Combination and division of character type data
Conversions that use the following kanji code types are explained below, by taking examples of conversion results for each character type and the treatment of the shift code. The number of bytes for the shift code varies depending on the kanji code type. In the example, the shift code is handled as 1 byte.
-
Input kanji code type: JEF, IBM kanji, KEIS, NEC kanji
-
Output kanji code type: JEF, IBM kanji, KEIS, NEC kanji
Kanji encoding types can be specified only in DataMagic Server. You cannot specify kanji encoding types in DataMagic Desktop.
When dividing (extracting) a character type code, if the division (extraction) starts from the middle of a kanji code, no error is generated and the division (extraction) is made from the middle of the code. As a result, the code after the division (extraction) may be garbled.
(1) Division of type N data
This is an example of extracting type N data and converting it to type M.
Set the data extraction information in Output Information Settings of the output data in the Mapping Settings screen.
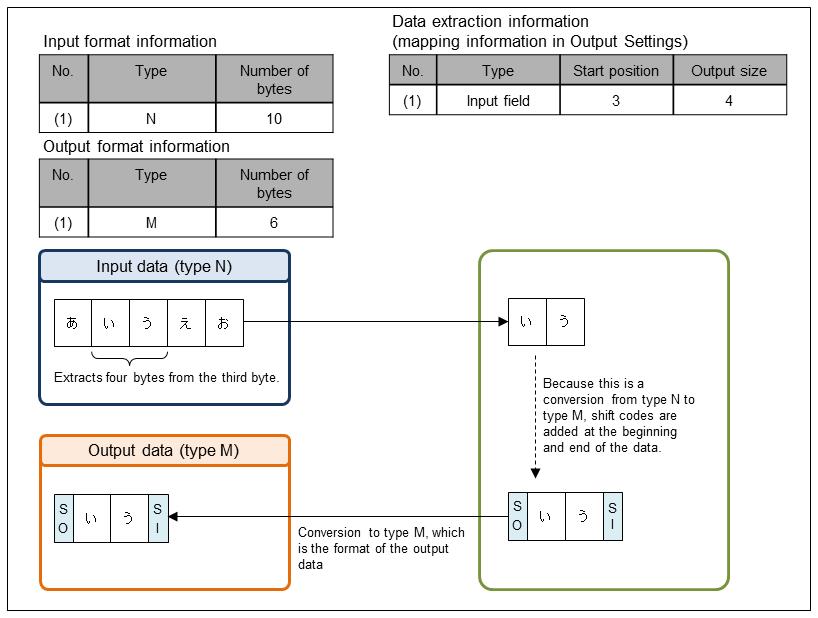
Figure 9.18 Division of type N data
(2) Division and combination of type N data
This is an example of extracting type N data and converting it to type M.
Set the data extraction information in Output Information Settings of the output data in the Mapping Settings screen.
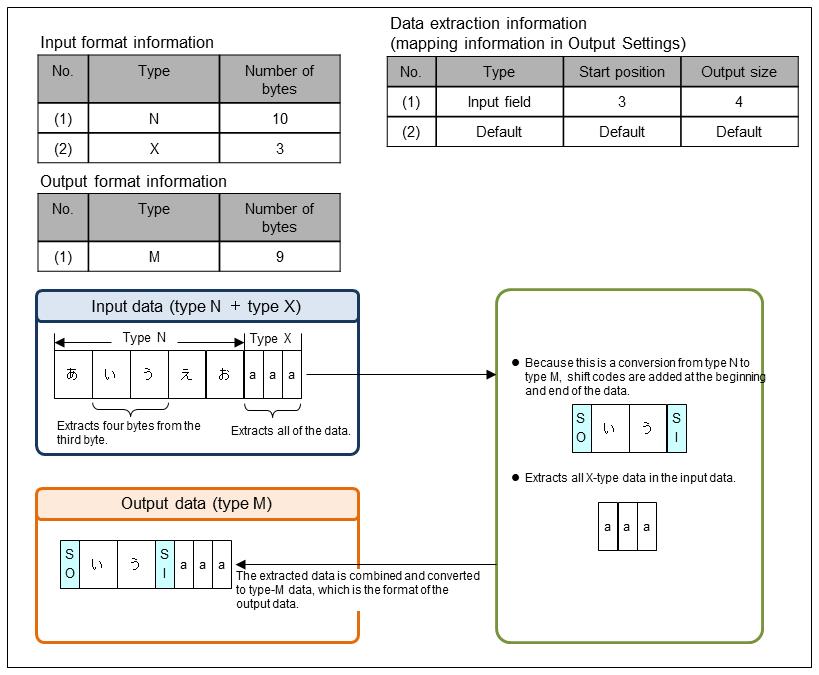
Figure 9.19 Division and combination of type N data
(3) Division and combination of type M data
This is an example of extracting type M data and converting it to type M.
Set the data extraction information in Output Information Settings of the output data in the Mapping Settings screen.
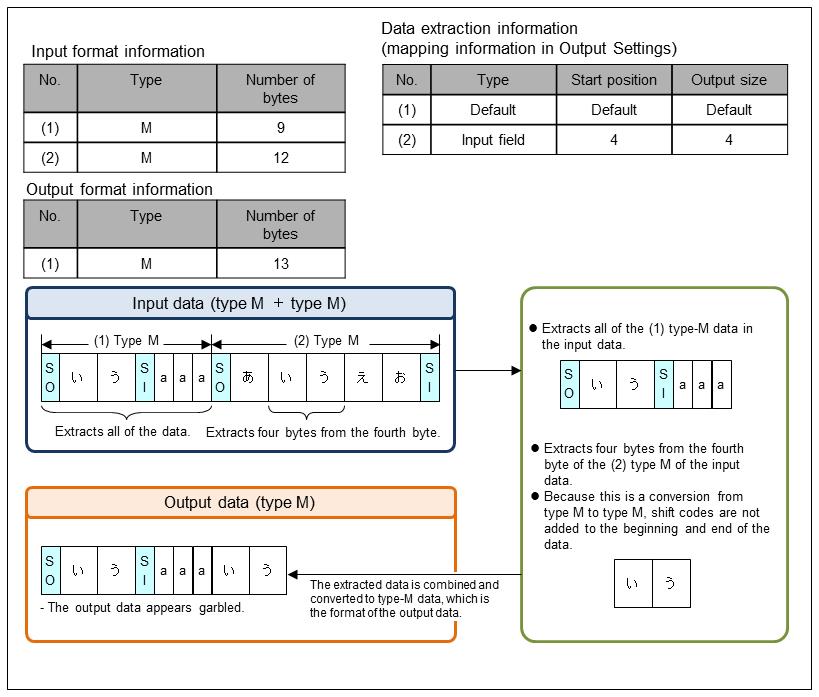
Figure 9.20 Division and combination of type M data
(4) Combination of type M data
This is an example of extracting type M data and converting it to type M.
Set the data extraction information in Output Information Settings of the output data in the Mapping Settings screen.
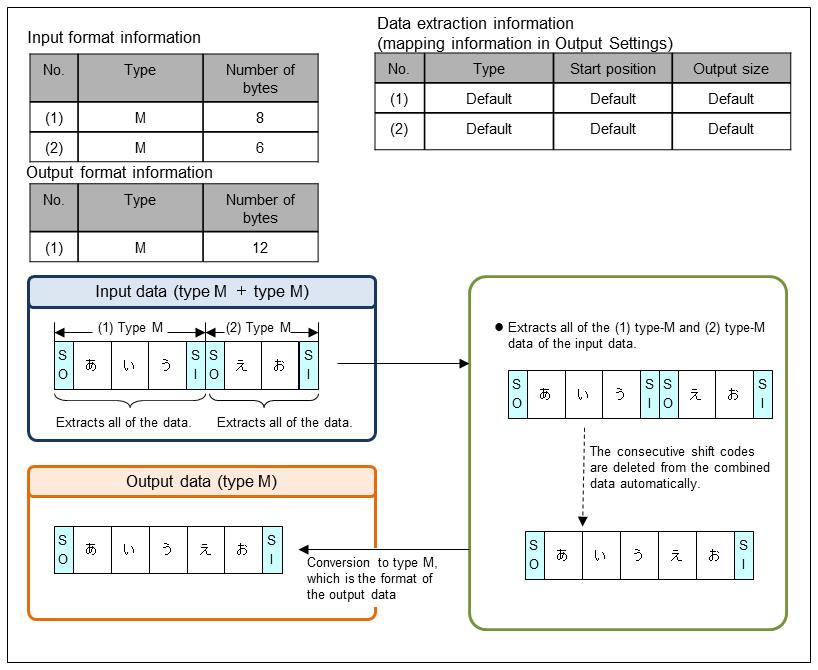
Figure 9.21 Combination of type M data