

 本ページの記述は、前項「サービスの基礎知識」を読了し、サービスの基本的な概念やスクリプトの作成方法について理解していることを前提としています。
本ページの記述は、前項「サービスの基礎知識」を読了し、サービスの基本的な概念やスクリプトの作成方法について理解していることを前提としています。
 ログレベルの詳細については、「ログレベル」を参照してください。
種別の詳細については、「種別」を参照してください。
ファイルシステムの詳細については、「DataSpiderファイルシステム」を参照してください。
ログレベルの詳細については、「ログレベル」を参照してください。
種別の詳細については、「種別」を参照してください。
ファイルシステムの詳細については、「DataSpiderファイルシステム」を参照してください。
 使用禁止文字については、「DataSpider Servista使用禁止文字について」を参照してください。
例外監視の詳細については、「例外監視処理」を参照してください。
アプリケーションログの詳細については、「アプリケーションログ出力先設定」を参照してください。
そのほか、プロジェクトに最適な開発標準を適宜設定してください。
インストール時の設定については、PDFドキュメントの「DataSpider Servistaインストールガイド」を、インストール後の設定については、「リポジトリDB管理」を参照してください。
リポジトリDBは、1つのDataSpiderServerにつき1つ用意してください。複数のDataSpiderServerで同一のリポジトリDBに接続することはできません。
リポジトリDBとして使用するデータベースのインスタンスはリポジトリDB専用とし、他システムでの使用は行わないでください。
詳細については、「チーム開発機能」を参照してください。
PSPの詳細については、「パラレルストリーミング処理」を参照してください。
PSPに対応するコンポーネントについては、「パラレルストリーミング処理で使用できるコンポーネント」を参照してください。
DataSpiderServerのヒープサイズの変更方法については、「プロパティリファレンス」を参照してください。
大容量データ処理の設定については、「大容量データ処理」を参照してください。
PSPと大容量データ処理の双方が有効になっている場合、PSPが優先され、大容量データ処理は行われません。
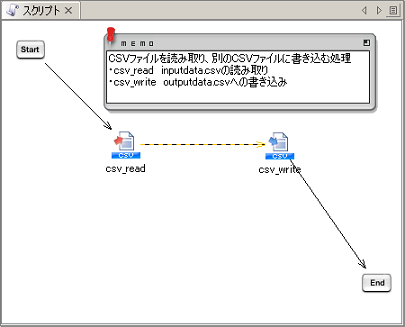
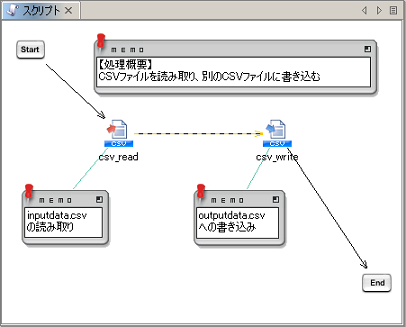
本項は、「サービスの基礎知識」ページの「スクリプトの作成と実行」で作成したスクリプトをもとに説明します。
使用禁止文字については、「DataSpider Servista使用禁止文字について」を参照してください。
例外監視の詳細については、「例外監視処理」を参照してください。
アプリケーションログの詳細については、「アプリケーションログ出力先設定」を参照してください。
そのほか、プロジェクトに最適な開発標準を適宜設定してください。
インストール時の設定については、PDFドキュメントの「DataSpider Servistaインストールガイド」を、インストール後の設定については、「リポジトリDB管理」を参照してください。
リポジトリDBは、1つのDataSpiderServerにつき1つ用意してください。複数のDataSpiderServerで同一のリポジトリDBに接続することはできません。
リポジトリDBとして使用するデータベースのインスタンスはリポジトリDB専用とし、他システムでの使用は行わないでください。
詳細については、「チーム開発機能」を参照してください。
PSPの詳細については、「パラレルストリーミング処理」を参照してください。
PSPに対応するコンポーネントについては、「パラレルストリーミング処理で使用できるコンポーネント」を参照してください。
DataSpiderServerのヒープサイズの変更方法については、「プロパティリファレンス」を参照してください。
大容量データ処理の設定については、「大容量データ処理」を参照してください。
PSPと大容量データ処理の双方が有効になっている場合、PSPが優先され、大容量データ処理は行われません。
本項は、「サービスの基礎知識」ページの「スクリプトの作成と実行」で作成したスクリプトをもとに説明します。

| ログレベル | |
|---|---|
| ↑ 高 低 ↓ |
NOTICE |
| INFO | |
| FINFO | |
| FINEST | |
| DEBUG |
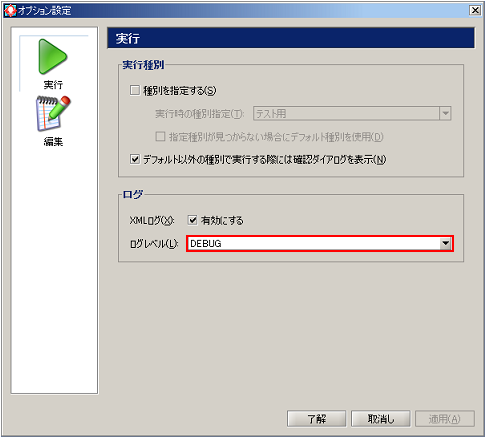
 [XMLログ]の[有効にする]チェックを外した場合は、ログは出力されません。
[XMLログ]の[有効にする]チェックを外した場合は、ログは出力されません。
 ログレベルの詳細については、「ログレベル」を参照してください。
ログレベルの詳細については、「ログレベル」を参照してください。
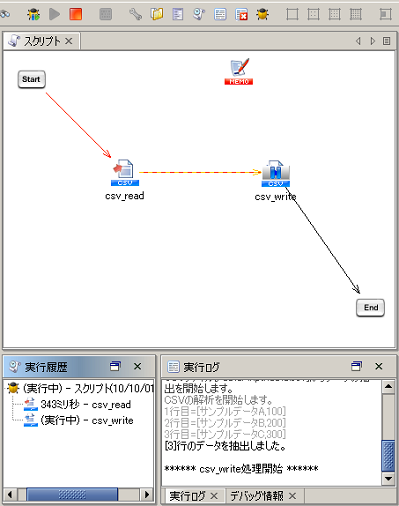 ブレークポイントで一時停止した状態では、処理済みのプロセスフローは赤色で表示されます。
デバッグ実行の場合、通常のテスト実行と以下の動作が異なります。
ブレークポイントで一時停止した状態では、処理済みのプロセスフローは赤色で表示されます。
デバッグ実行の場合、通常のテスト実行と以下の動作が異なります。
| コンポーネントアイコンの表示 | 状態 |
|---|---|
|
ブレークポイント設定状態 |
|
ブレークポイント解除状態 |
詳細については、「デザイナ」を参照してください。
| 32*32 | 16*16 | 8*8 |
|---|---|---|
 |
 |
 |
選択次第では、アイコンの位置が崩れてしまうこともありますが、そのような場合にはUndo/Redoで状態を戻してください。
設定方法については、「環境変数管理」を参照してください。
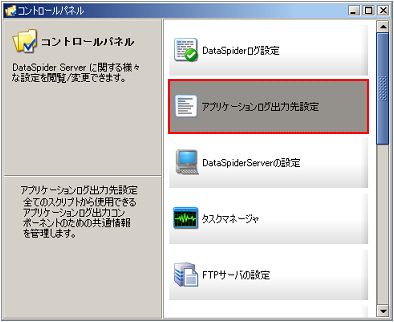
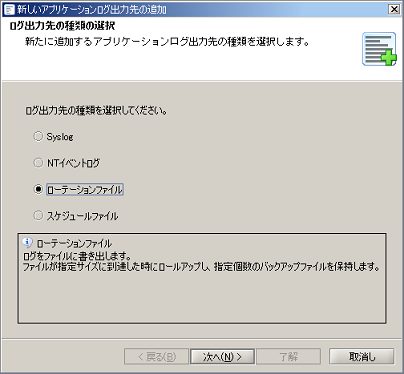
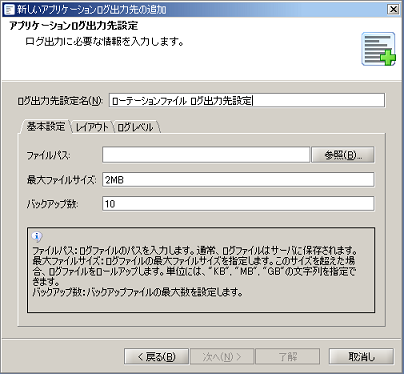
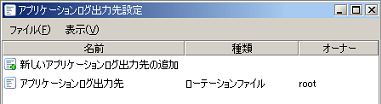 アプリケーションログ出力先の設定の詳細については、「アプリケーションログ出力先設定」を参照してください。
アプリケーションログ出力先の設定の詳細については、「アプリケーションログ出力先設定」を参照してください。
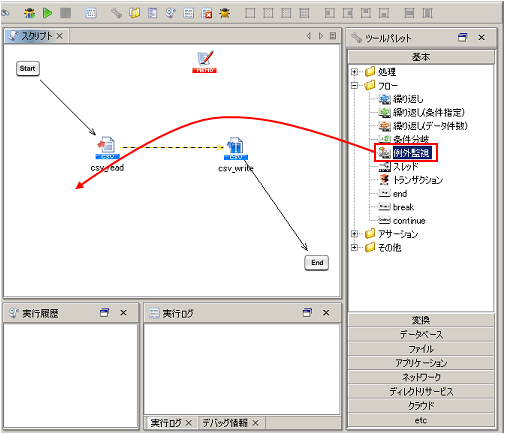
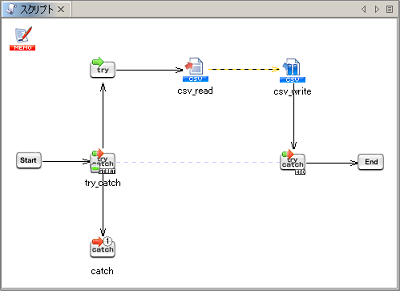
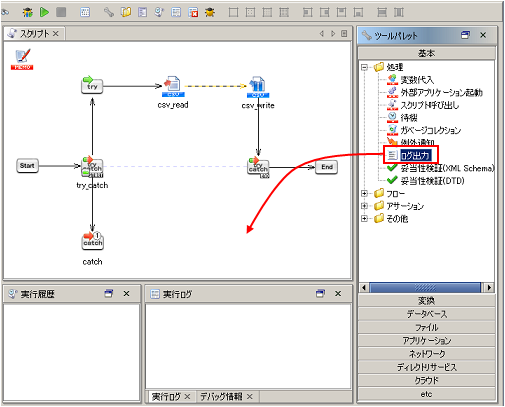
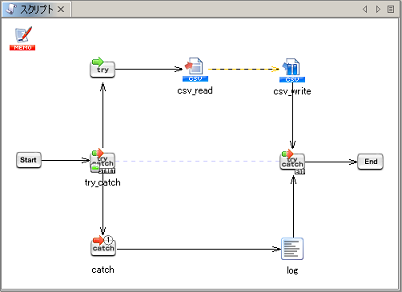

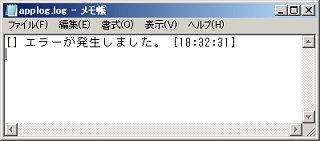 例外監視コンポーネントの詳細については、「例外監視処理」を参照してください。
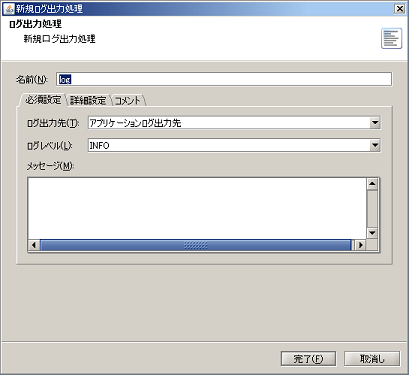
ログ出力コンポーネントの詳細については、「ログ出力処理」を参照してください。
例外監視コンポーネントの詳細については、「例外監視処理」を参照してください。
ログ出力コンポーネントの詳細については、「ログ出力処理」を参照してください。
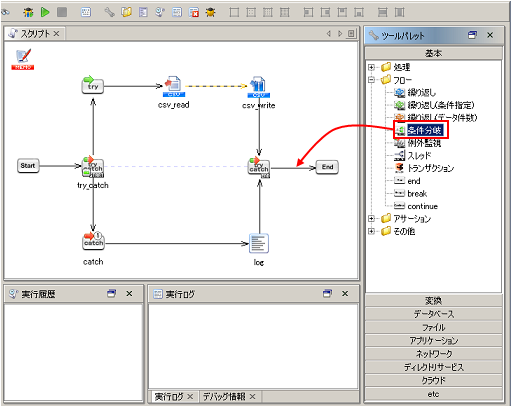
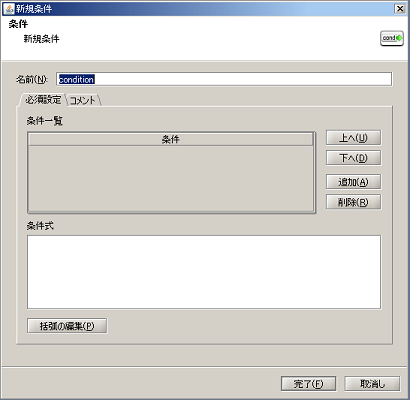
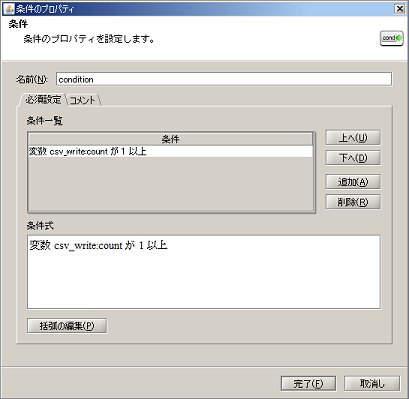
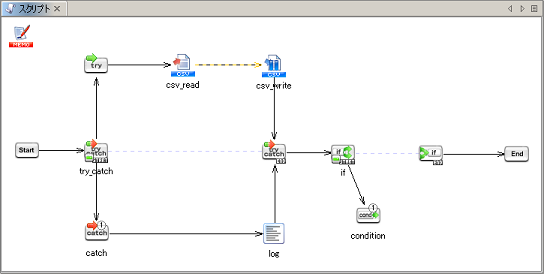
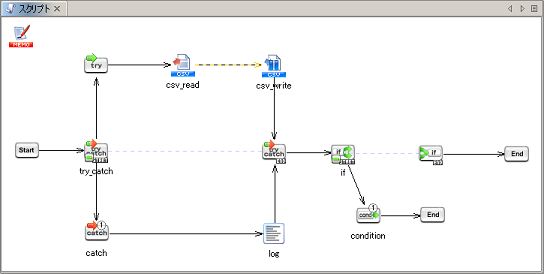
 条件分岐コンポーネントの詳細については、「条件分岐処理」を参照してください。
end処理の詳細については、「end処理」を参照してください。
条件分岐コンポーネントの詳細については、「条件分岐処理」を参照してください。
end処理の詳細については、「end処理」を参照してください。
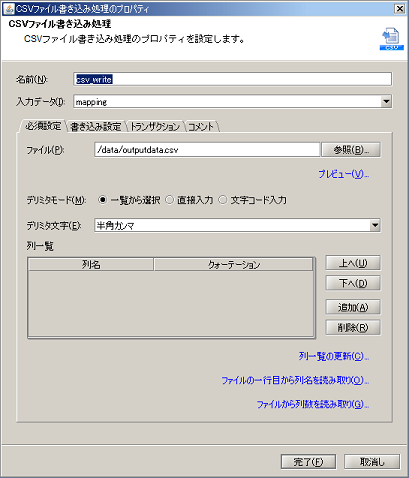
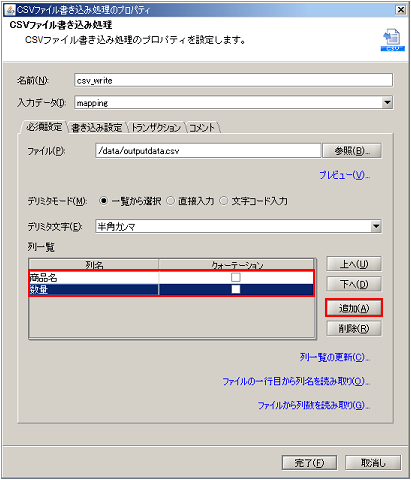
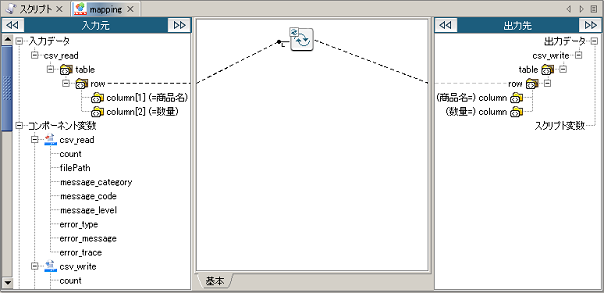
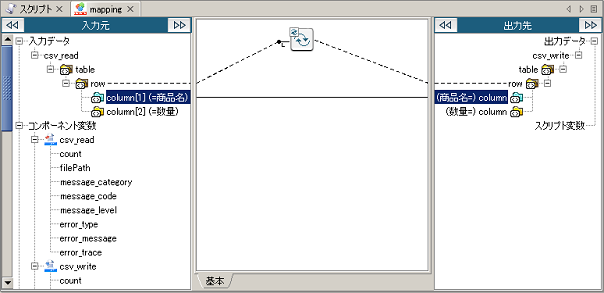
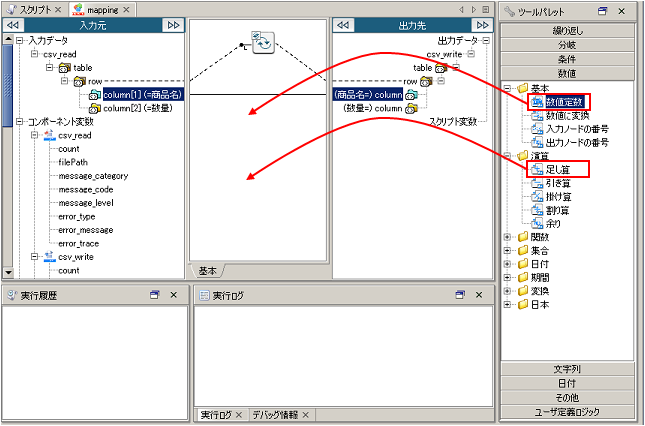
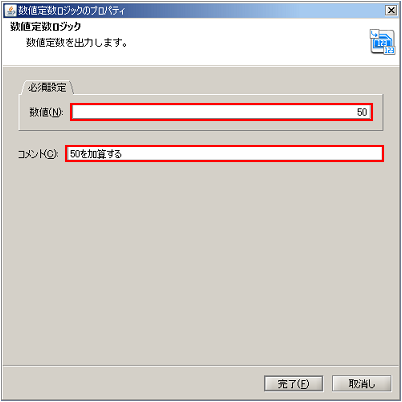
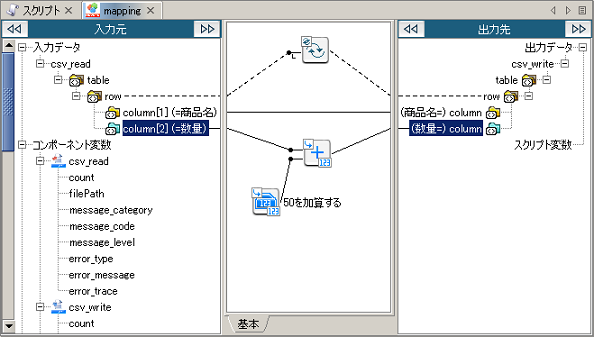
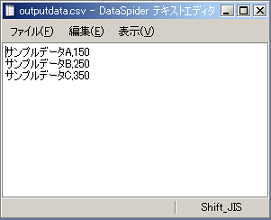 ドキュメントMapperの詳細については、「Mapper」を参照してください。
変数に保持された値の加工および変換を行うための変数Mapperの詳細については、「Mapper」を参照してください。
複数の入力データを統合するためのマージMapperの詳細については、「マージMapper」を参照してください。
ドキュメントMapperの詳細については、「Mapper」を参照してください。
変数に保持された値の加工および変換を行うための変数Mapperの詳細については、「Mapper」を参照してください。
複数の入力データを統合するためのマージMapperの詳細については、「マージMapper」を参照してください。
| コンポーネント名 | Mapperで相当する処理 | Mapperを選択するケース |
|---|---|---|
| 結合処理 |
|
|
| 集計処理 |
|
|
| ソート処理 |
|
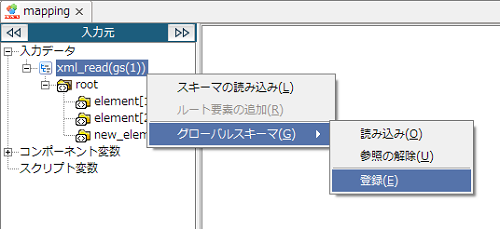
グローバルスキーマは、ドキュメントMapperでのみ使用できます。
グローバルスキーマの概要については、「グローバルスキーマ」も参照してください。
詳細については、「スクリプトキャンバスからグローバルスキーマを登録できるコンポーネントについて」を参照してください。
Mapperのスキーマは、スクリプトキャンバスからの登録はできません。Mapperエディタから登録してください。
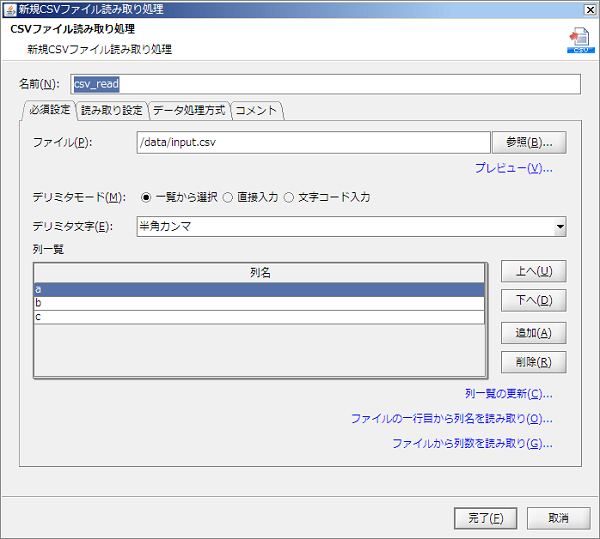
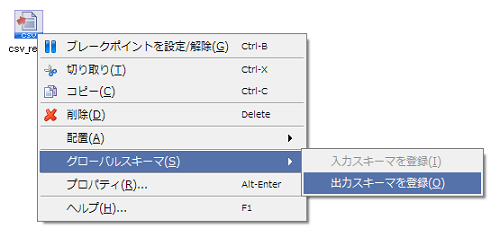 グローバルスキーマは、グローバルスキーマ名によって参照されます。 グローバルスキーマ名には、DataSpiderServer上で一意な名前を付けてください。
グローバルスキーマは、グローバルスキーマ名によって参照されます。 グローバルスキーマ名には、DataSpiderServer上で一意な名前を付けてください。
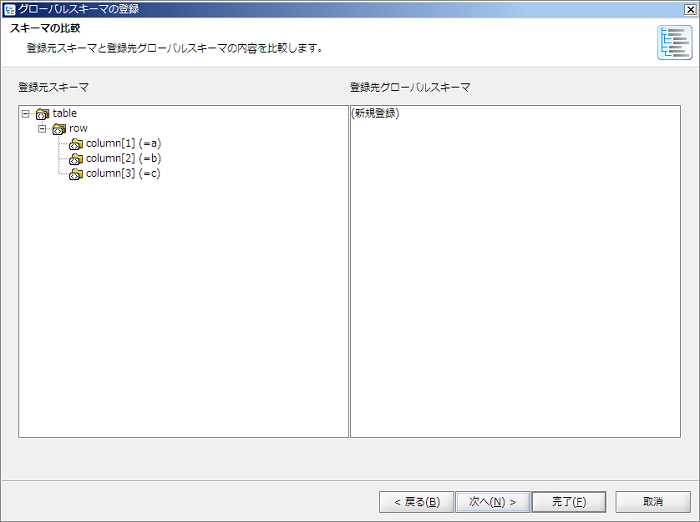
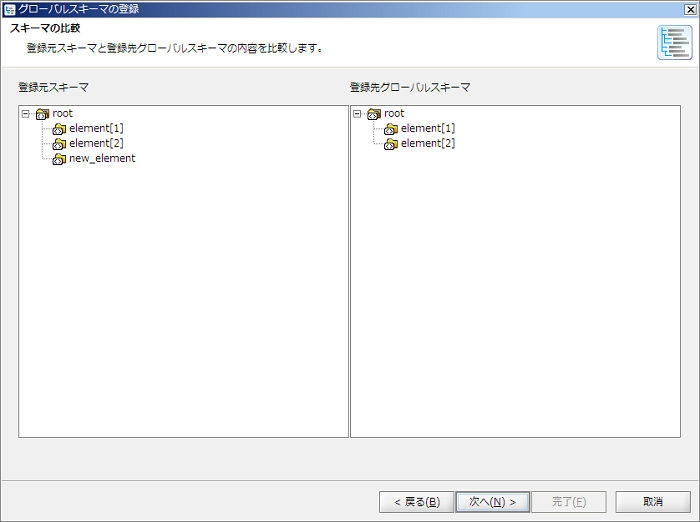
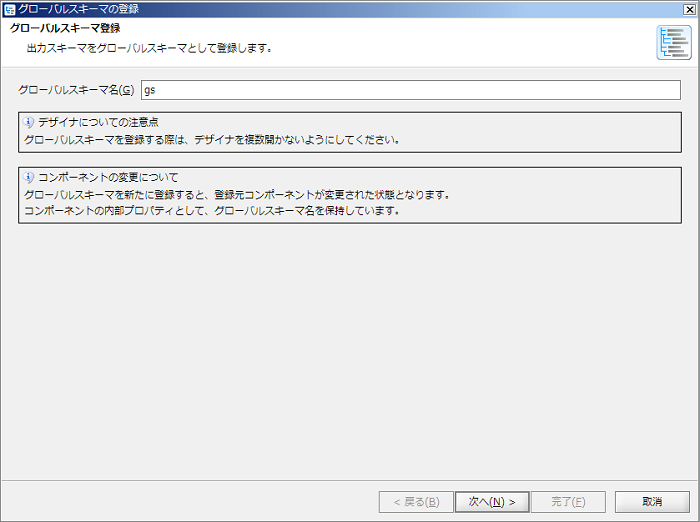 新規登録の場合、[登録先グローバルスキーマ]は存在しないため、「(新規登録)」と表示されます。
新規登録の場合、[登録先グローバルスキーマ]は存在しないため、「(新規登録)」と表示されます。
 登録されたグローバルスキーマはコントロールパネルの「グローバルスキーマの設定」で確認することができます。
ドキュメントMapperからのみ登録が可能です。変数MapperおよびマージMapperから登録することはできません。
登録されたグローバルスキーマはコントロールパネルの「グローバルスキーマの設定」で確認することができます。
ドキュメントMapperからのみ登録が可能です。変数MapperおよびマージMapperから登録することはできません。
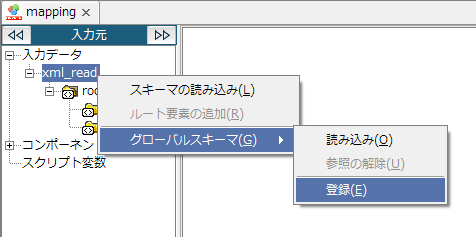 グローバルスキーマは、グローバルスキーマ名によって参照されます。 グローバルスキーマ名には、DataSpiderServer上で一意な名前を付けてください。
グローバルスキーマは、グローバルスキーマ名によって参照されます。 グローバルスキーマ名には、DataSpiderServer上で一意な名前を付けてください。
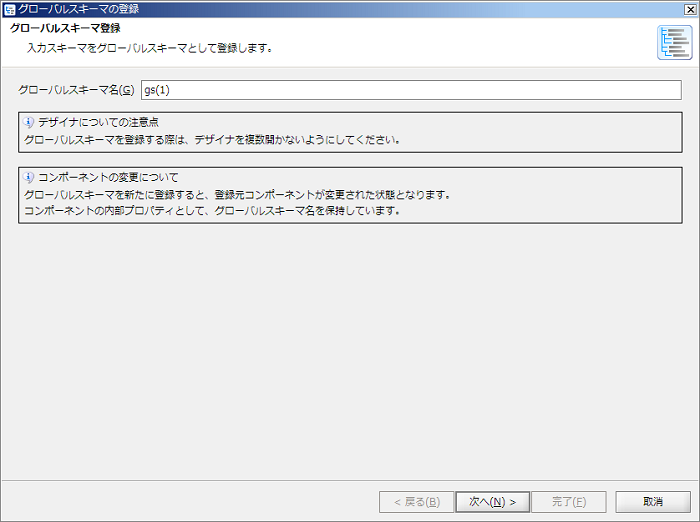 新規登録の場合、[登録先グローバルスキーマ]は存在しないため、「(新規登録)」と表示されます。
新規登録の場合、[登録先グローバルスキーマ]は存在しないため、「(新規登録)」と表示されます。
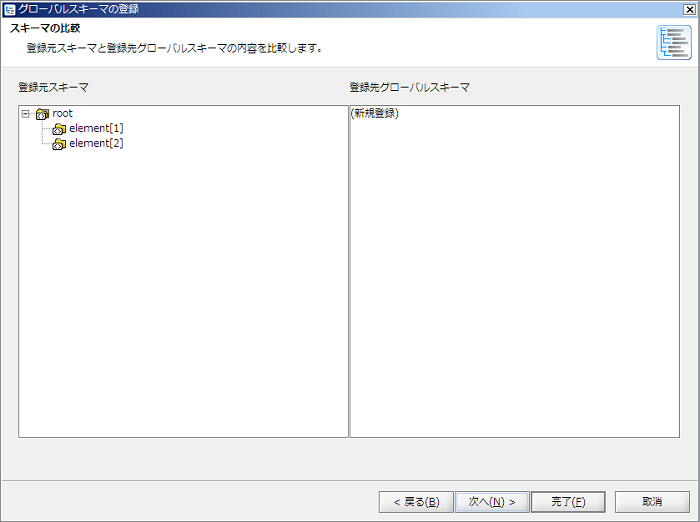
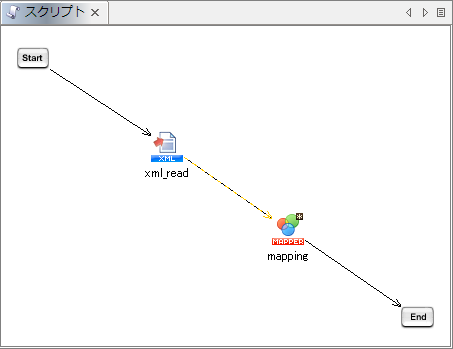
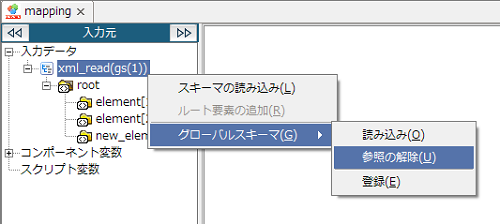
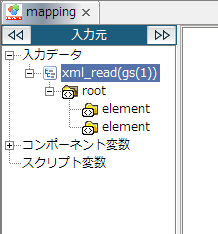 Mapperエディタからグローバルスキーマを登録した場合、同時にそのグローバルスキーマを参照している状態になります。
登録されたグローバルスキーマはコントロールパネルの「グローバルスキーマの設定」で確認することができます。
ドキュメントMapperからのみ参照が可能です。変数MapperおよびマージMapperから参照することはできません。
Mapperエディタからグローバルスキーマを登録した場合、同時にそのグローバルスキーマを参照している状態になります。
登録されたグローバルスキーマはコントロールパネルの「グローバルスキーマの設定」で確認することができます。
ドキュメントMapperからのみ参照が可能です。変数MapperおよびマージMapperから参照することはできません。
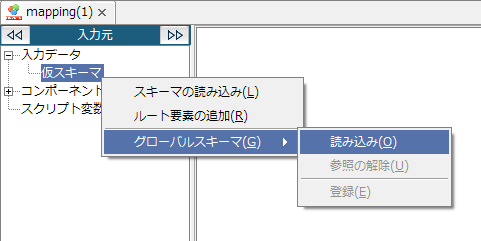
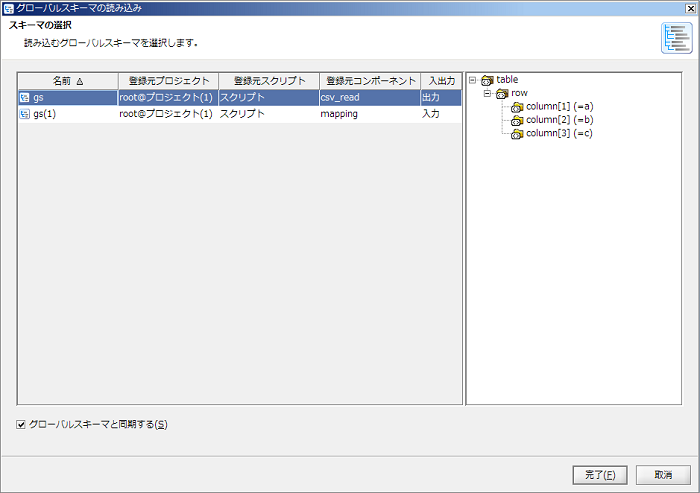
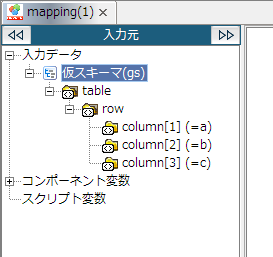 「スキーマの選択」画面で[グローバルスキーマと同期する]のチェックを外してから[完了]ボタンを押下すると、スキーマだけを読み込み、グローバルスキーマを参照しない状態となります。
「スキーマの選択」画面で[グローバルスキーマと同期する]のチェックを外してから[完了]ボタンを押下すると、スキーマだけを読み込み、グローバルスキーマを参照しない状態となります。
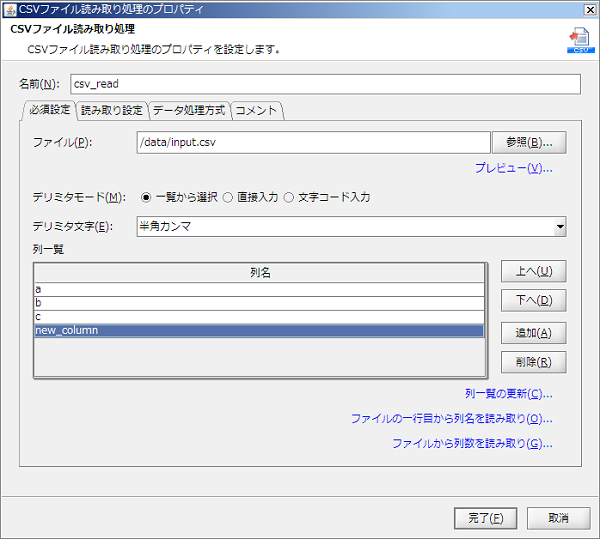
 一覧はサーバ上のプロジェクトにもとづいて作成します。チーム開発機能が有効の場合、対象となるプロジェクトはあらかじめサーバにコミットしておく必要があります。
一覧はサーバ上のプロジェクトにもとづいて作成します。チーム開発機能が有効の場合、対象となるプロジェクトはあらかじめサーバにコミットしておく必要があります。
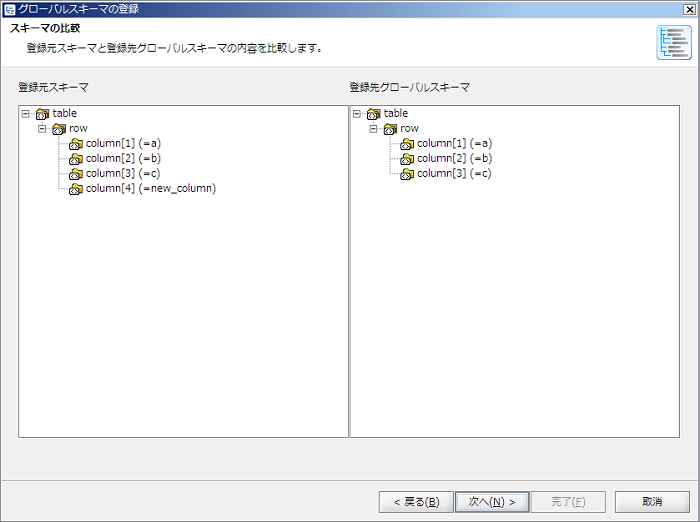
 チーム開発機能が有効の場合、プロジェクトはローカル保存されます。サーバへのコミットは行われません。
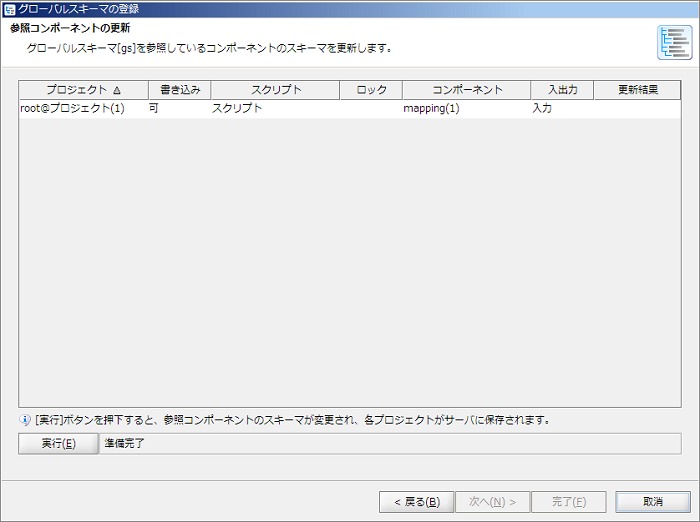
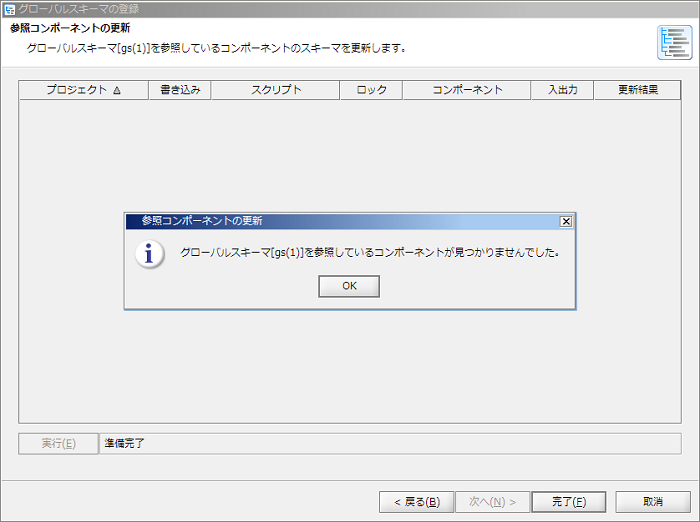
多数の参照コンポーネントを更新する場合、クライアントマシンの性能が求められます。詳細については、「参照コンポーネントの更新に求められる性能について」を参照してください。
チーム開発機能が有効の場合、プロジェクトはローカル保存されます。サーバへのコミットは行われません。
多数の参照コンポーネントを更新する場合、クライアントマシンの性能が求められます。詳細については、「参照コンポーネントの更新に求められる性能について」を参照してください。
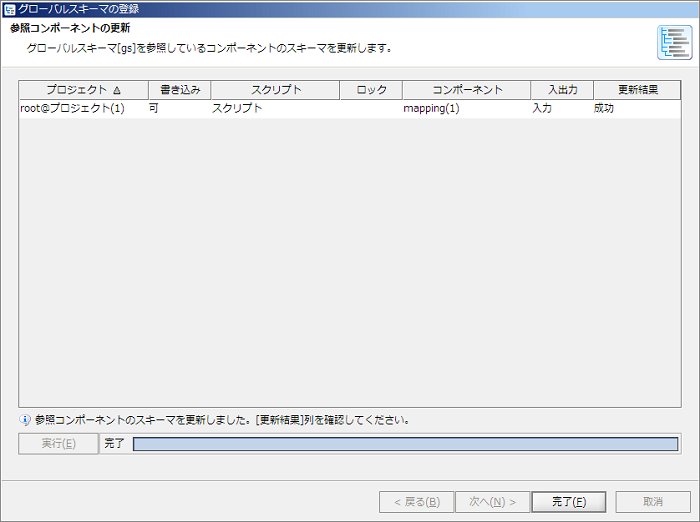 このとき、更新対象のプロジェクトをデザイナで開いている場合、そのプロジェクトに含まれるすべてのスクリプトは閉じられます。
このとき、更新対象のプロジェクトをデザイナで開いている場合、そのプロジェクトに含まれるすべてのスクリプトは閉じられます。
 参照コンポーネントが存在する場合、参照コンポーネントのスキーマを更新します。その手順については、「スクリプトキャンバスからの更新手順」と同様です。
参照コンポーネントが存在する場合、参照コンポーネントのスキーマを更新します。その手順については、「スクリプトキャンバスからの更新手順」と同様です。
 詳細については、「テスティングフレームワーク」を参照してください。
詳細については、「テスティングフレームワーク」を参照してください。
 サービス名のデフォルト値は、「<ユーザ名>@<プロジェクト名>」です。
サービス名のデフォルト値は、「<ユーザ名>@<プロジェクト名>」です。
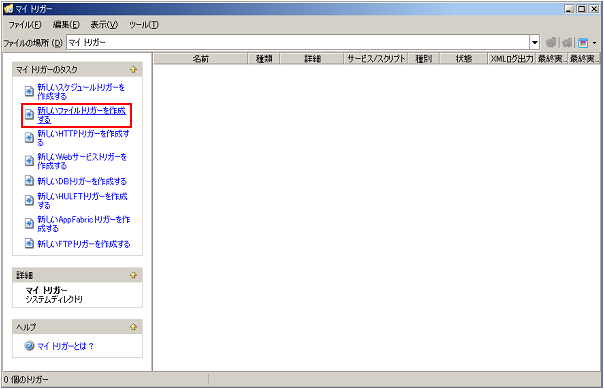
| トリガー名 | 説明 | 備考 |
|---|---|---|
| スケジュールトリガー | 日・週・月・年・インターバルといったスケジュール単位の設定によって発火します。 | |
| ファイルトリガー | 監視対象のファイルの新規作成・更新・削除を検知し、発火します。 | |
| HTTPトリガー | 特定のURLへのアクセスを検知し、発火します。 | |
| DBトリガー | 監視対象のテーブルの挿入・更新・削除を検知し、発火します。 | |
| FTPトリガー | DataSpiderServer上で動作するFTPサーバにアップロードされたファイルを検知し、発火します。 | |
| Webサービストリガー | 特定のWebサービスへのアクセスを検知し、発火します。 | |
| Amazon Kinesisトリガー | 監視対象のAmazon Kinesisストリームへのデータの送信を検知し、発火します。 | |
| SAPトリガー | 監視対象のメッセージを検知し、発火します。 | |
| SAP BCトリガー | SAP Business Connectorで指定したURLへのアクセスを検知し、発火します。 | |
| HULFT Scriptトリガー | HULFTの転送履歴を検知し、条件に一致した場合に発火します。 |

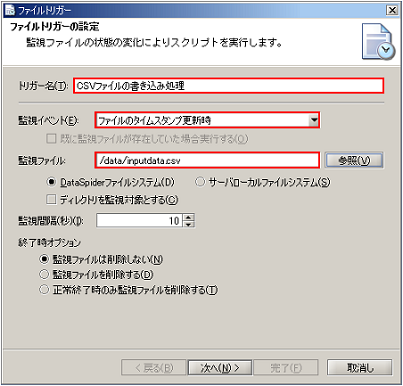
 [参照]ボタンでファイルチューザを起動し、ファイルを選択することもできます。
[参照]ボタンでファイルチューザを起動し、ファイルを選択することもできます。
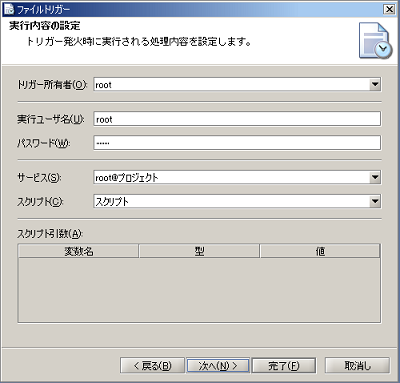 ログレベルの詳細については、「ログレベル」を参照してください。
ログレベルの詳細については、「ログレベル」を参照してください。
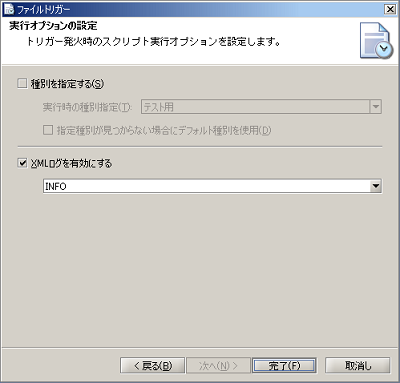 [いいえ]を選択した場合でも、あとでマイトリガーにて有効化することができます。
[いいえ]を選択した場合でも、あとでマイトリガーにて有効化することができます。
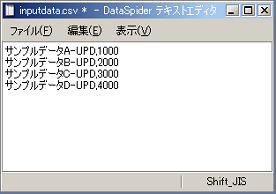

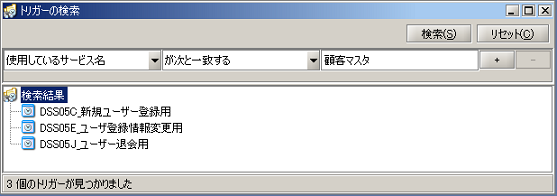
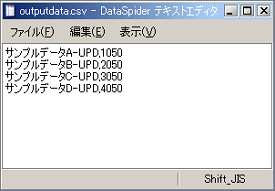 各種トリガーの設定の詳細については、「トリガー」を参照してください。
トリガーの作成方法の詳細については、「マイトリガー」を参照してください。
ScriptRunnerの詳細については、「ScriptRunner」を参照してください。
ScriptRunnerProxyの詳細については、「ScriptRunnerProxy」を参照してください。
詳細については、「デザイナ」を参照してください。
プロジェクト単位で出力することはできません。
生成方法の詳細については、「スクリプトメニュー」を参照してください。
バージョン比較レポートの内容については、「バージョン比較レポートの内容」を参照してください。
各種トリガーの設定の詳細については、「トリガー」を参照してください。
トリガーの作成方法の詳細については、「マイトリガー」を参照してください。
ScriptRunnerの詳細については、「ScriptRunner」を参照してください。
ScriptRunnerProxyの詳細については、「ScriptRunnerProxy」を参照してください。
詳細については、「デザイナ」を参照してください。
プロジェクト単位で出力することはできません。
生成方法の詳細については、「スクリプトメニュー」を参照してください。
バージョン比較レポートの内容については、「バージョン比較レポートの内容」を参照してください。