TO_INCODE関数
関数
TO_INCODE{KANJI[,STRING_TYPE[,EBCDIC]]}
対象文字列を指定された方法で入力文字コードに変換します。
外字およびユーザコードテーブルは使用できません。SHIFT-JIS、IBM漢字、UTF-8、UTF-16はすべての文字を変換できます。
TO_INCODE関数は、DataMagic Desktopグレードでは使用できません。使用した場合は実行時にエラーとなります。
パラメータ
KANJI
対象文字列の漢字コード種を指定します。
漢字コード種に設定する値を次に示します。
|
設定値 |
設定内容 |
|---|---|
|
S SJIS |
SHIFT-JISから入力文字コードへ変換する |
|
E EUC |
EUCから入力文字コードへ変換する |
|
8 UTF-8 |
UTF-8から入力文字コードへ変換する |
|
6 UTF-16 |
UTF-16の自機種のUnicodeバイトオーダから入力文字コードへ変換する (Windows, Linux … Little Endian)、 (UNIX, zLinux … Big Endian) |
|
UTF-16BE |
UTF-16のBig Endianから入力文字コードへ変換する |
|
UTF-16LE |
UTF-16のLittle Endianから入力文字コードへ変換する |
|
I IBM |
IBM漢字から入力文字コードへ変換する |
|
K KEIS |
KEISから入力文字コードへ変換する |
|
J JEF |
JEFから入力文字コードへ変換する |
|
N NEC |
NEC漢字から入力文字コードへ変換する |
|
Z JIS |
JISから入力文字コードへ変換する |
|
上記以外 |
エラー |
KANJIに指定した漢字コード種と、入力の漢字コード種が一致している場合も許容します(エラーにはなりません)。
STRING_TYPE
どの型として変換するかを指定します(省略可)。
省略すると、Mが設定されます。空文字は、省略とみなされずにエラーになります。
設定値の項目タイプと設定内容の関係を以下の表に示します。
|
設定値 |
設定内容 |
|---|---|
|
X |
キャラクタとして変換する |
|
M |
可変長文字として変換する |
|
N |
2バイト表示文字として変換する |
|
上記以外 |
エラー |
EBCDIC
対象文字列の1バイトコード種を指定します(省略可)。
省略すると、次に示す値が設定されます。
-
漢字コード種にEUC、SHIFT-JIS、UTF-8、UTF-16が指定されている場合は、ASCII が設定されます。
-
漢字コード種にIBM、KEIS、JEF、NEC、JISが指定されている場合は、EBCDIC カナが設定されます。
漢字コード種にオープン系(EUC、SHIFT-JIS、UTF-8、UTF-16)が指定されている場合は、ASCIIだけ設定できます。ASCII以外が設定されている場合も、ASCIIとして動作します。
ASCIIが指定できるのはEUC、SHIFT-JIS、UTF-8、UTF-16およびJISだけです。それ以外の漢字コード種で指定されている場合はエラーとなります。
|
設定値 |
設定内容 |
|---|---|
|
A EBCDIC KANA |
EBCDICカナで変換する |
|
B EBCDIC LOWERCASE |
EBCDIC英小文字で変換する |
|
C EBCDIC ASCII |
EBCDIC ASCIIで変換する |
|
D EBCDIC ASPEN |
EBCDIC ASPENで変換する |
|
E IBM STANDARD |
IBM英小文字で変換する |
|
F IBM STANDARD EXTENSION |
IBM英小文字拡張で変換する |
|
G NEC KANA |
NECカナで変換する |
|
H IBM KANA EXTENSION |
IBMカナ文字拡張で変換する |
|
Z ASCII |
ASCIIで変換する |
|
上記以外 |
エラー |
入出力の関係
入力データの項目タイプと出力データの項目タイプの関係を以下の表に示します。
|
入力 |
出力 |
|---|---|
|
X |
変換方法で指定された型 |
|
N |
変換方法で指定された型 |
|
M |
変換方法で指定された型 |
|
D |
エラー |
|
CSV文字列 |
M |
|
W |
エラー |
|
9(数字文字列) |
9(数字文字列)(無変換) |
|
I |
変換方法で指定された型 |
使用例
文字コードがUTF-8の入力ファイルで、先頭の項目がSHIFT-JIS、以降の項目がUTF-8のCSV入力データのうち、先頭の項目をTO_INCODE 関数でUTF-8 に変換します。
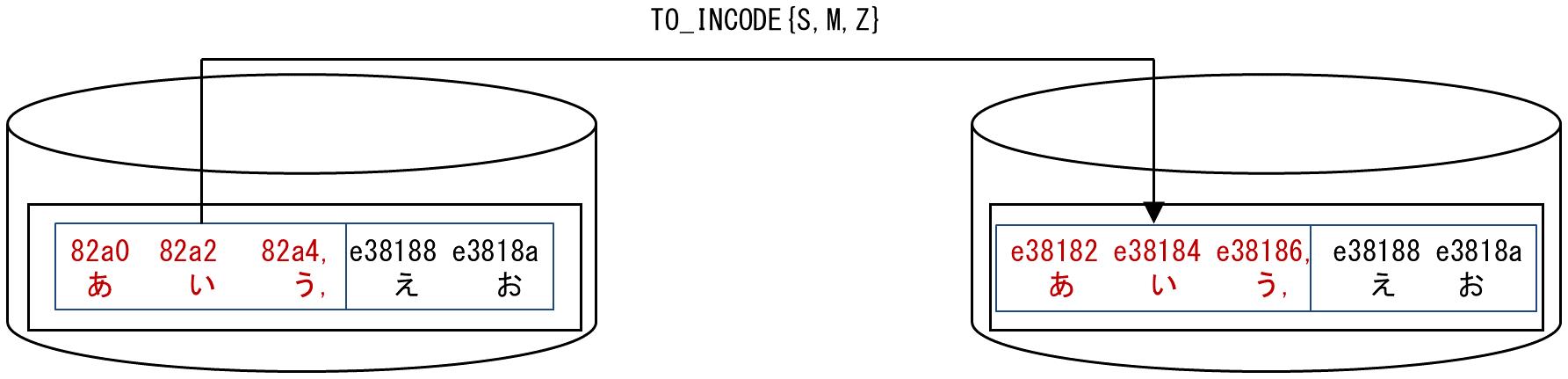
図A.53 使用例(TO_INCODE関数)