Parallel Stream Processing (PSP) is the mechanism which enables efficient mass data processing with low memory usage in DataSpider Servista.
PSP has the following features.
Lowering the memory usage
Executes the "loading"-"converting"-"writing" processes each 1000 case, without keeping all the input data into memories.
Therefore this enables effective mass data processing without requiring massive memories.
Handling large volume data
Processes input data without keeping in the memories, and thus has no limit in the data capacity theoretically.
Enhancing performances
Processing the "loading"-"converting"-"writing" processes in order, makes the utilization of CPU resources ineffective.
Using PSP will distribute each "loading", "converting", "writing" process and enables to operate in multithread. Therefore even upon the condition a process is waiting I/O, you can execute processes, such as conversion, simultaneously in other threads.
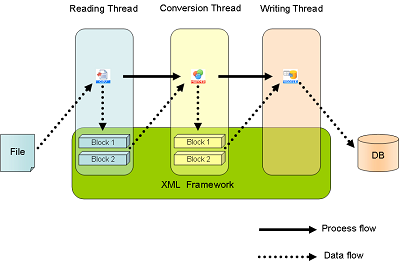
An architectural diagram of a Parallel Stream Processing
PSP runs the following architecture.PSP allocates dedicated threads for each read, transform, and write operation that occurs during data transferring.
As described in the diagram above, there are 2 internal buffers for each of the read and the transform component which produces data to be consumed by the subsequent write component in the process flow.
Components generating result data execute writing process upon detection of a block in write-available condition (data consuming condition). Upon in the condition of not detecting a write-available block (data not consuming condition), waits the process.
Components using result data (in the diagram above, Converting process and Writing process), begins processing upon detection of a block in load-available condition (data creation completed condition), into the result data of a component in the input source. Upon in the condition of not detecting a load-available block (data creation not completed condition), waits the process.
Process flow
In the following sections, each of the read, the transform, and the write operation in the diagram above is explained in detail.
The data traversed from the read operation to the write operation is represented by the rectangular strips labeled 'data a', 'data b', and 'data c' each identifiable by their color.
Step 1: Before the process
Data a: not read by the component.
Data b: not read by the component
Data c: not read by the component
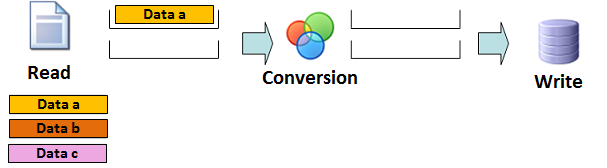
Step 2: Reading the 'data a'
Data a: read by the read component and stored to its internal buffer.
Data b: not read by the component
Data c: not read by the component
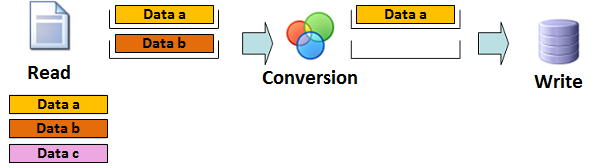
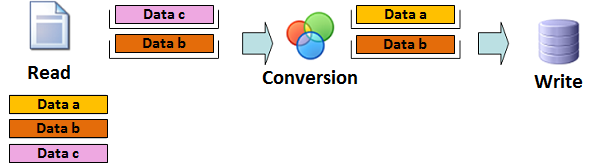
Step 3: Reading the 'data b' and transforming the 'data a'
Data a: transformed by the transformer component and stored to its buffer.
Data b: read by the read component and stored to its internal buffer.
Data c: not read by the component
the data in all three stages are processed parallel.
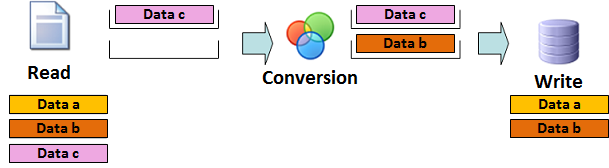
Step 4: Reading the 'data c', transforming the 'data b', and writing the 'data a'
Data a: The write operation of the data is performed and the buffer is cleared.
Data b: transformed by the transformer component and stored to its buffer.
Data c: read by the read component and stored to its internal buffer.
the data in all three stages are processed parallel.
Step 5:Transforming 'data c' and writing the 'data b'
Data a: The process completed at step 4
Data b: The write operation of the data is performed and and the buffer is cleared.
Data c: transformed by the transformer component and stored to its buffer.
the data in all three stages are processed parallel.
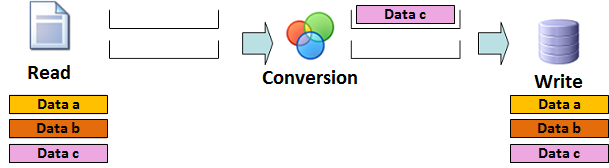
Step 6: Writing the 'data c'
Data a: The process completed at step 4
Data b: The process completed at step 5
data c: The write operation of the data is performed and the buffer is cleared. and the buffer is cleared.
the data in all three stages are processed parallel.
Handling the data at each operational stage by its dedicated thread realizes the processing of a large volume data at an optimal speed.
Smart Compiler applies PSP automatically distinguishing the script contents.
Therefore, you can basically create scripts without being aware of PSP.
For details, please refer to "Smart Compiler".
For components and Mapper logics that correspond to PSP, please refer to Help.
For component operations that correspond to PSP, please refer to each operation page.
For Mapper logics that correspond to PSP, please refer to "Mapper logic list".
The details about the thread coordination in PSP mechanism is as follows:
In PSP, the number of the producer thread generated equals to the number of the processing components which retrieve data from their associated resources, and the thread that consumes the data in the bounded buffer of the each processing component is the same thread as the thread executing the script.
The total number of additional thread generated in a process flow comprised of "Read"-"Conversion"-"Write" is 3.
The total number of additional thread generated in a process flow comprised of "Read"-"Conversion"-"Conversion"-"Write" is 4.
If a transaction is started, the component executing with PSP belongs to that transaction.
If a transaction is not started, component executed in PSP will start a transaction for exclusive use.
Therefore, multiple componets using same global resources will exist and if any of them execute by PSP, it will use separate connections.
In PSP, you cannot specify the result data to the input source of multiple components.
In the case of mapping from an input document to a variable, this also means specification to input source.
About errors
In PSP, an error occurred in loading or converting components is processed as an error in writing component. For details on error contents, please refer to Message code in PSP category.
In PSP, an error occurred in loading or converting components is not processed as an error, if a component that treats variable component as input source does not exist.
For instance, despite of an error occurrence in the loading component with PSP, the script succeeds and the error message is not output to Logs.
Between a loading component executing in PSP and a writing component, operating the targeted file is not available.
In PSP, some part of component variables are not available. For details, please refer to Help of each operation.
In PSP, a thread is created upon execution of a component that creates result data.
Buffer size cannot be changed externally.
You can configure schemas in Mapper by "Load schema" and you can only configure the schemas as "Table Model type".
If you configure the schemas as XML type, allocating memory is needed when large data is input.The "XML type" is not supported in PSP.
 the data in all three stages are processed parallel.
the data in all three stages are processed parallel.
 For details, please refer to "Smart Compiler".
For details, please refer to "Smart Compiler".