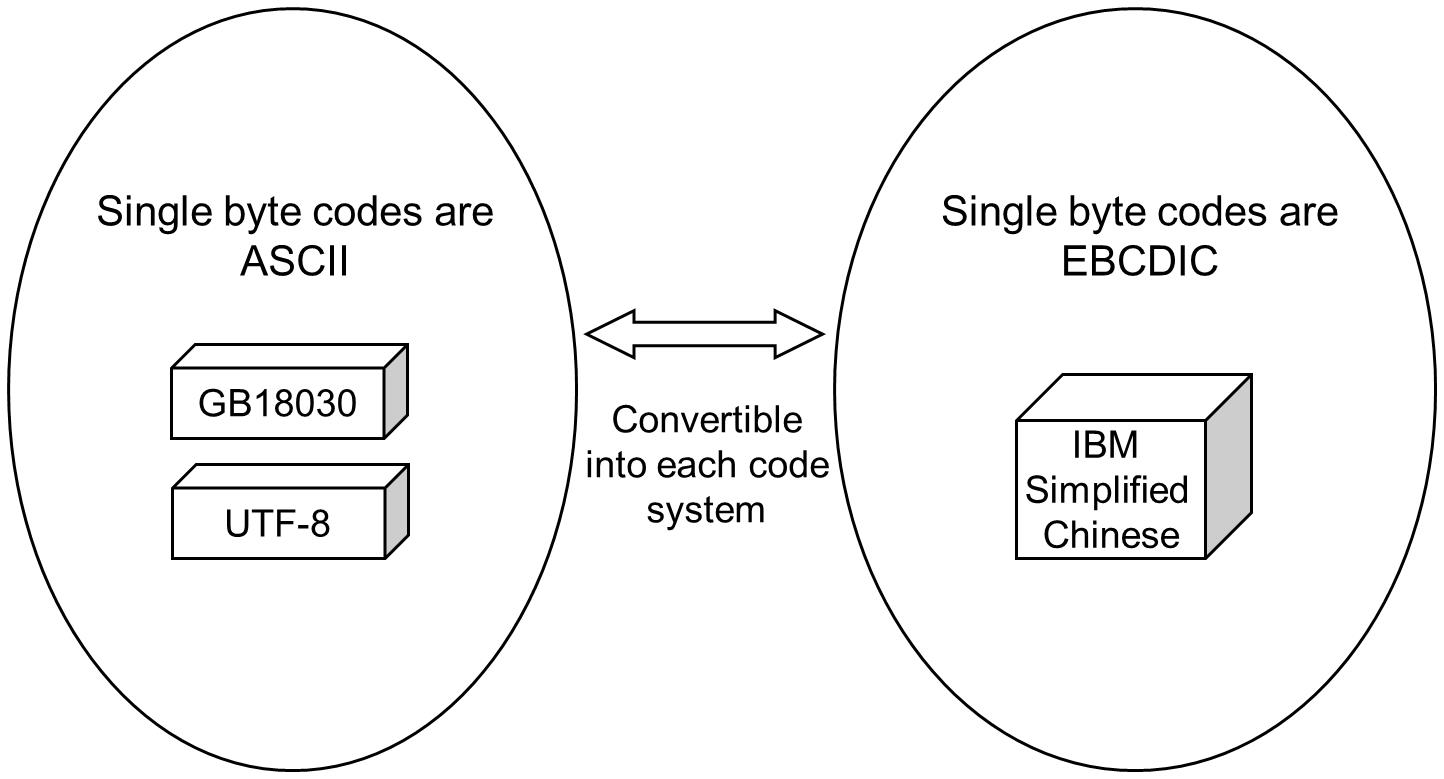
Figure 1.5 Single Byte Code Conversion (for Code-set Conversion for Chinese)
The following describes character codes in ASCII and character codes in EBCDIC that HULFT supports.
- Character codes in ASCII
-
For the Type-ASCII Code Set, HULFT uses character codes in ASCII for single byte codes.
In Code-Set Conversion for Japanese, the codes of the characters in the "JIS X 0201" standard are handled as character codes in ASCII.
EUC-JP and UTF-8 express half-width Katakana characters and certain other characters in multiple bytes. However, HULFT handles these characters as single byte codes.
When HULFT carries out Code Conversion of characters that are more than one byte, the size of the codes increases or decreases.
= Remarks =-
For details on the code size increases and decreases, refer to Examples of Code Conversions.
-
For details on the Type-ASCII Code Set, refer to Type-ASCII Code Set and Type-EBCDIC Code Set.
-
- Character codes in EBCDIC
-
For the Type-EBCDIC Code Set, HULFT uses character codes in EBCDIC for single byte codes.
For the Type-EBCDIC Code Set, the type of EBCDIC to be used varies depending on the host type and the user's specification.
Also, the types of EBCDIC available for Code-set Conversion for Japanese differ from the type available for Code-set Conversion for Chinese.
Table 1.8 Types of EBCDIC shows the types of EBCDIC that HULFT can use.
Types of EBCDIC that HULFT Can Use
Language
Remarks
A
Katakana
Japanese
EBCDIC that includes Katakana
B
Lowercase
EBCDIC that includes lowercase alphabet
C
ASCII
EBCDIC that Mainframe (MSP and XSP) uses
D
ASPEN
EBCDIC that Mainframe (VOS3) uses
E
Japan (Latin) for IBM
EBCDIC that includes lowercase alphabet
EBCDIC that Mainframe (z/OS) and IBM i use
F
Japan (Latin) Extended for IBM
EBCDIC which includes katakana in addition to codes covered by 'Japan (Latin) for IBM'
EBCDIC that Mainframe (z/OS) and IBM i use
G
NEC Katakana
EBCDIC that Mainframe (ACOS) uses
H
Japan (Katakana) Extended for IBM
EBCDIC which includes lowercase alphabet and the following symbols in addition to codes covered by 'Katakana': brackets ([]), caret (^)
EBCDIC that Mainframe (z/OS) and IBM i use
I
Simplified Chinese Extended
Chinese
EBCDIC for Simplified Chinese
= Remarks =-
You can specify a setting for EBCDIC Set in the Send Management Information or the Receive Management Information.
Refer to Operation Manual for the details on the Send Management Information or the Receive Management Information.
For instant transfer, the setting for Instant Transfer EBCDIC Set in the System Environment Settings is used. For details on the types of EBCDIC for instant transfer, refer to Administration Manual for the host type in use.
-
For details on the Type-EBCDIC Code Set, refer to Type-ASCII Code Set and Type-EBCDIC Code Set.
-