入力側でのXMLレコード単位の扱い
入力ファイルがXMLの場合、入力ファイルの設定項目「XMLレコード単位」の値に基づいて「レコード」に区切られます。
以下のスキーマファイル、XML情報、入力ファイルを例に、「XMLレコード単位」の設定値ごとに詳細を説明します。スキーマファイルの内容モデルはchoiceを使用しています。

図4.10 スキーマファイル
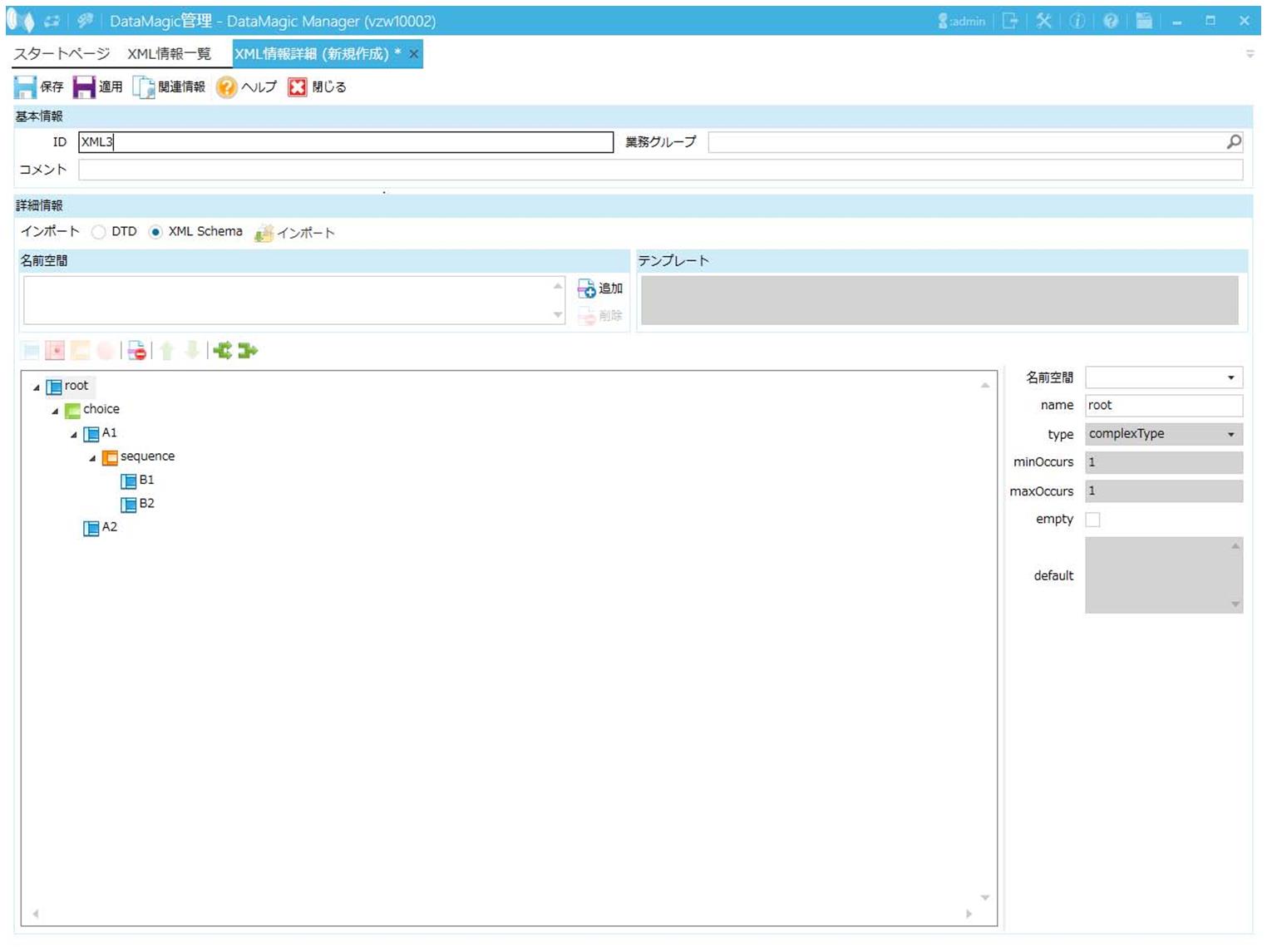
画面4.8 XML情報ツリー

図4.11 入力ファイル
(1) 「XMLレコード単位」が"1"の場合
1レコードとしてみなす階層はルート要素であるため、1レコードとして認識する要素はrootとなります。ルート要素は1ファイルに対して1つしか存在しないため、入力ファイルの全データが1レコードとして扱われます。従ってこの例の場合、data1~data7が1レコードとして処理されます。
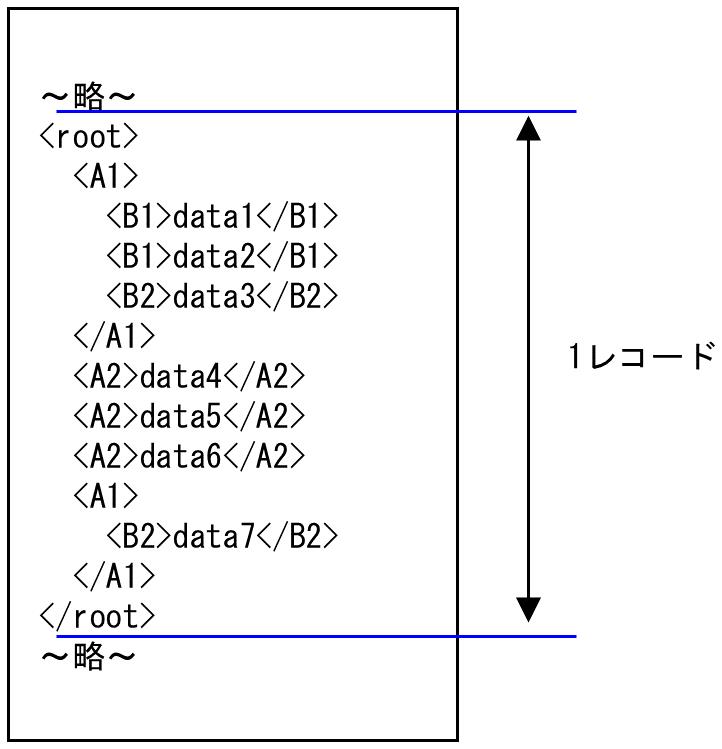
図4.12 1レコード
(2) 「XMLレコード単位」が"2"の場合
1レコードとしてみなす階層はルート要素の1階層下であるため、1レコードとして認識する要素はA1~A2となります。1レコードとみなす階層の中で上から順に処理していき、同じ名前の要素が出現したらレコードが切り替わります。この例では、次のようなレコードの区切り方となります。
1. 上から順に処理していき、<A2>data5</A2>の時点で2回目のA2が出現するため、data1からdata4までが1レコード目の入力データとなり、data5からが2レコード目として処理されます。

図4.13 1レコード目
2. <A2>data6</A2>の時点で3回目のA2が出現するため、data5が2レコード目の入力データとなり、data6からが3レコード目として処理されます。
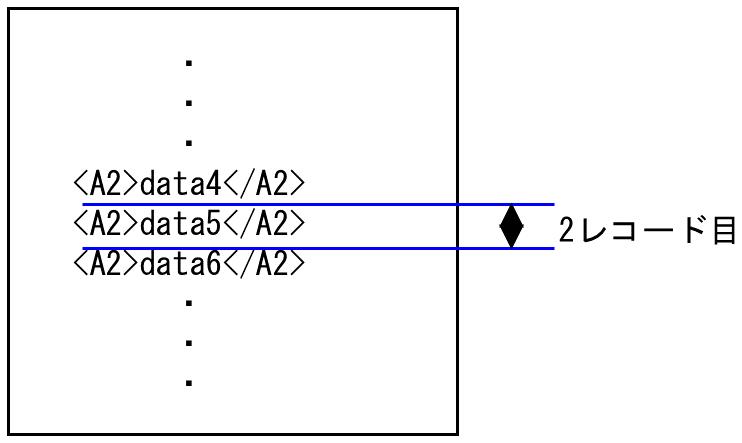
図4.14 2レコード目
3. 3レコード目の中には同じ名前の要素が複数出現しないため、そのまま最後まで処理され、data6からdata7が3レコード目の入力データとなります。
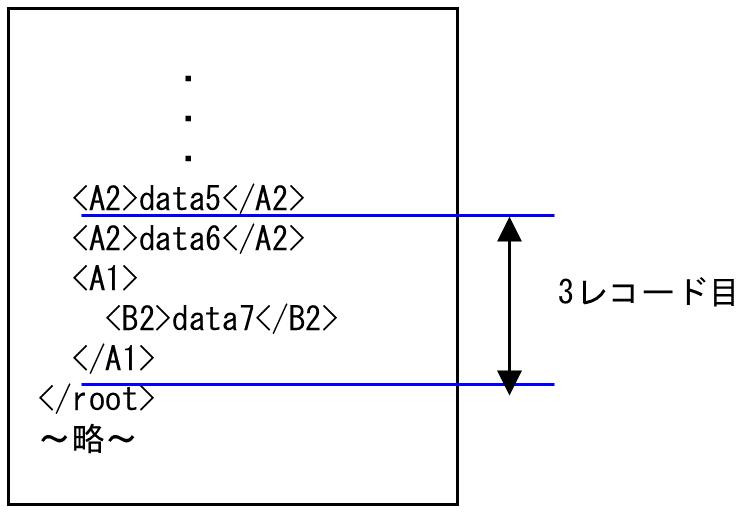
図4.15 3レコード目
(3) 「XMLレコード単位」が"3"の場合
1レコードとしてみなす階層はルート要素の2階層下であるため、1レコードとして認識する要素はB1~B2となります。1レコードとみなす階層の中で上から順に処理していき、同じ名前の要素が出現したらレコードが切り替わります。この例では、以下のようなレコードの区切り方となります。
1. 上から順に処理していき、<B1>data2</B1>の時点で2回目のB1が出現するため、data1が1レコード目の入力データとなり、data2からが2レコード目として処理されます。
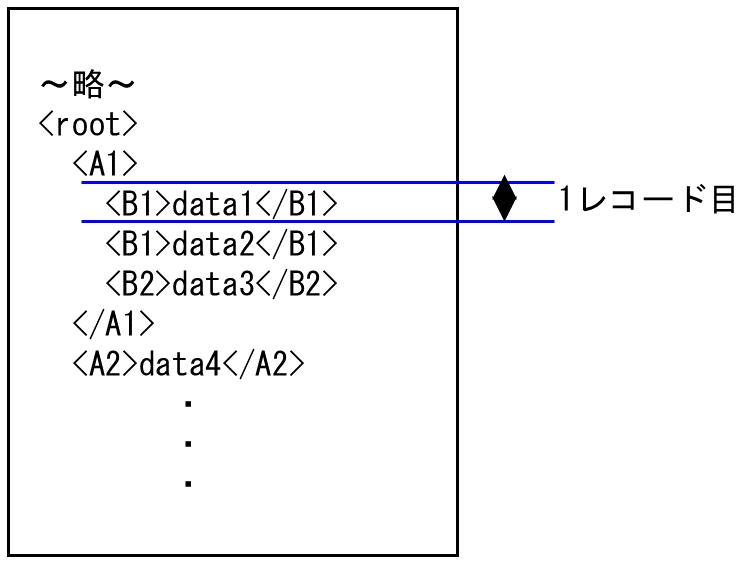
図4.16 1レコード目
2. 2レコード目の中には、同じ名前の要素が複数出現しないため、そのまま最後まで処理され、data2からdata3が2レコード目の入力データとなります。
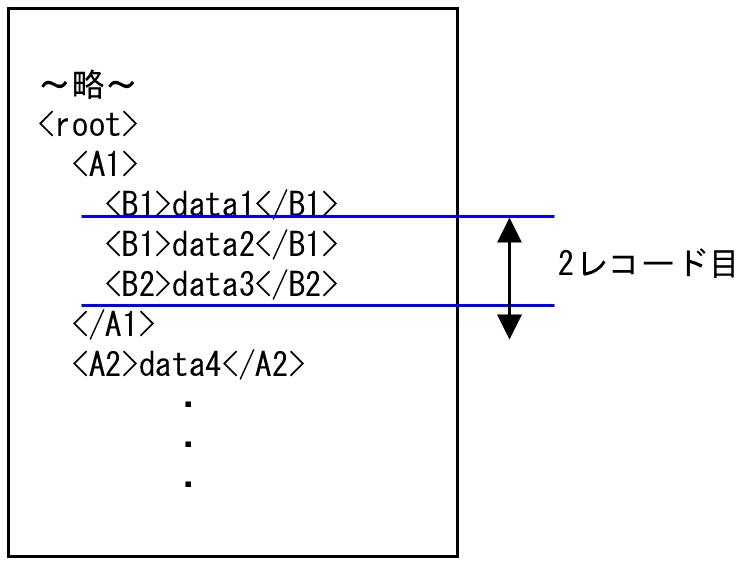
図4.17 2レコード目
3. <A2>data4</A2>が出現した時点で、ルート直下の要素が複数存在すると判断され、XMLレコード単位整合性エラーとなります。
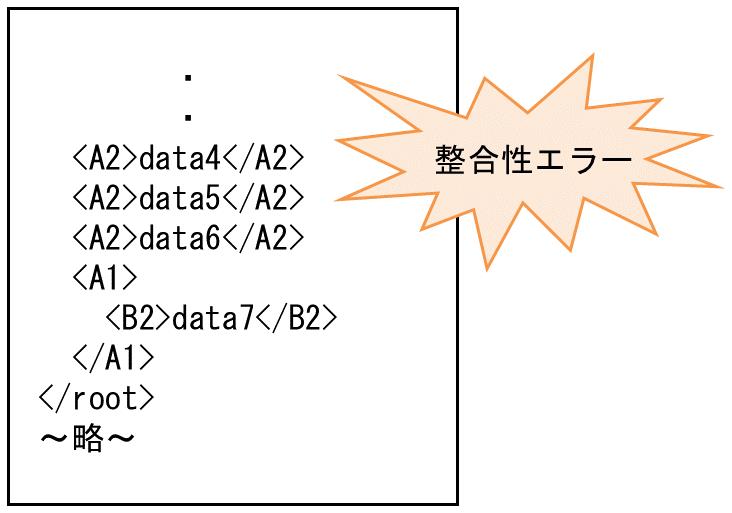
図4.18 レコード判定不能
「XMLレコード単位」が"3"の指定でエラーにならない入力ファイルは、以下のように1階層下の要素が1つ(この例では<A1>のみ)でなければなりません。
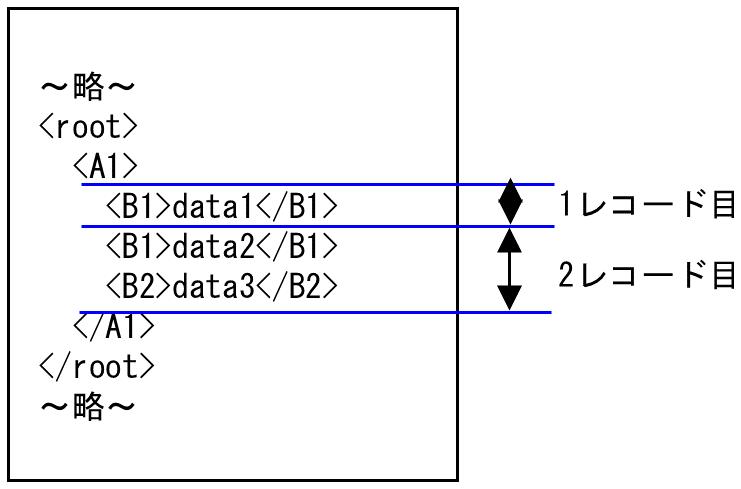
図4.19 入力ファイル
「XMLレコード単位」が"3"で、XMLスキーマファイルの内容モデルがsequenceの場合は注意が必要です。以下のスキーマファイル、XML情報、入力ファイルを例に説明します。

図4.20 スキーマファイル
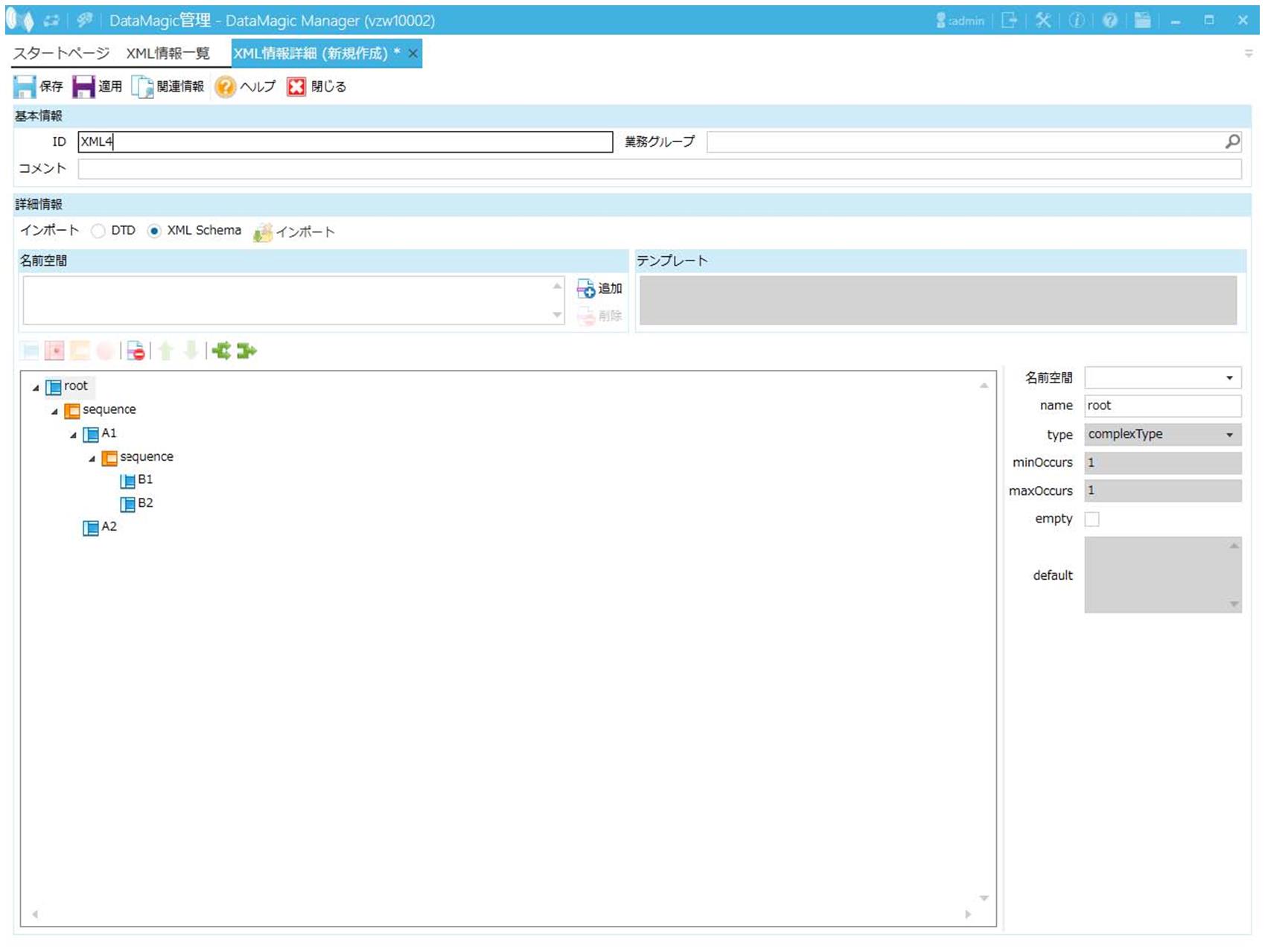
画面4.9 XML情報ツリー

図4.21 入力ファイル1
この例のスキーマファイルでは、ルート直下の要素が2つ定義されており(<A1>と<A2>)、内容モデルがsequenceのためルート直下の要素は必ず<A1>の次に<A2>が出現しなくてはなりません(「内容モデル」参照)。
この例の入力ファイルを見ると、ルート直下の要素は<A1>の次に<A2>が存在しているので、XMLスキーマとの整合性に問題はありません。
しかし、「XMLレコード単位」が"3"に設定されていると、ルート要素から2階層下の要素を1レコードとして扱うため、1階層下の要素が複数出現(この例では<A2>が出現)した時点で整合性エラーとなってしまいます。
したがって、「XMLレコード単位」が"3"で、XMLスキーマに内容モデルsequenceを使用する場合は、必ずXMLスキーマのルート直下の要素を1つにする必要があります。
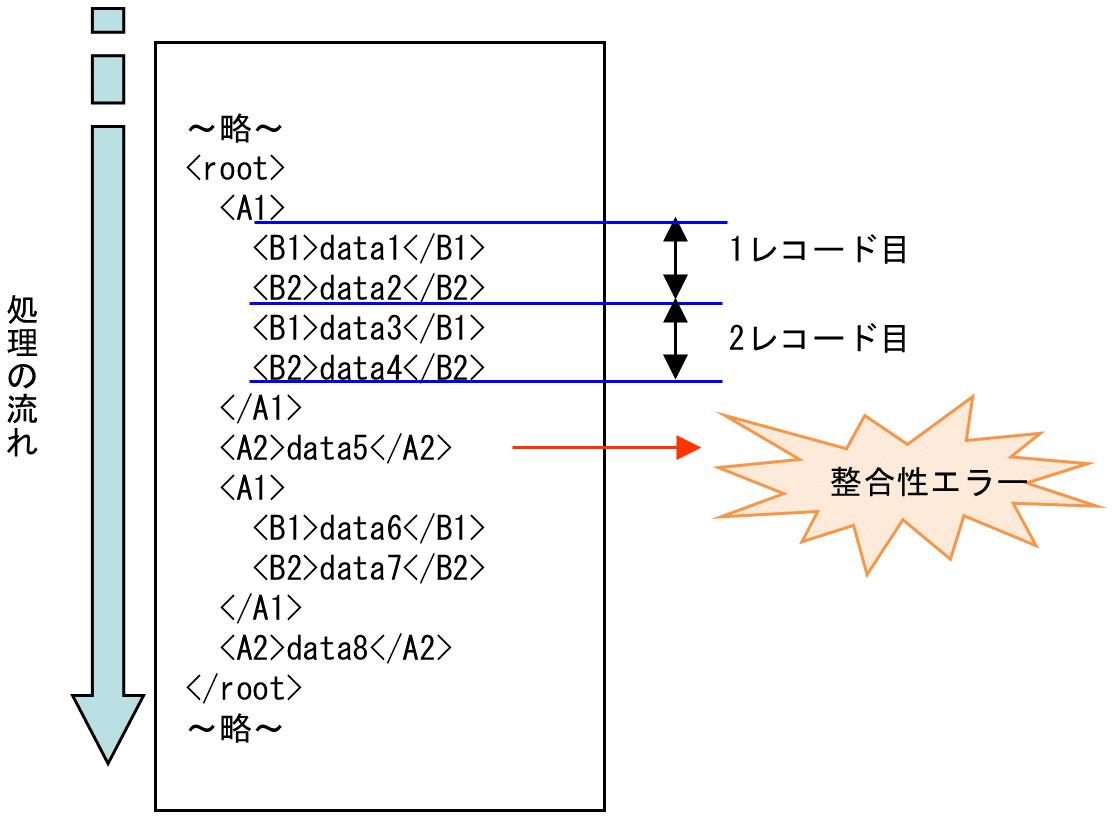
図4.22 入力ファイル1
(4) 「XMLレコード単位」が"要素"の場合
「XMLレコード単位」が"要素"の場合、条件に設定した要素を基点に1レコードとして扱います。
以下のスキーマファイル、XML情報、入力ファイルを例に説明します。スキーマファイルの内容モデルはsequenceを使用しています。

図4.23 スキーマファイル
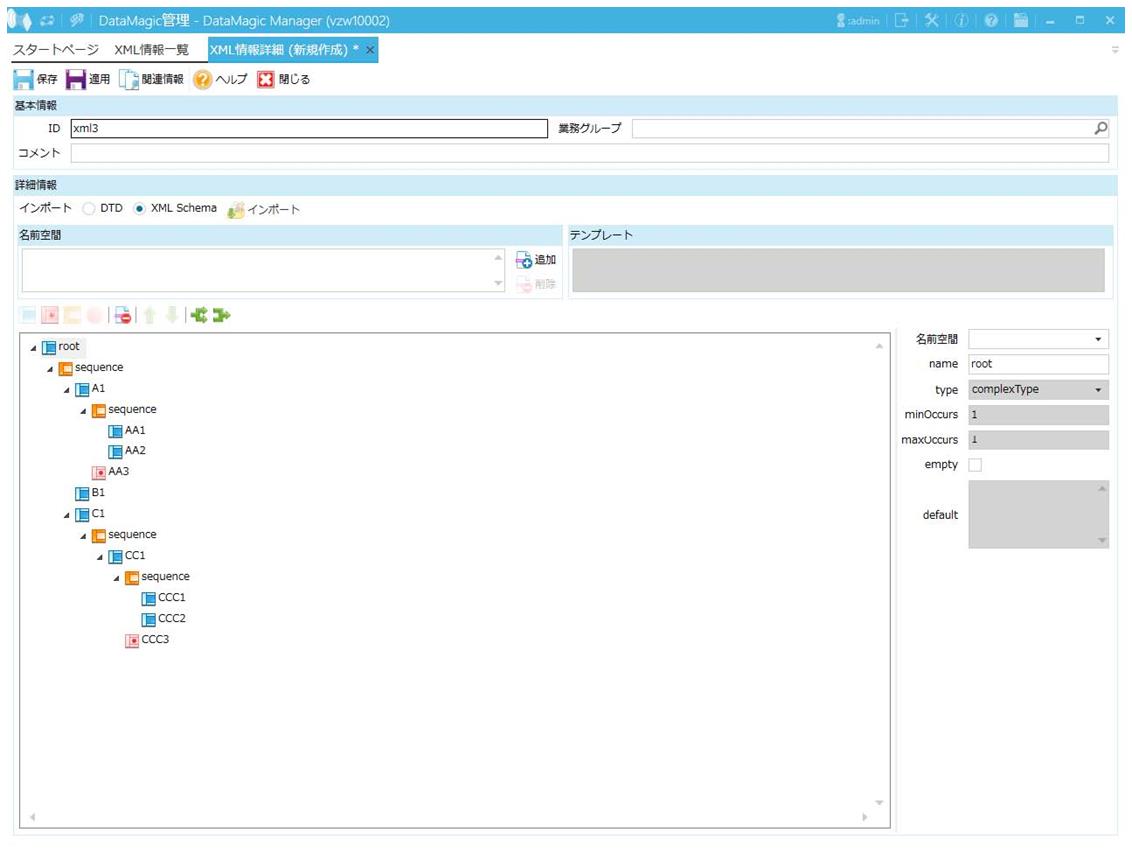
画面4.10 XML情報ツリー

図4.24 入力ファイル
抽出条件に設定した要素を基点に1 レコードとして認識します。この例では、「要素C1」に抽出条件を設定しているため、次のようなレコードの区切り方となります。
1. 上から順に処理していき、最初の<C1>から1レコード目として処理します。<A1 AA3="a2">の時点で<C1>が終了となります。このため、"c1"のdata4、data5と"c2"はdata6、data7が1レコード目の入力データとなります。
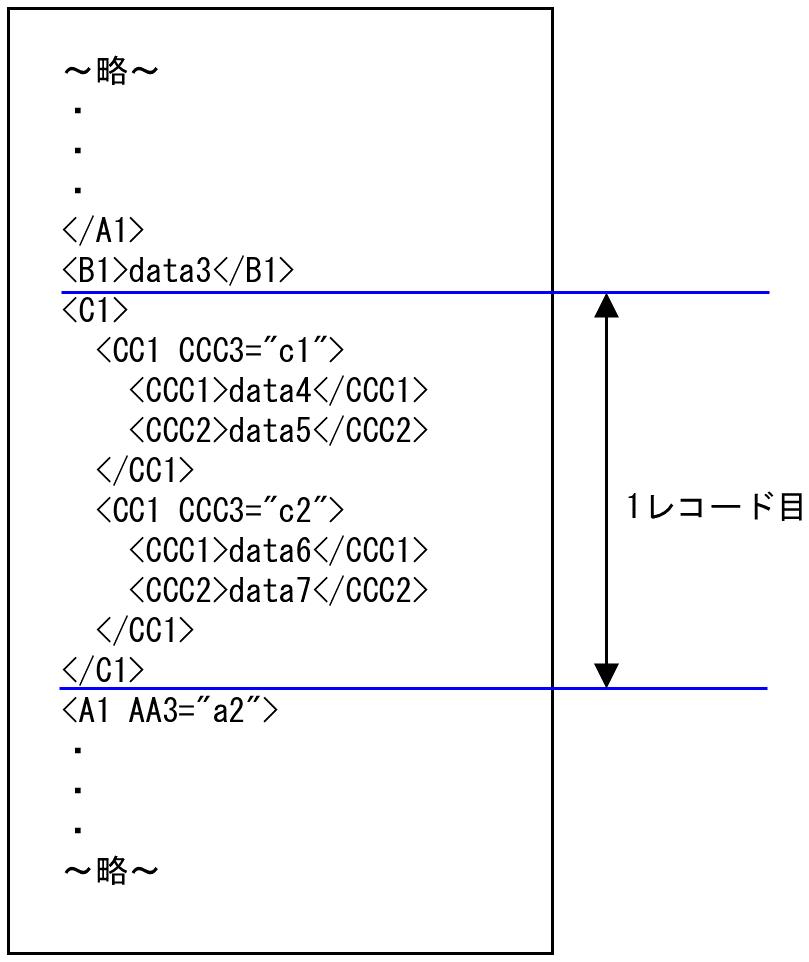
図4.25 1レコード目
2. 次に<C1>が出現したところから、2レコード目の入力データとなります。2番目の<C1>の中で<CC1 CCC3="c3">から処理し、</root>の時点で<C1>が終了となります。このため、"c3"のdata10、data11と"c4"のdata12、data13が2レコード目の入力データとなります。
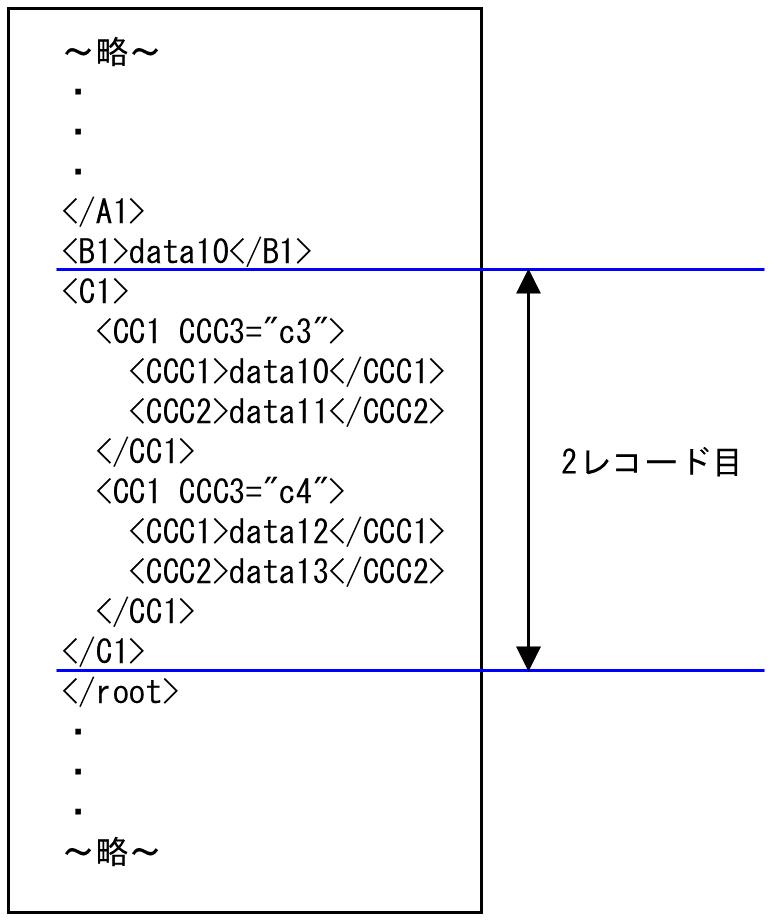
図4.26 2レコード目
次に、「要素CC1」に抽出条件を設定した場合のレコードの区切り方について説明します。
1. 上から順に処理をしていき、<CC1 CCC3="c1">から1レコード目として処理し、<CC1 CCC3="c2">の時点で2回目の<CC1>が出現するため、data4、data5を1レコード目の入力データとして扱います。次の<CC1 CCC3="c2">から2レコード目として処理されます。
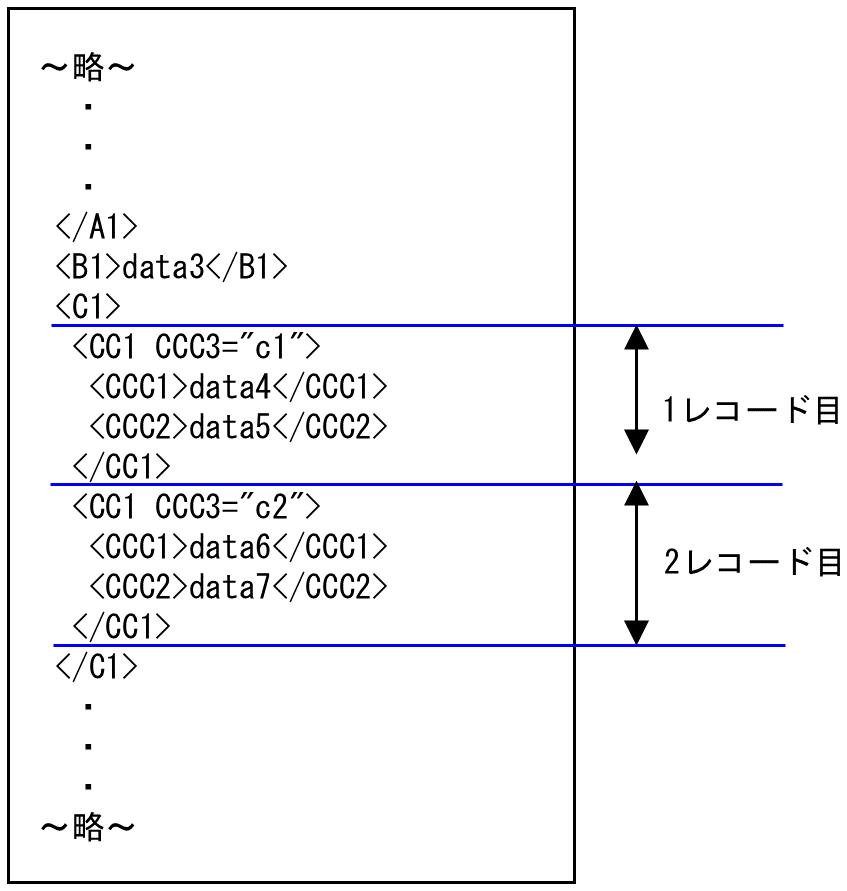
図4.27 1レコード目と2レコード目
2. 次に、<CC1 CCC3="c3">の中を処理していきます。<CC1 CCC3="c3">から1レコード目として処理し、<CC1 CCC3="c4">の時点で2回目の<CC1>が出現するため、data10、data11を1レコードとして扱います。入力データの3レコード目となります。次の<CC1 CCC3="c4">から入力データの4レコード目として処理されます。
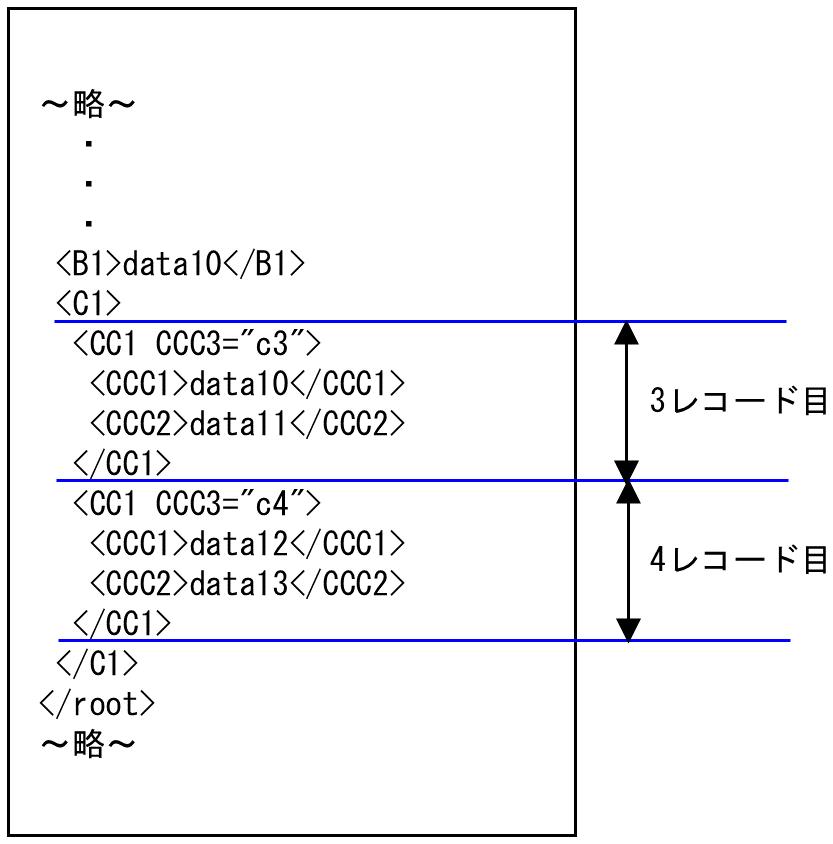
図4.28 3レコード目と4レコード目