Handling of XML record unit at the input side
If the input file is XML, the file is delimited into records based on the XML record unit of the input file settings.
Taking as an example the following schema file, XML information, and input file, this section describes the details for each value of the XML record unit setting.choice is used for the contents model of the schema file.

Figure 4.10 Schema file
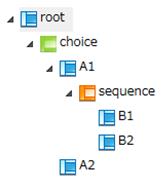
Screen 4.8 XML information tree

Figure 4.11 Input file
(1) If the XML record unit is "1"
The element at the level of the root is considered to be one record, so the element that is recognized as one record is root. Only one root element exists for each file, so all data in the input file is handled as one record. Therefore, in this case, data1 to data7 are processed as one record.
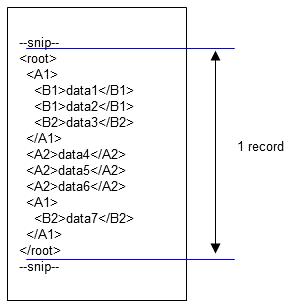
Figure 4.12 One record
(2) If the XML record unit is "2"
Each element just below the root element is considered to be one record, so the elements that are recognized as one record are A1 to A2. Data is processed in descending order within the level that is considered to be one record, and when an element of the same name is found, the process moves to the next record. In this example, records are separated as follows:
1. The data is processed in descending order, and the second A2 occurs at <A2>data5</A2>. At this time, data1 to data4 become the input data of the first record, and data5 and thereafter are processed as the second record.
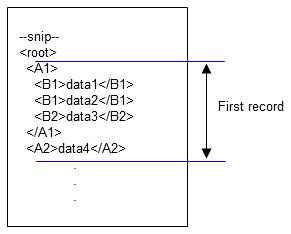
Figure 4.13 First record
2. The third A2 occurs at <A2>data6</A2>, so data5 becomes the input data of the second record, and data6 and thereafter are processed as the third record.
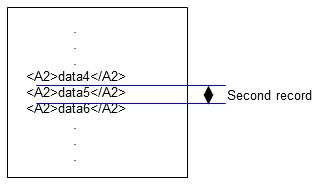
Figure 4.14 Second record
3. The third record does not contain multiple elements with the same name. Therefore, the process proceeds to the end, and data6 to data7 become the input data of the third record.
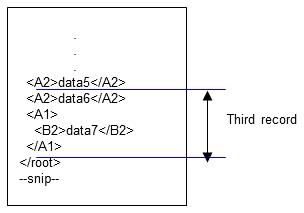
Figure 4.15 Third record
(3) If the XML record unit is "3"
The element that is two levels below the root element is considered to be one record, so the elements that are recognized as one record are B1 to B2. The data is processed in descending order within the level that is considered to be one record, and when an element of the same name is found, the process moves to the next record. In this example, records are separated as follows:
1. The data is processed in descending order, and the second B1 occurs at <B1>data2</B1>. At this time, data1 becomes the input data of the first record, and data2 and thereafter are processed as the second record.
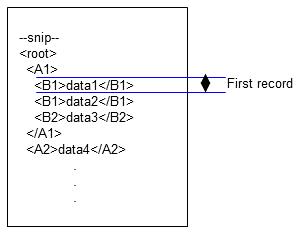
Figure 4.16 First record
2. The second record does not contain multiple elements with the same name. Therefore, the process proceeds to the end, and data2 to data3 become the input data of the second record.
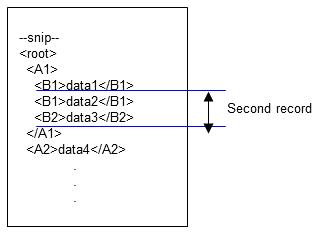
Figure 4.17 Second record
3. When <A2>data4</A2> occurs, the system determines that multiple elements exist just below the root, resulting in an XML record unit consistency error.
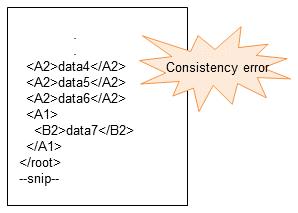
Figure 4.18 Unable to determine the separation of records
If the XML record unit is set to 3, the level just below the root element must contain only one element (<A1> in this case) for the input file not to cause an error, as shown in the figure below.
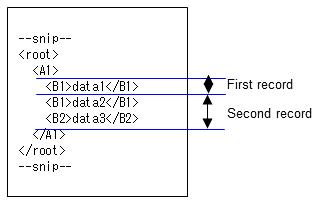
Figure 4.19 Input file
If the XML record unit is set to 3 and the contents model of the XML schema file is sequence, another special caution is necessary. This section describes the details, taking as an example the following schema file, XML information, and input file.

Figure 4.20 Schema file
Screen 4.9 XML information tree

Figure 4.21 Input file 1
In this schema file, two elements (<A1> and <A2>) are defined just below the root, and the contents model is sequence. Therefore, <A1> must be followed by <A2> here (see Contents model).
Looking at the input file, <A1> exists just below the root, followed by <A2>. There is therefore no problem in consistency with the XML schema.
However, if the XML record unit is set to 3, elements of the level that is two levels below the root element are considered to be one record. Therefore, when multiple elements exist just below the root (<A2> in this example), a consistency error occurs.
Therefore, if the XML record unit is set to 3 and you are going to use the sequence contents model in the XML schema, you must include only one element just below the root in the XML schema.
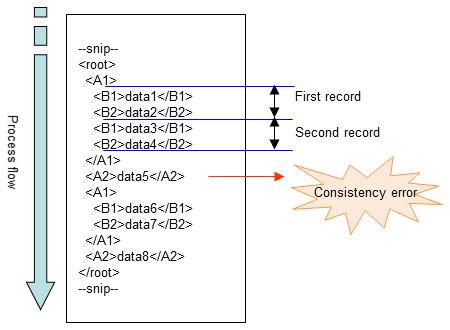
Figure 4.22 Input file 1
(4) If the XML record unit is "Element"
If the XML record unit is Element, data is recognized as a record starting from the point where an element is specified as a condition.
This section describes the details, taking as an example the following schema file, XML information, and input file. sequence is used for the contents model of the schema file.

Figure 4.23 Schema file

Screen 4.10 XML information tree

Figure 4.24 Input file
Records are recognized based on the element that you have set as the extraction condition. In this example, the extraction condition is set for element C1. Therefore, the records are separated as follows:
1. Records are processed in descending order, starting from the first <C1>.<C1> ends just before <A1 AA3="a2">. Therefore, data4 and data5 of c1 and data6 and data7 of c2 become the input data of the first record.
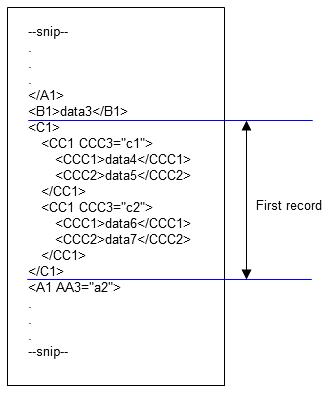
Figure 4.25 First record
2. When the next <C1> occurs, the input data of the second record begins. Processing starts from <CC1 CCC3="c3"> within the second <C1>, and ends at </root>. Therefore, data10 and data11 of c3 and data12 and data13 of c4 become the input data of the second record.
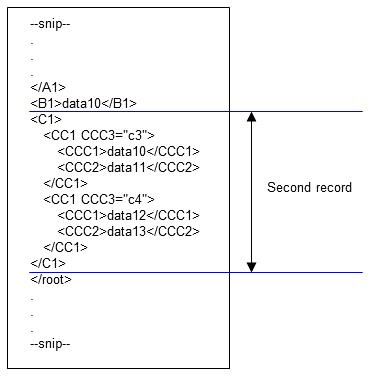
Figure 4.26 Second record
Next, this section describes how to separate records when the extraction condition is set for element CC1.
1. Records are processed in descending order starting from <CC1 CCC3="c1">. The second <CC1> occurs at <CC1 CCC3="c2">, and data4 and data5 are handled as the input data of the first record. The second record is then processed starting from <CC1 CCC3="c2">.
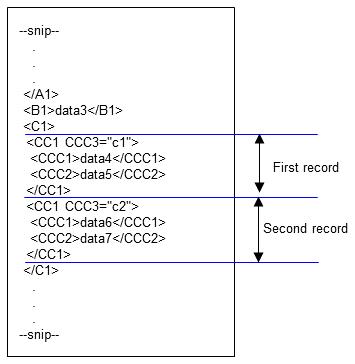
Figure 4.27 First and second records
2. Next, processing continues within <CC1 CCC3="c3">. Records are processed starting from <CC1 CCC3="c3">. The second <CC1> occurs at <CC1 CCC3="c4">, and data10 and data11 are handled as one record. This becomes the third record of the input data. The fourth record is then processed starting from <CC1 CCC3="c4">.
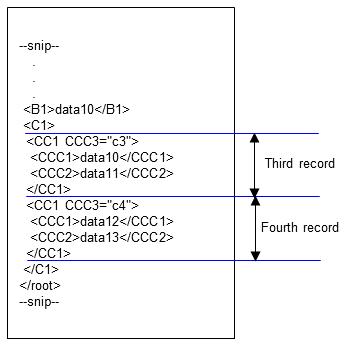
Figure 4.28 Third and fourth records