REPLACE_REG function
Function
REPLACE_REG{PATTERN,REPLACEMENT}
If the data processed by the function contains the value specified for argument PATTERN, this function replaces instances of the character string specified for argument PATTERN with the character string specified for argument REPLACEMENT, and returns the value. Regular expressions can be used in the arguments. An array can be used in arguments PATTERN and REPLACEMENT, but if the numbers of elements in the respective arrays are not the same, the function results in an error when executed.
-
If the encoding of the input data is EBCDIC or JIS, external characters cannot be used because replacement is performed after changing the encoding to UTF-8.
The encoding is first changed to UTF-8 even when nothing matches with PATTERN (character string to be searched for), or also when hexadecimal notation is used for PATTERN (character string to be searched for). Operations are not guaranteed if any platform-dependent character is included.
-
Operation is not guaranteed if the encoding of the input data is SHIFT-JIS, EUC, UTF-16, or UTF-8, and the encoding of the output data is EBCDIC type or JIS. If this is the case, use SAISON_REPLACE_HEX.
-
For behavior specifications related to encoding differences in the input data, see Behavior specifications related to encoding differences in the input data.
Parameters
PATTERN
Specify the character string to be searched for. (This parameter cannot be omitted.)
REPLACEMENT
Specify the character string used for replacement. (This parameter cannot be omitted.)
You cannot use any hexadecimal numbers when specifying the character string.
The REPLACE_REG function performs pattern match using regular expressions and replaces the character string that matches the pattern.
A regular expression is used to express a character string pattern. For example, supposing there were four character strings, ABCD, Abcd, AAAA and AXYZ, they all match the pattern of a 4-letter character string starting with A. These character strings are presented as ^A... if you use regular expressions.
Typical meta characters that can be used in regular expressions are listed below. Meta characters are characters that have special meanings in regular expressions.
Table A.11 Regular expressions that can be used with the REPLACE_REG function
|
Element |
Notation |
Description |
Example |
|
|---|---|---|---|---|
|
Basic elements |
\ escape modifier |
Controls the validity (enabled/disabled) of regular expression symbols |
\\ |
Matches \ |
|
| |
Options |
a|b |
Matches a or b |
|
|
(…) |
Group |
(abc)+ |
Matches abcabcabc, etc. |
|
|
[character set] |
Character class |
[TN]ext |
Matches Text and Next |
|
|
Characters |
\t |
Tab |
a\tb |
Matches at abb |
|
\n |
Line break |
abc\n |
Matches abcline-break |
|
|
\r |
Return |
abc\r |
Matches abcline-break |
|
|
\xnn |
Characters in hexadecimal notation nn: hexadecimal notation |
a\x20b |
Matches ahalfwidth-spaceb. |
|
|
Character encoding |
. |
Custom |
a...b |
Matches any character string of 5 bytes in length that starts with a and ends with b |
|
\w |
Word-constituent character |
a\wb |
Matches a_b, a1b, etc. Same as [a-zA-Z_0-9] |
|
|
\s |
Blank character |
a\sb |
Matches aline-breakb, atabb, etc. |
|
|
\S |
Non-white character |
a\Sb |
Matches acb, adb, etc. |
|
|
\d |
Decimal character |
\d\d |
Matches 2-digit strings that use numbers from 0 to 9, such as 12 and 34 |
|
|
\D |
Non-decimal character |
\D\D |
Matches 2-digit strings that do not use numbers from 0 to 9, such as AB and XX |
|
|
\h |
Hexadecimal character |
\h\h |
Matches 2-digit strings that use numbers from 0 to 9 and characters from A to F, such as 1A and B9 |
|
|
\H |
Non-hexadecimal character |
\H\H |
Matches 2-digit strings that do not use numbers from 0 to 9 or characters from A to F, such as GH and XX |
|
|
Repetition quantifiers |
? |
1 or 0 time |
abc? |
Matches ab or abc |
|
* |
0 or more times |
abc* |
Matches ab, abc, abccc, zab, zabc, etc. |
|
|
+ |
1 or more times |
abc+ |
Matches abc and abccc but not ab |
|
|
{n,m} |
n,m: Number n or more times but equal to or fewer than m time(s) |
abc{2,3} |
Matches abcc and abccc |
|
|
{n,} |
n: Number n or more times |
abc{2,} |
Matches abcc, abccc, and abcccccc |
|
|
{,n} |
n: Number 0 or more times but equal to or fewer than n time(s) |
abc{,2} |
Matches ab, abc, and abcc |
|
|
{n} |
n: Number n times |
abc{2} |
Matches abcc |
|
|
Anchors |
^ |
Line head |
^a |
Matches character strings starting with a |
|
$ |
End of line |
a$ |
Matches character strings ending with a |
|
|
\b |
Word boundary |
\babc\b |
Matches abc but not abcd |
|
|
Character set |
^… |
Negation |
[^a] |
Matches characters other than a |
|
x-y |
Range |
[a-z] |
Matches lowercase letters |
|
|
Back reference |
\n |
Used in replacement characters n: Number |
a(.*?)b |
In the case of \1, for example, reads any character string between a and b |
|
$n |
a(.*?)b |
In the case of $1, for example, reads any character string between a and b |
||
-
Notes on using reserved symbols in an argument of a function
Basically, when you use one of the reserved symbols, comma (,), left curly bracket ({), right curly bracket (}), or slash (/), in an argument of a function, insert a backslash (\) as the escape character.
However, if either of the following conditions is met, do not insert an escape character even when a comma (,), left curly bracket ({), or right curly bracket (}) is contained in the argument. In such a case, if you use the escape character, data processing is not performed correctly. (Note that, in the case of a slash (/), the escape character is necessary.)
-
An argument is specified to contain a variable [$DSTRXX] that is dynamically substituted with a value
-
-
Notes on using "\s" to replace line break codes
If the input data is CSV, enable "Treat a line break as part of a field" and use enclosure characters.
Example
This example replaces the character string い with き.
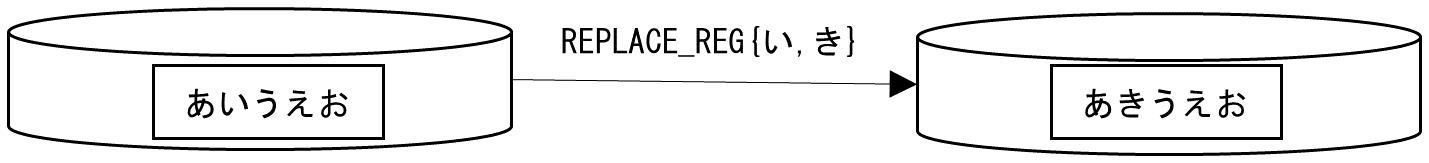
Figure A.28 Example of using the REPLACE_REG function
For an example that uses a regular expression for an argument, see Example of using the REPLACE_REG function.
Behavior specifications related to encoding differences in the input data
When the encoding of the input data is EBCDIC type or JIS
The description of this section is based on the case shown below. The following data is expressed in hexadecimal.
|
Kanji code type in the input settings |
JEF |
|
EBCDIC set in the input settings |
EBCDIC kana |
|
Kanji code type in the output settings |
JEF |
|
EBCDIC set in the output settings |
EBCDIC kana |
|
Input data |
40 20 40 9C 01 20 10 9C |
|
Field type of the input data |
X (character) |
|
Function |
REPLACE_REG{\x20\x10\x20,ABC} |
1) Before REPLACE_REG is executed, the input character string is converted to UTF-8.

Figure A.29 Converting to UTF-8
"0x40" (space) and "0x9C" (code that is unable to be converted to UTF-8) are converted to "0x20".
2) REPLACE_REG is executed on the data converted to UTF-8.

Figure A.30 Executing REPLACE_REG
"20 10 20" is replaced with "41 42 43" (character string "ABC" in UTF-8).
3) All target data of REPLACE_REG is converted to the JEF/EBCDIC set based on the output settings.

Figure A.31 Converting to the JEF/EBCDIC set based on the output settings
"41 42 43" (character string "ABC" in UTF-8) is converted to "C1 C2 C3" (character string "ABC" in EBCDIC).
Because 0x20 in the input data represents a space in UTF-8, the code value is converted to 0x40 when the conversion to EBCDIC is executed in step 3.
For data that is unable to be converted to UTF-8 such as 0x9C, the original code values cannot be retained after replacement with REPLACE_REG.
If the encoding of the input data is EBCDIC type or JIS, and the original code values need to be retained after replacement, use the common component SAISON_REPLACE_HEX.
When the encoding of the input data is SHIFT-JIS, EUC, UTF-16, or UTF-8
The description of this section is based on the case shown below. The following data is expressed in hexadecimal.
|
Kanji code type in the input settings |
EUC |
|
Kanji code type in the output settings |
SHIFT-JIS |
|
Input data |
40 20 40 9C 01 20 10 9C |
|
Field type of the input data |
M (variable-length characters) |
|
Function |
REPLACE_REG{\x20\x10\x9C,あいう} |
1) REPLACE_REG is executed on the input data.
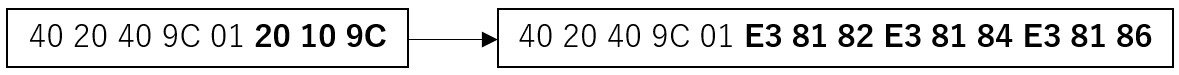
Figure A.32 Executing REPLACE_REG
"20 10 9C" is converted to "E3 81 82 E3 81 84 E3 81 86" (character string "あいう" in UTF-8). Only the replacement characters are targeted for conversion.
2) The UTF-8 data replaced using REPLACE_REG is converted to SHIFT-JIS based on the output settings.

Figure A.33 Converting to SHIFT-JIS based on the output settings
"E3 81 82 E3 81 84 E3 81 86" (character string "あいう" in UTF-8) is converted to "82 A0 82 A2 82 A4" (character string "あいう" in SHIFT-JIS).
Characters other than the replacement characters are converted based on the Kanji code type specified in the output settings.