文字タイプの結合および分割時の注意
以下の漢字コード種を使用した変換について、文字タイプごとの変換結果とシフトコードの扱いを例を使用して説明します。シフトコードは漢字コード種によりバイト数が異なります。例はシフトコードを1バイトとして扱います。
-
入力側の漢字コード種: JEF、IBM漢字、KEIS、NEC漢字
-
出力側の漢字コード種: JEF、IBM漢字、KEIS、NEC漢字
= 備考 =
漢字コード種は、DataMagic Serverでだけ指定できます。DataMagic Desktopでは、漢字コード種は指定できません。
注意
文字タイプのコードを分割(抽出)する場合、漢字コードの途中から分割(抽出)するとエラーにならずにコードの途中から分割(抽出)します。そのため、分割(抽出)後のコードが文字化けする場合があります。
(1) Nタイプの分割
Nタイプのデータを抽出し、Mタイプに変換する例です。
データの抽出情報の設定は、マッピング情報設定画面の出力データの「出力情報設定」で行います。
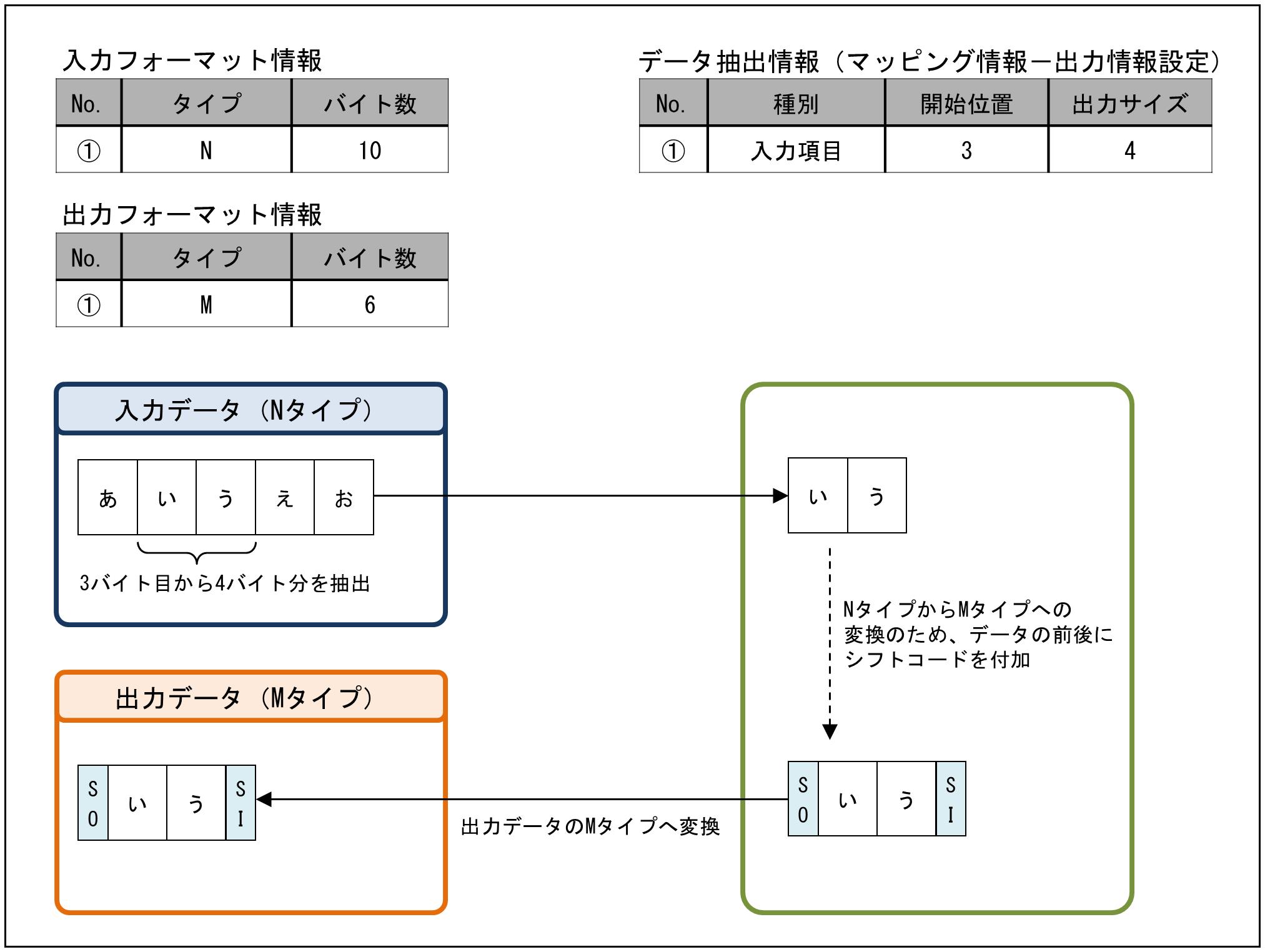
図9.18 Nタイプの分割
(2) Nタイプの分割と結合
Nタイプのデータを抽出し、Mタイプに変換する例です。
データの抽出情報の設定は、マッピング情報設定画面の出力データの「出力情報設定」で行います。
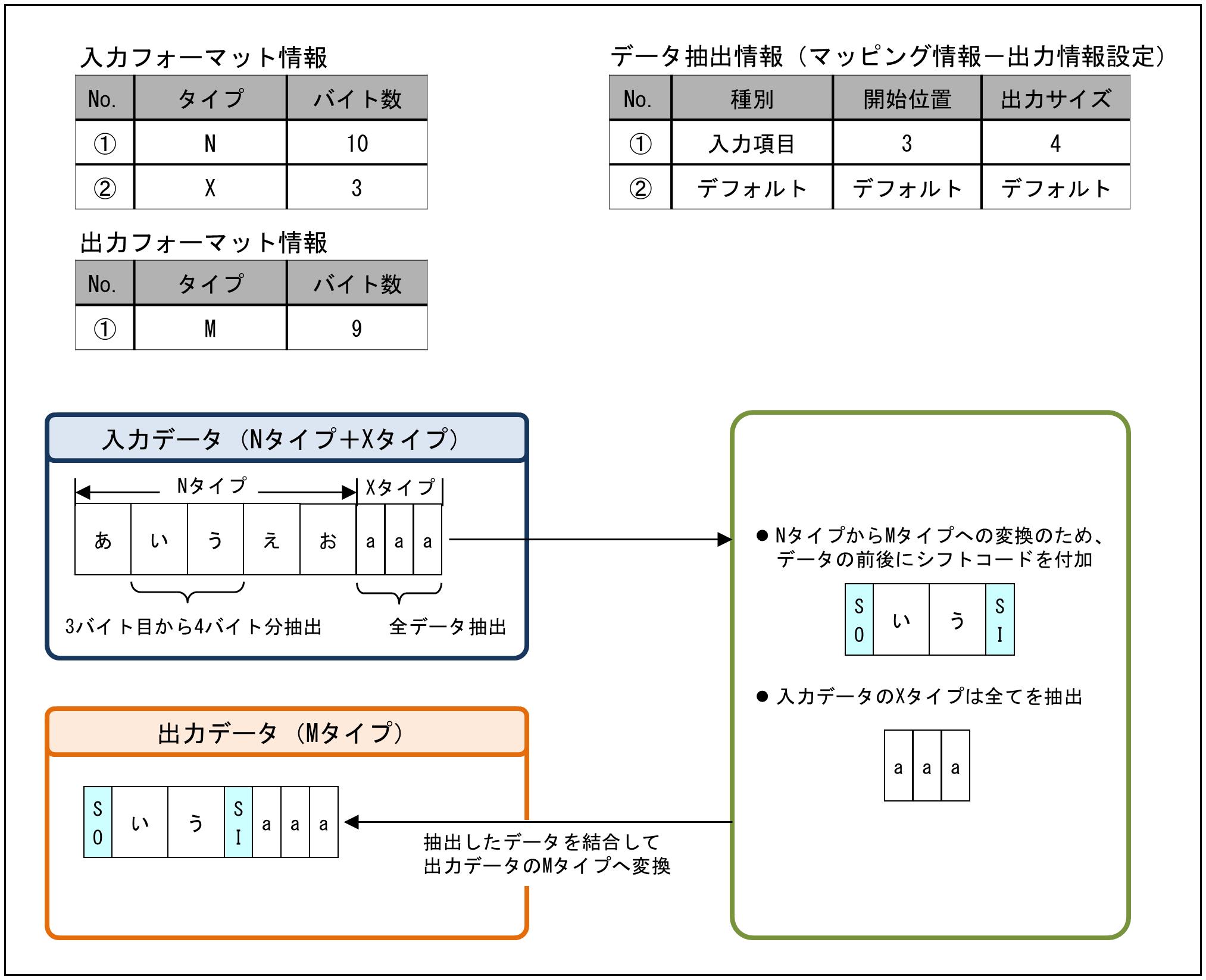
図9.19 Nタイプの分割と結合
(3) Mタイプの分割と結合
Mタイプのデータを抽出し、Mタイプに変換する例です。
データの抽出情報の設定は、マッピング情報設定画面の出力データの「出力情報設定」で行います。
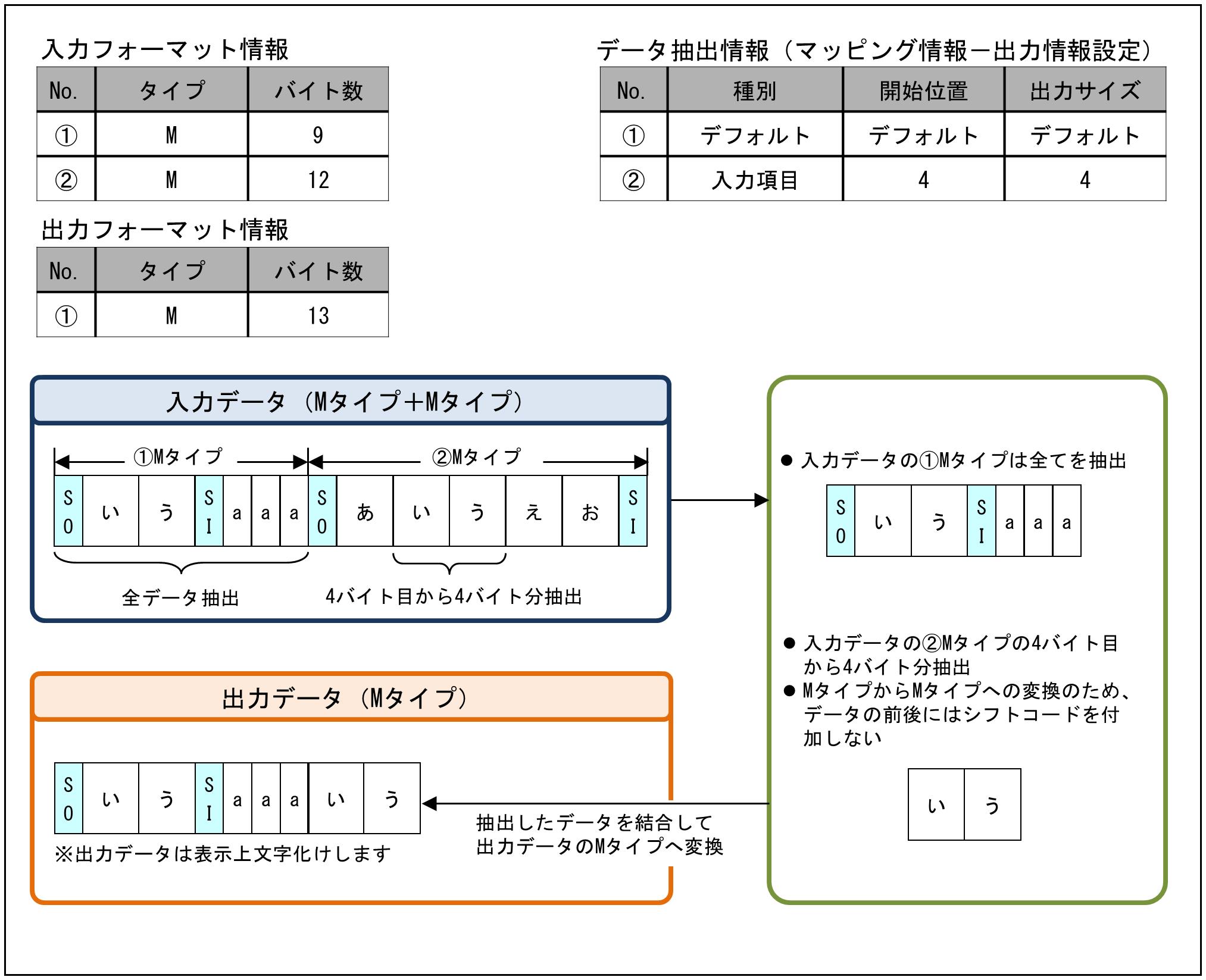
図9.20 Mタイプの分割と結合
(4) Mタイプの結合
Mタイプのデータを抽出し、Mタイプに変換する例です。
データの抽出情報の設定は、マッピング情報設定画面の出力データの「出力情報設定」で行います。
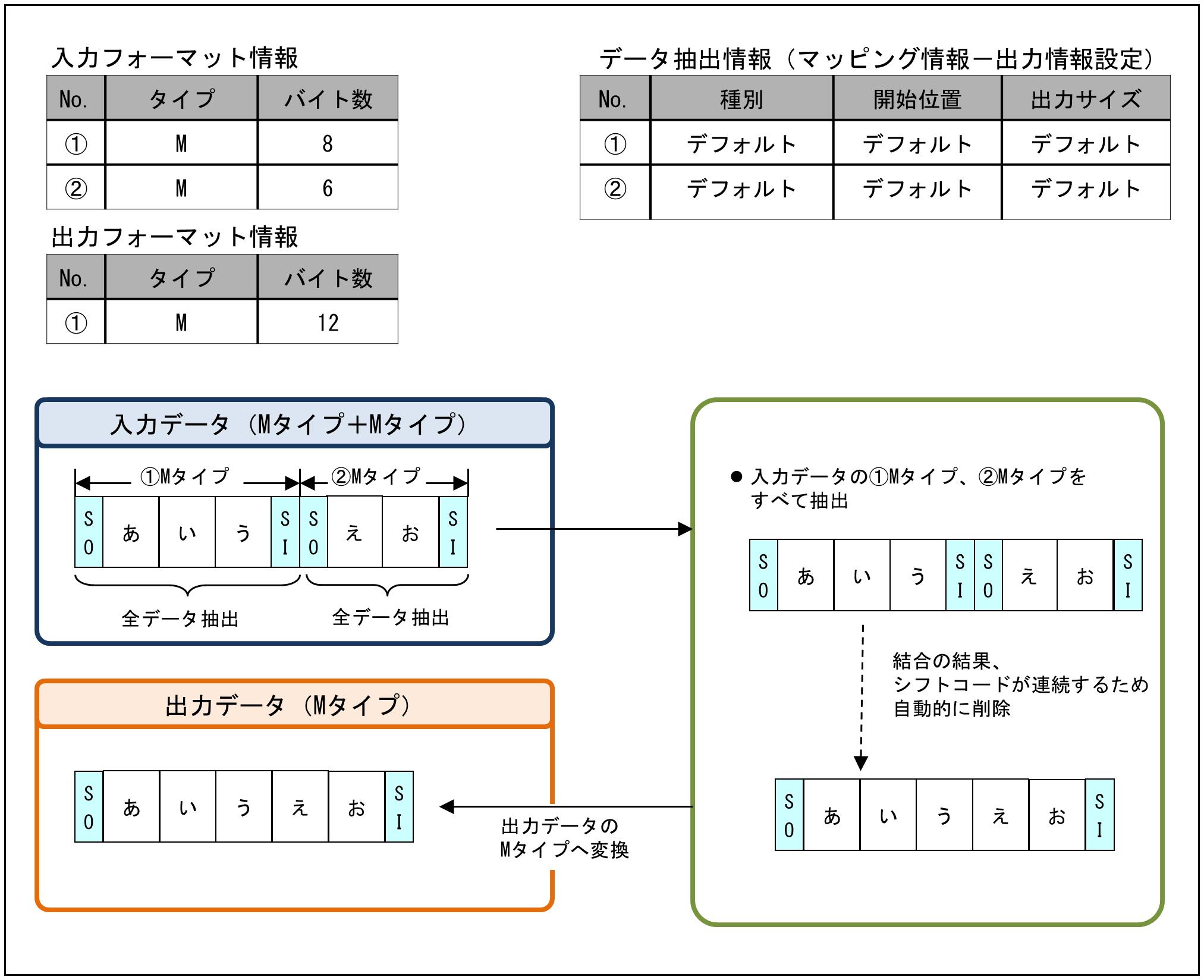
図9.21 Mタイプの結合