XML形式ファイルからXML形式ファイルへの変換
XML形式ファイルからXML形式ファイルへの変換について、以下の入力ファイル、スキーマファイルを例に、「XMLレコード単位」の設定値ごとに説明します。

図4.57 入力ファイル

図4.58 スキーマファイル(内容モデルsequence)
()内は出力用のスキーマファイルの要素名になります。
(1) 親要素同士をマッピングした場合
同じ形式の階層構造をもつ、XML形式ファイル同士の変換では、親要素同士で関係線を引けます。マッピング情報を以下のとおりに親要素同士で関係線を結んだ場合について説明します。

画面4.27 マッピング情報
a) 入出力ファイルの「XMLレコード単位」が"1"または"2"の場合
親要素同士でマッピングした場合、入力ファイルのデータをすべて処理します。この場合、「XMLレコード単位」の違いはありません。
ただし、属性項目がある場合、「XMLレコード単位」で設定した要素よりも上位の属性項目のデータは処理されませんので注意してください(「XML変換の制限事項」参照)。
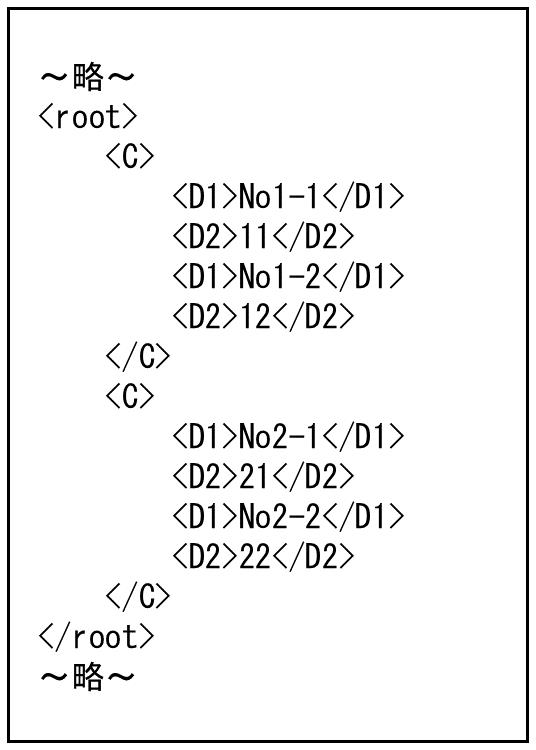
図4.59 出力ファイル
b) 入出力ファイルの「XMLレコード単位」が"3"の場合
1レコードとしてみなす階層はルート要素の2階層下になりますが、ルート要素から1階層下の要素が複数存在しているため、2つ目の要素<A>を読み込んだ際にXMLレコード単位整合性エラーになります。
c) 入力ファイルの「XMLレコード単位」が"要素"で出力ファイルの「XMLレコード単位」が"任意"の場合
要素Aと要素Cの内容モデルを繰り返しの基点に設定した場合
入力側は「抽出条件の追加」画面で要素Aを抽出条件に設定します。
出力側は要素Cを繰り返しの基点に設定します。
この設定で親要素同士でマッピングした場合、マッピング画面は以下のようになります。

画面4.28 マッピング情報
この場合、入力側は<A>~</A>を出力側は要素Cを1レコードとして扱うため、<C>~</C>が入力レコードの数だけ繰り返し出力されます。
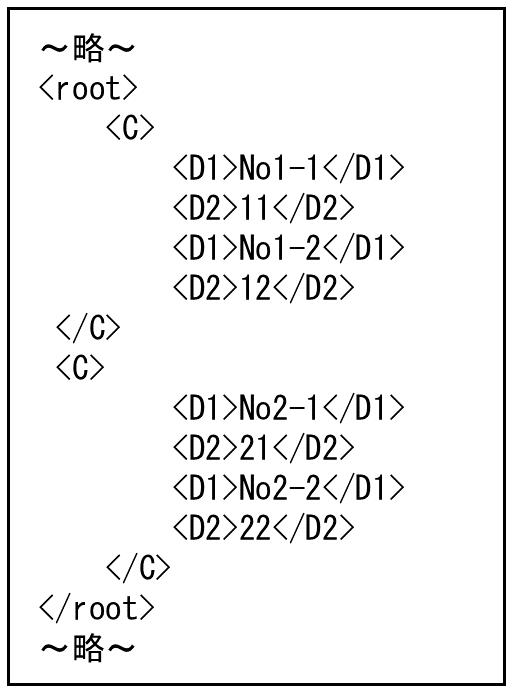
図4.60 出力ファイル
要素Aと要素Cの内容モデルを繰り返しの基点に設定した場合
入力側は「抽出条件の追加」画面で要素Aを抽出条件に設定します。
出力側は要素Cの内容モデル(sequence)を繰り返しの基点に設定します。
この設定で親要素同士でマッピングした場合、マッピング画面は以下のようになります。

画面4.29 マッピング情報
この場合、入力側は<A>~</A>を1レコードとして処理します。出力側は要素 D1、D2を1レコードとして扱うため、<D1>~</D1>、<D2>~</D2>が入力レコードの数だけ繰り返し出力されます。

図4.61 出力ファイル
(2) 子要素同士をマッピングした場合
マッピング情報を以下のとおりに子要素同士で関係線を結んだ場合について説明します。入力ファイルは前回と同じファイルを使用します。

画面4.30 マッピング情報
a) 入出力ファイルの「XMLレコード単位」が"1"の場合
<root>と</root>の中のデータを1レコードとして扱います。今回の例では、入力データのうち、関係線が結ばれている最初の<B1>と<B2>の値のみが1レコードとして処理されます。次の<B1>と<B2>はマッピングされていない項目のため、データは切り捨てられます。
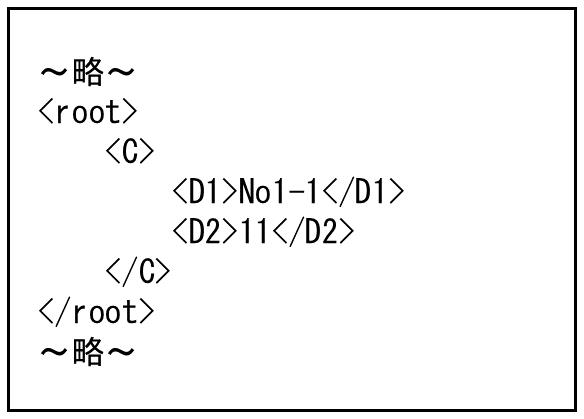
図4.62 出力ファイル
b) 入出力ファイルの「XMLレコード単位」が"2"の場合
ルート要素<root>から1階層下の要素を1レコードとして扱います。今回の例では、1階層下の1つ目の要素<A>のデータのうち、関係線が結ばれている最初の<B1>と<B2>の値が出力項目に格納され、1レコード目として処理されます。次の<B1>と<B2>はマッピングされていない項目ため、データが切り捨てられます。同様に2つ目の要素<A>が2レコード目として処理されます。
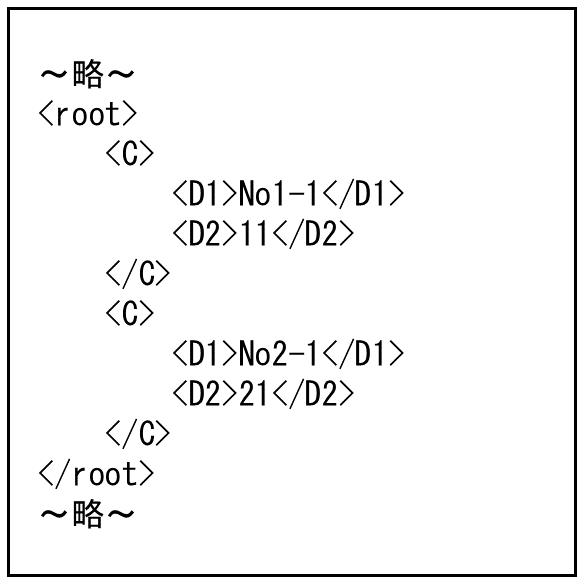
図4.63 出力ファイル
c) 入出力ファイルの「XMLレコード単位」が"3"の場合
ルート要素<root>から2階層下の要素を1レコードとして扱います。
しかし、ルート要素から1階層下の要素が複数存在しているため、2つ目の要素<A>を読み込んだ際にXMLレコード単位整合性エラーになります。
d) 入力ファイルの「XMLレコード単位」が"要素"で、出力ファイルの「XMLレコード単位」が"任意"の場合
要素Aと要素Cを繰り返しの基点に設定した場合
入力側は「抽出条件の追加」画面で要素Aを抽出条件に設定します。
出力側は要素Cを繰り返しの基点に設定します。
この設定で子要素同士でマッピングした場合、マッピング画面は以下のようになります。

画面4.31 マッピング情報
この場合、入力側は<A>~</A>を出力側は<C>~</C>を1レコードとして扱います。入力データのうち、関係線が結ばれている最初の<B1>と<B2>の値のみが出力項目に格納され、1レコード目として処理されます。次の<B1>と<B2>はマッピングされていない項目のため、データが切り捨てられます。同様に2つ目の要素<A>が2レコード目として処理されます。

図4.64 出力ファイル
要素Aと要素Cの内容モデルを繰り返しの基点に設定した場合
入力側は「抽出条件の追加」画面で要素Aを抽出条件に設定します。
出力側は要素Cの内容モデル(sequence)を繰り返しの基点に設定します。
この設定で子要素同士でマッピングした場合、マッピング画面は以下のようになります。

画面4.32 マッピング情報
この場合、入力側は<A>~</A>を1レコードとして扱います。出力側は要素D1、D2を1レコードとして扱うため、<D1>~</D1>、<D2>~</D2>が入力レコードの数だけ繰り返し出力されます。入力データのうち、関係線が結ばれている最初の<B1>と<B2>の値のみが出力項目に格納され、1レコード目として処理されます。次の<B1>と<B2>はマッピングされていない項目のため、データが切り捨てられます。同様に2つ目の要素<A>が2レコード目として処理されます。
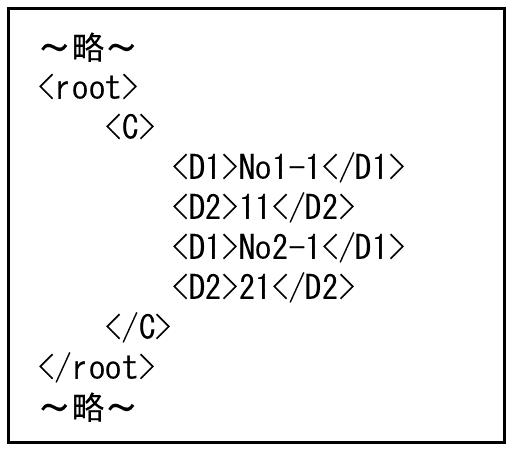
図4.65 出力ファイル