非互換
HULFT-DataMagic Ver.1の製品で旧バージョンより変更された機能や一部制限を受ける機能一覧です。
アイコンについて
-
対象となるバージョン以降と、それ未満のバージョンの間に非互換が生じていることを意味します。たとえば以下のアイコンが指定されている場合は、HULFT データ変換Pro/StandardとHULFT-DataMagic Ver.1.0.0以降の間に非互換があることを表します。
Magic
1.0.0
-
以下のアイコンが指定されている場合は、HULFT データ変換 Ver.6.5.0未満とHULFT データ変換 Ver.6.5.0以降の間に非互換があることを表します。
Pro
6.5.0
(1) ファイルフォーマットの変更
|
|
固定フォーマット情報ファイル、マルチフォーマット情報ファイル、パラメータファイルのフォーマットが変更されました。
固定フォーマット情報ファイル、マルチフォーマット情報ファイルについては、バージョンアップインストールを行うか、またはデータ加工管理画面からインポートを行うことでコンバートが可能です。パラメータファイルについては、データ加工管理画面に読み込んで保存することでVer.6形式にコンバートされます。
(2) エラーコードとメッセージの追加、変更、削除
|
|
エラーコードおよびメッセージが追加、変更、削除されています。詳細については「HULFT データ変換Pro/Standard for UNIX/Linux 付録1 エラーコード」を参照してください。
(3) パス名最大長の変更
|
|
パラメータファイルおよび環境ファイルに指定できるパスごとの長さが200バイトに変更になりました。Ver.5のパラメータファイルおよび環境ファイルで、201バイト以上のパス名を指定していた場合、画面に読み込まれた時点で200バイトにカットされます。また、環境ファイルは基本的にはVer.5のものをコンバートする必要はありませんが、パス名に201バイト以上の指定がある環境ファイルでデータ加工を行うと、エラーになります。
(4) 後スペースカットの動作変更
|
|
環境ファイルの「文字データの後スペースの扱い」を"カットする"に設定した場合、Ver.5では半角および全角スペースともにカットされていましたが、Ver.6では入力項目のタイプによって動作が変わります。
表B.1 カットされるスペース
|
入力タイプ |
Ver.5 |
Ver.6 |
|---|---|---|
|
X |
全角、半角 |
半角のみ |
|
M |
全角、半角 |
全角、半角 |
|
N |
全角、半角 |
全角のみ |
(5) ゾーン符号部の指定方法変更
|
|
データをSタイプに変換する際の符号部をフォーマット情報で指定するようになりました。これにともない、Ver.5の環境ファイルの出力ファイル情報(/OUTFILE)にSタイプフォーマット(TYPES)が指定されていても、その値は無視されます。
(6) 入力ファイルコード種の指定方法変更
|
|
入力ファイルのコード種を、HULFT データ変換Standardの場合はhulenv.confで、HULFT データ変換Proの場合はパラメータファイルで指定するようになりました。これにともない、Ver.5の環境ファイルの入力ファイル情報(/INFILE)に漢字コード(INCODE)が指定されていても、その値は無視されます。
(7) HULFT Managerによる設定ファイルの更新
|
|
固定フォーマット情報ファイル、マルチフォーマット情報ファイル、パラメータファイル、および環境ファイルをデータ加工管理画面から更新します。コマンドユーティリティはありません。これにより、HULFT Managerが必須となります。詳細については、「留意点」を参照してください。
(8) Mタイプ→Xタイプ変換およびMタイプ→Nタイプ変換の動作変更
|
|
MタイプからXタイプに変換する際、Mタイプのデータ内に全角文字が存在した場合は変換エラーとなります。また、MタイプからNタイプに変換する際、Mタイプのデータ内に半角文字が存在した場合は変換エラーとなります。
(9) ファイルフォーマットの変更
|
|
データ形式情報ファイル(固定フォーマット、マルチフォーマット、CSV、XML)とパラメータファイルのフォーマットを変更しました。
データ形式情報ファイルについては、バージョンアップインストールを行うことで自動でコンバート処理が行われます。
パラメータファイルについては、データ加工管理画面に読み込んで保存することでVer.6.5形式にコンバートされますが、Ver.6.1形式でも実行可能です。
(10) エラーコードとメッセージの追加、変更、削除
|
|
エラーコードの枝番を変更しました。
メッセージを日本語に変更しました。
一部のエラーコードに詳細メッセージを追加しました。
(11) 固定フォーマットへの変換で、マッピングしていない項目の扱いの変更
|
|
固定フォーマットの変換で、マッピングしていない項目があった場合、その項目は出力されませんでした。
マッピングしていない項目は、以下のように、その項目タイプの初期値を出力します。
- 9タイプ
-
: 0でパディングします
- X、Mタイプ
-
: 半角スペースでパディングします
- Nタイプ
-
: 全角スペースでパディングします
- B、F、S、Pタイプ
-
: 0を出力します
- Iタイプ
-
: 0x00でパディングします
(12) 自機種のコード種の指定方法の変更
|
|
自機種の漢字コード種の指定方法を、「漢字コード種(knjcode)」から「データ変換Pro/Standardの漢字コード種(edknjcode)」に変更しました。
「データ変換Pro/Standardの漢字コード種(edknjcode)」はVer.6.5から新規追加した項目で、管理画面から入力できません。変更する場合は、エディタを起動して直接システム動作環境設定ファイルを編集してください。
(13) 機種に依存する文字のコード変換
|
UTF-8またはUTF-16にコード変換する場合、機種に依存する文字は、すべてWindowsに依存する文字に変換していましたが、UNIXに依存する文字コードかWindowsに依存する文字コードかを選べるように改善しました。また、接続先の機種で使用されている文字コードへの変換も可能です。
(14) 半角スペースのコード変換
|
EUCまたはSHIFT-JISからUTF-16へNタイプのコード変換を行う場合、2個続きの半角スペースは2個続きの半角スペースに変換していましたが、1つの全角スペースに変換するようになりました。
(15) KEIS全角スペースのデフォルト値
|
KEISにコード変換する場合、KEISの全角スペースは0x4040に変換されていましたが、デフォルト設定で0xA1A1に変換するように変更しました。今までどおり0x4040に変換する場合には、パラメータファイルの出力ファイル設定で「KEIS全角スペースモード」を"4040"に設定する必要があります。
(16) マルチフォーマットを使用する場合の抽出条件の変更
|
|
従来の環境で作成したマルチフォーマット情報を含むパラメータファイルを使用する場合、マッピング編集において以下のような制限があります。
入力側で使用している場合は、以下のように条件により動作が異なります。
- 抽出条件でキー値の指定あり
-
登録されているフォーマットを使用している場合は編集可能ですが、項目追加を行っている場合は再度マッピングを行う必要があります。
- キー値の指定なし(AND条件を20指定済みでない)
-
登録されているフォーマットを使用している場合は使用しているフォーマットを選択するダイアログが表示されますが、項目追加を行っている場合は再度マッピングを行う必要があります。
- キー値の指定なし(AND条件を20指定済み)
-
再度抽出条件を設定する必要があります。
出力側で使用している場合は、適用するフォーマットを選択するダイアログが表示されますので、該当するフォーマットを選択します。
登録されているフォーマットを使用している場合は編集可能ですが、項目追加を行っている場合は再度マッピングを行う必要があります。
なお、データ加工実行時における制限はありません。
(17) 外字テーブル中の1バイト文字の変換
|
外字テーブルの出力コードに1バイトの文字が登録されていた場合、従来は前に0x00をつけて2バイトに変換していましたが、1バイト文字に変換されるようになりました。
(18) 出力がUTF-16の場合の外字テーブル中の3バイト文字の変換
|
出力側がUTF-16で、外字テーブルの出力コードに3バイト文字が登録されていた場合、外字テーブルから上位2バイトを出力し、3バイト目に0x00を出力していましたが、3バイトをすべて出力するようになりました。
(19) Nタイプへの変換時のパディングオーバーフロー
|
|
Nタイプへ変換する際、入力側のバイト数より出力側のバイト数が多い場合は全角スペースがパディングされます。入力側と出力側のバイト数の差が奇数のとき、全角スペースの1バイト目まで出力して正常終了していましたが、エラーとなるように変更されました。
(20) Nタイプ変換で連続する半角スペースの変換方法
|
|
入力または出力にNタイプが指定されている変換で、入力データに半角スペースが2個連続した場合の変換方法が変更されました。
- (1)入力データがUTF-16の場合
-
デフォルトコード2個(初期値では"□□")に変換されていましたが、全角スペース1個に変換されるようになりました。
- (2)入力データがEUCまたはSJISで、出力データがUTF-16の場合
-
デフォルトコード(初期値では"□")に変換されていましたが、全角スペース1個に変換されるようになりました。
(21) 入力ファイル設定のUnicodeテーブル
|
|
パラメータファイルの入力ファイル設定で、Unicodeテーブルは指定できなくなりました。常に出力ファイル設定の「Unicodeテーブル」が使用されます。
(22) マルチフォーマットへの変換で、マッピングしていない項目の扱いの変更
|
|
マルチフォーマットへの変換で、入力側の項目とマッピングされていない出力側項目は、従来は出力されていませんでしたが、項目タイプに応じた初期値を出力するようになりました。
項目タイプの初期値については「(11) 固定フォーマットへの変換で、マッピングしていない項目の扱いの変更」を参照してください。
従来のパラメータファイルをそのまま実行した場合、入力側の項目とマッピングされていない出力項目は出力されません。
(23) XML出力での記号の扱い
|
HULFT データ変換Pro/Standardでは、XMLファイル内で予約されている5文字「<」、「>」、「"」、「'」、「&」をそのまま出力していましたが、HULFT-DataMagicでは以下のように変換して出力するよう変更しました。
- 「<」
-
: <
- 「>」
-
: >
- 「"」
-
: "
- 「'」
-
: '
- 「&」
-
: &
(24) 出力がUTF-16の場合の外字テーブル中の奇数バイト文字の変換
|
出力側がUTF-16で、外字テーブルの出力コードに奇数バイト文字(1バイト、3バイト)が登録されていた場合、従来はそのまま出力していましたが、1バイト目に0x00を付加して偶数バイトで出力するようになりました。
(25) HULFT Manager接続
|
HULFT-DataMagic for UNIX/Linuxへの接続がHULFT Managerから製品にバンドルされたHULFT-DataMagic Connectに変更されました。Ver.1.1以降のHULFT-DataMagicへはHULFT-DataMagic Connectを使用してください。
(26) XML数値データの +(プラス)記号を含むデータの出力
|
XML数値データの「+」(プラス)記号を含むデータから「項目タイプ」"9"、"M"、"P"、"S"、または"X"への出力が「+」(プラス)記号をそのまま出力していましたが、出力しないよう変更されました。
表B.2 +(プラス)記号を含むデータの出力
|
入力項目タイプ |
||
|---|---|---|
|
XML数値データ |
+2 |
|
|
出力項目タイプ(4バイト) |
||
|
|
Ver.1.0.1未満 |
Ver.1.1.0 |
|
9 |
0x30 30 2B 32 |
0x30 30 30 32 |
|
M |
0x2B 32 20 20 |
0x32 20 20 20 |
|
P |
0x00 00 FB 24 |
0x00 00 00 24 |
|
S |
0x30 30 2B 42 |
0x30 30 30 42 |
|
X |
0x2B 32 20 20 |
0x32 20 20 20 |
|
*1 |
: |
「ゾーン符号」="3"、「出力時外部符号(正)」="4"、「出力時内部符号(正)」="4"の場合 |
(27) 抽出条件でIタイプの項目を使用した変換
|
抽出条件にIタイプの項目を指定した場合、従来は正常終了していましたが(ただし抽出なし)、実行時にエラーになるよう変更されました。
エラーコードおよびメッセージについては、「エラーコード・メッセージ」を参照してください。
(28) EBCDIC ASPEN (0x57)→UTF-8(0xA0)の変換
|
EBCDIC ASPENの0x57をUTF-8へ変換する場合、これまで0xA0に変換していましたが、0x20に変換します。
(29) EBCDIC ASPEN (0x57)⇔UTF-16(0x00A0)の変換
|
EBCDIC ASPENの0x57をUTF-16へ変換する場合、これまで0x00A0に変換していましたが0x0020に変換します。また、UTF-16の0x00A0をEBCDIC ASPENへ変換する場合、これまで0x57に変換していましたが0x40に変換します。
(30) KEISシフトコード内の半角スペースの扱いの変更
|
漢字コード種がKEISである入力ファイルを変換する場合の動作が変更されました。従来はデータ中のシフトコード内に奇数個の半角スペースがあった場合、単一半角スペースが次の文字と結びつけて変換されていました。そのため、シフトアウトコードが検知されないで外字として変換されていました。
従来の変換処理の例を次に示します。
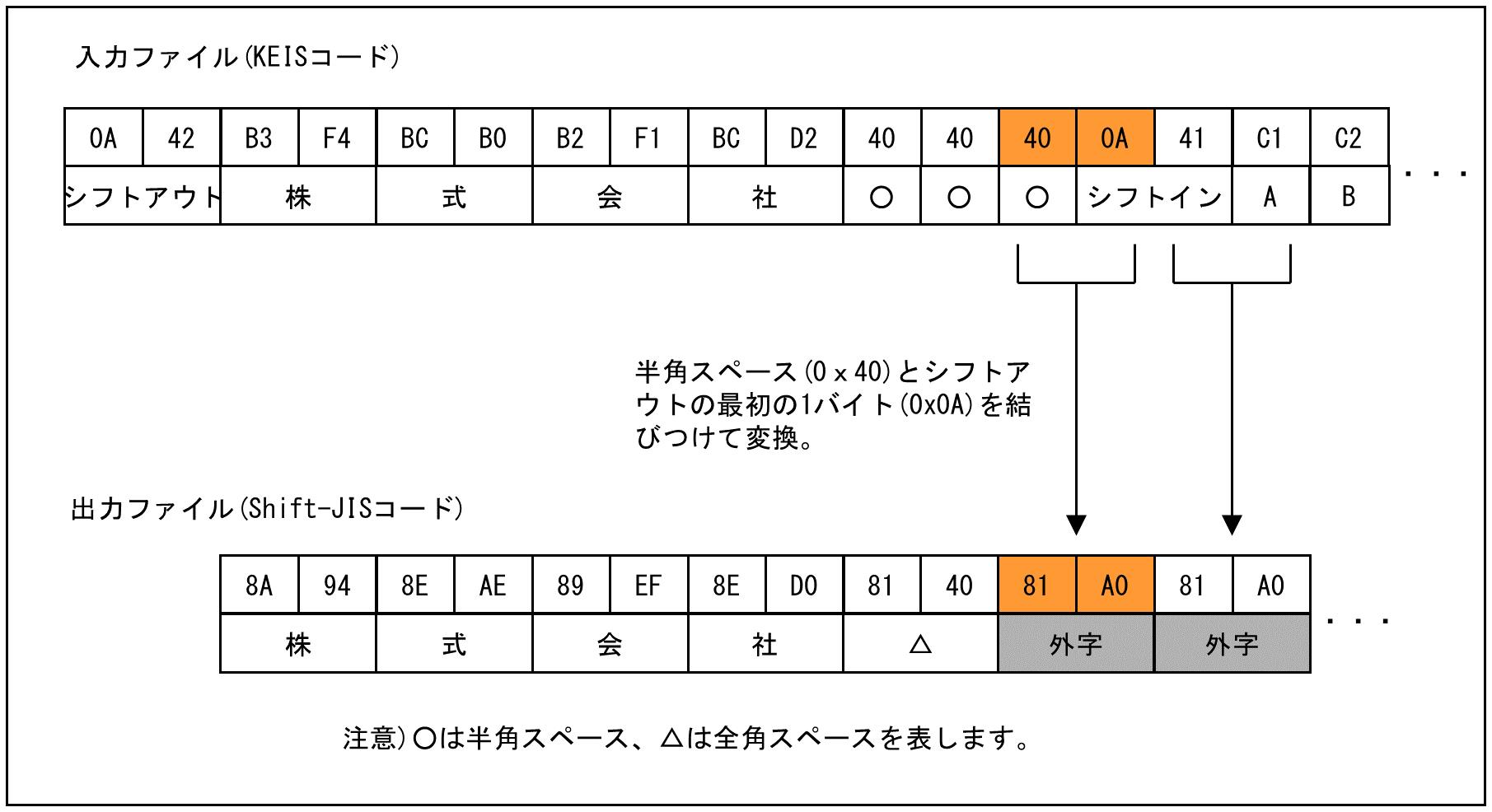
Ver.1.2.0以降では、奇数個あるうちの単一半角スペースを、そのまま半角スペースとして変換するようになりました。そのため、シフトアウトコードを検知して変換できるようになりました。
Ver.1.2.0以降での処理の例を次に示します。
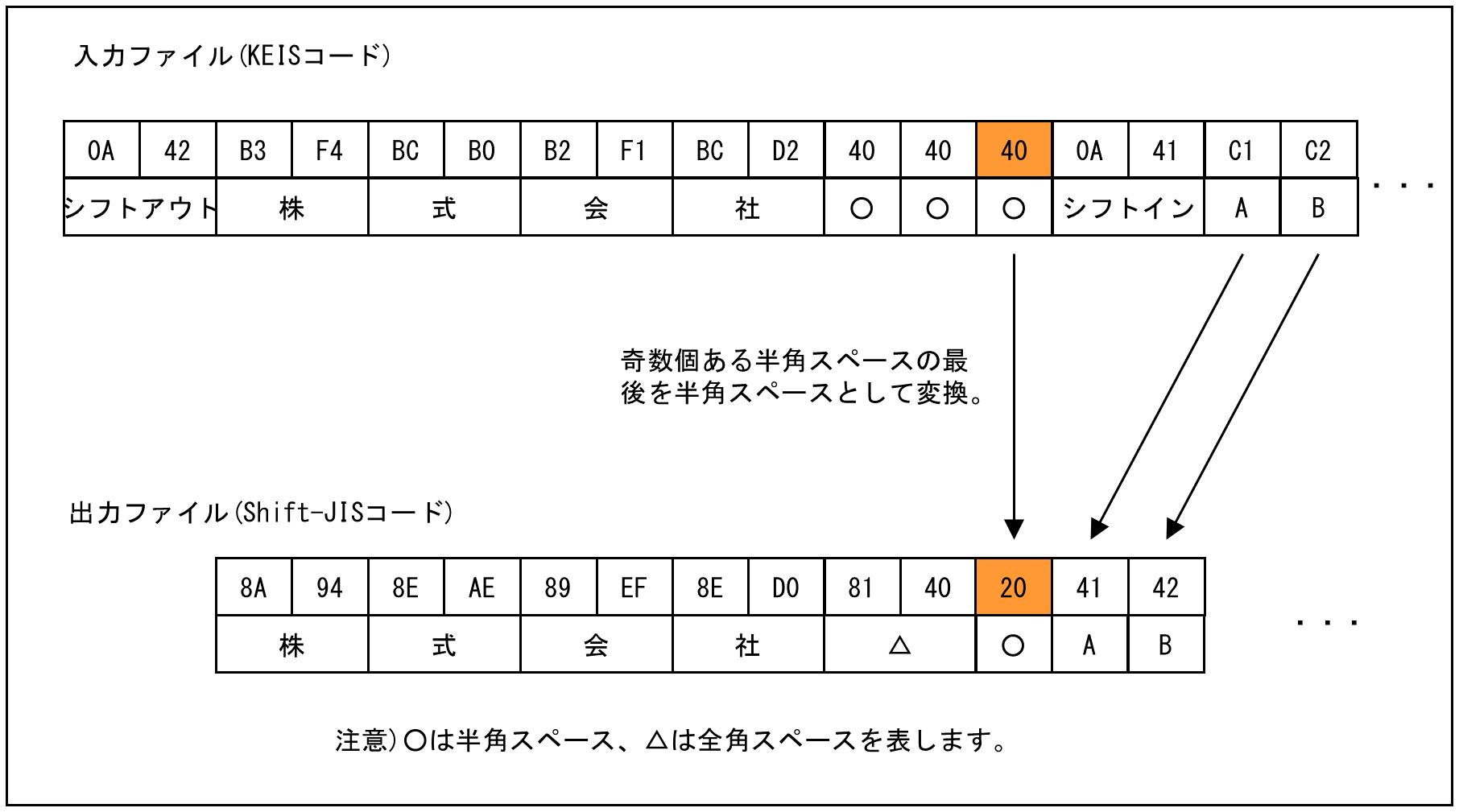
なお、従来の動作で変換したい場合は、環境ファイルの[下位互換]タブで"下位互換をとる"を選択してください。
(31) Oracle Instant Client利用方法の変更(Linux版のみ)
|
Oracle Instant Clientを利用するために、Oracleソフトウェアライブラリディレクトリにシンボリックリンクを作成する作業が必要になりました。
(32) マッチング機能 数値タイプの判定の変更
|
数値タイプのマッチング条件の場合、従来は数値の整数部が一致しているかどうかだけが判定されていました。Ver.1.2.0以降では、小数部についても判定されるようになりました。
(33) ソート機能によるソートキー値判定の変更
|
入力ファイルソート指定時のソートキー判定値が、下記の表のとおりに変更されました。
表B.3 入力ファイルソート指定時のソートキー判定値
固定FMT形式
|
|
Ver.1.2.0未満 |
Ver.1.2.0以降 |
|||||
|---|---|---|---|---|---|---|---|
|
値なし |
半角スペース |
全角スペース |
値なし |
半角スペース |
全角スペース |
||
|
比較 |
数値 |
0 |
0 |
変換エラー |
最大値 |
最大値 |
変換エラー |
|
文字 |
最小値 |
半角スペース |
全角スペース |
最大値 |
半角スペース |
全角スペース |
|
|
日付 |
変換実行日時 |
変換実行日時 |
変換実行日時 |
最大値 |
最大値 |
最大値 |
|
|
*1 |
: |
X、M、Dタイプの場合 |
|
*2 |
: |
M、N、Dタイプの場合 |
CSV形式
|
|
Ver.1.2.0未満 |
Ver.1.2.0以降 |
|||||
|---|---|---|---|---|---|---|---|
|
値なし |
半角スペース |
全角スペース |
値なし |
半角スペース |
全角スペース |
||
|
比較 |
数値 |
変換エラー |
0 |
変換エラー |
最大値 |
最大値 |
変換エラー |
|
文字 |
最小値 |
半角スペース |
全角スペース |
最大値 |
半角スペース |
全角スペース |
|
|
日付 |
変換実行日時 |
変換実行日時 |
変換実行日時 |
最大値 |
最大値 |
最大値 |
|
(34) UTF-16の0xD800~0xDBFF、0xDC00~0xDFFF文字の変換
|
従来、UTF-16の0xD800~0xDBFF、0xDC00~0xDFFF領域の文字は2バイト文字として外字変換していました。Ver.1.2.0以降では、連続する4バイトの上位2バイト0xD800~0xDBFF、下位2バイト0xDC00~0xDFFFの文字が入力された場合、4バイトを1文字として外字変換します(サロゲートペアに対応したため)。
(35) 小数点で始まる入力データの処理
|
従来、小数点で始まる文字データを数値データへ変換しようとした場合、変換エラーとしていましたが、正常に変換できるようになりました。
例) .123 → 0.123
(36) huledpro.iniのインストール先変更
|
huledpro.iniのインストール先が「%windir%」から「インストールフォルダ」に変更されました。
(37) 1000項目以上のデータが入力ファイルにある場合の処理
|
入力区分が"CSV"でIDなし指定の場合、1レコード1000項目以上のデータが入力された場合、変換エラーとなるよう変更されました。(「完了コード」=43、「詳細コード」=51)