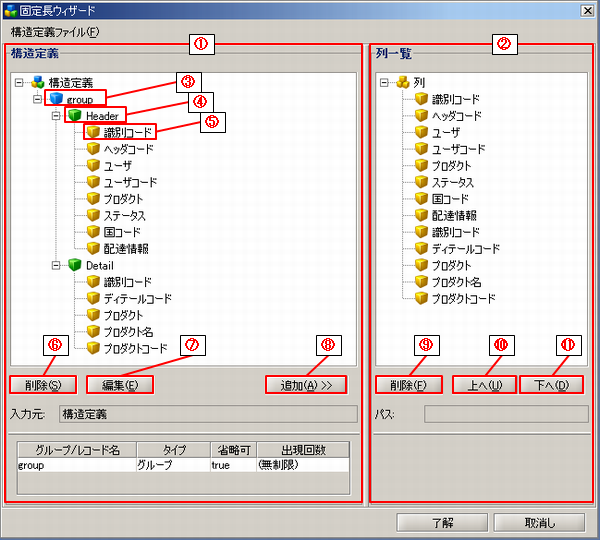
固定長アダプタはこの定義にそってファイルを読み取ります。
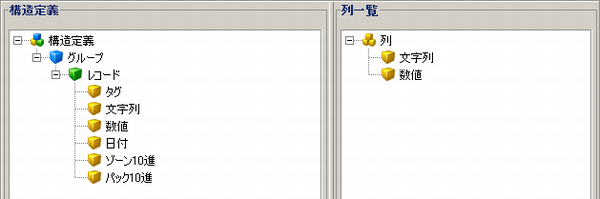
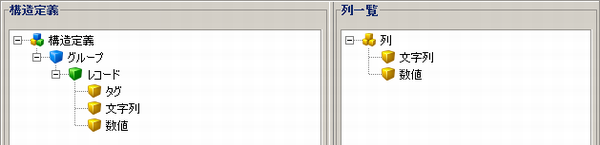
- 構造定義は、構造定義アイコンを親としてツリー構造で表現します。
この設定により必要な情報だけを取り出すことが可能です。
- 列一覧には、構造定義で設定した要素を登録することができます。
- 列一覧はテーブルモデル型と同様の構造です。
 テーブルモデル型については、「データモデル」を参照してください。
テーブルモデル型については、「データモデル」を参照してください。
- グループは青色のアイコンで表現されます。
- レコードは緑色のアイコンで表現されます。
- フィールドは黄色のアイコンで表現されます。
- 要素の右クリックメニュー[削除]からも同様の操作が可能です。
- 要素の右クリックメニュー[プロパティ]からも同様の操作が可能です。
- 要素の右クリックメニュー[削除]からも同様の操作が可能です。
 ニブルとは、情報量の単位の1つで、4ビットに相当します。
ニブルとは、情報量の単位の1つで、4ビットに相当します。
 以下の場合、列一覧に追加されたフィールドの順番は保証されません。
以下の場合、列一覧に追加されたフィールドの順番は保証されません。